 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Wikipedia in a fine-grained hierarchy: what graphs can contribute
Jan 22, 2020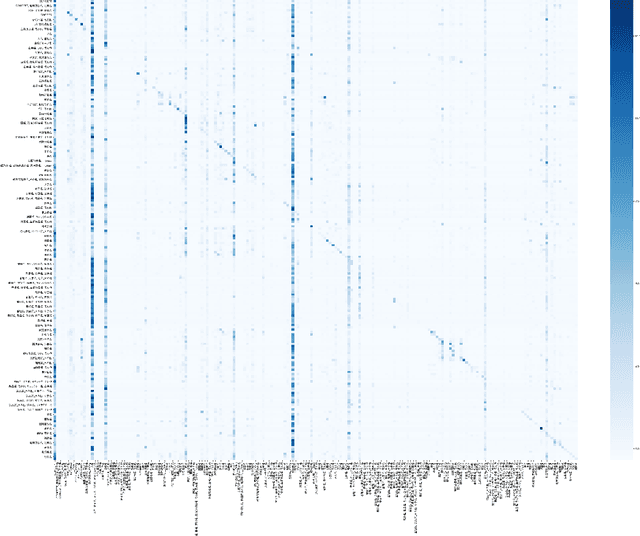
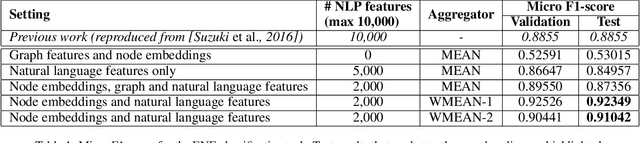
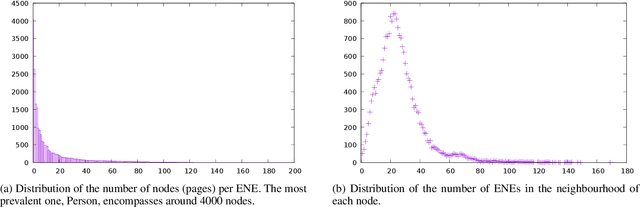
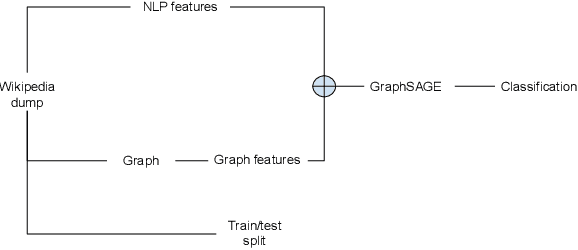
Wikipedia is a huge opportunity for machine learning, being the largest semi-structured base of knowledge available. Because of this, many works examine its contents, and focus on structuring it in order to make it usable in learning tasks, for example by classifying it into an ontology. Beyond its textual contents, Wikipedia also displays a typical graph structure, where pages are linked together through citations. In this paper, we address the task of integrating graph (i.e. structure) information to classify Wikipedia into a fine-grained named entity ontology (NE), the Extended Named Entity hierarchy. To address this task, we first start by assessing the relevance of the graph structure for NE classification. We then explore two directions, one related to feature vectors using graph descriptors commonly used in large-scale network analysis, and one extending flat classification to a weighted model taking into account semantic similarity. We conduct at-scale practical experiments, on a manually labeled subset of 22,000 pages extracted from the Japanese Wikipedia. Our results show that integrating graph information succeeds at reducing sparsity of the input feature space, and yields classification results that are comparable or better than previous works.