 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical analysis of phrase-based and neural machine translation
Mar 04, 2021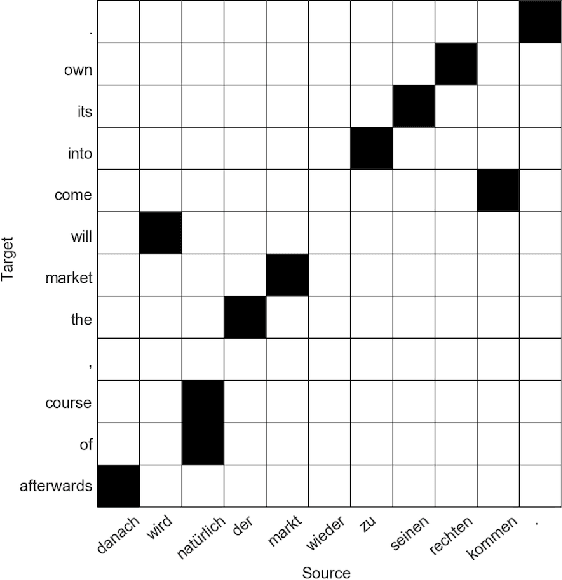
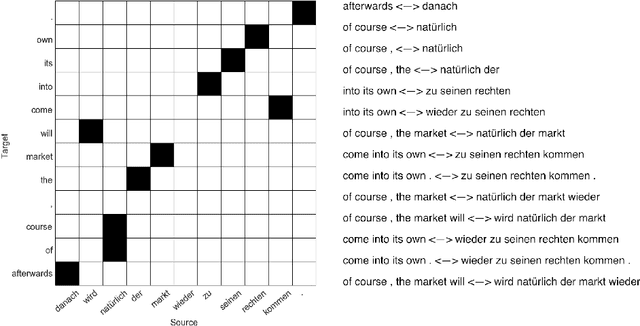
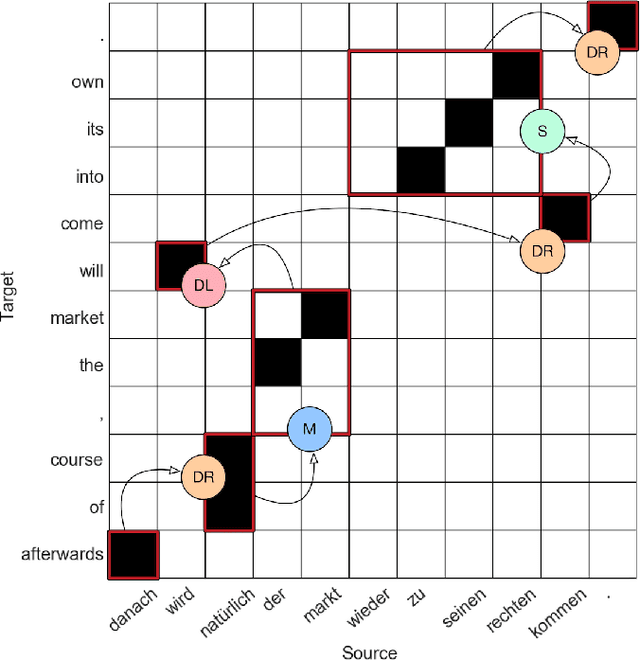
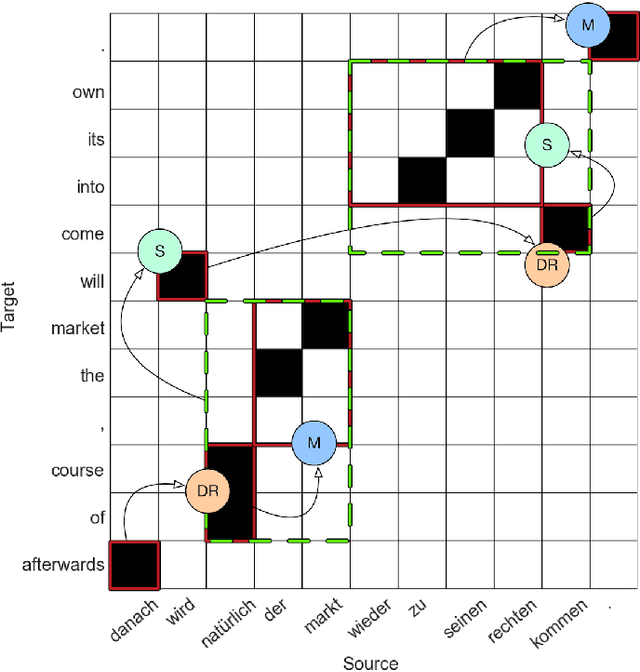
Two popular types of machine translation (MT) are phrase-based and neural machine translation systems. Both of these types of systems are composed of multiple complex models or layers. Each of these models and layers learns different linguistic aspects of the source language. However, for some of these models and layers, it is not clear which linguistic phenomena are learned or how this information is learned. For phrase-based MT systems, it is often clear what information is learned by each model, and the question is rather how this information is learned, especially for its phrase reordering model. For neural machine translation systems, the situation is even more complex, since for many cases it is not exactly clear what information is learned and how it is learned. To shed light on what linguistic phenomena are captured by MT systems, we analyze the behavior of important models in both phrase-based and neural MT systems. We consider phrase reordering models from phrase-based MT systems to investigate which words from inside of a phrase have the biggest impact on defining the phrase reordering behavior. Additionally, to contribute to the interpretability of neural MT systems we study the behavior of the attention model, which is a key component in neural MT systems and the closest model in functionality to phrase reordering models in phrase-based systems. The attention model together with the encoder hidden state representations form the main components to encode source side linguistic information in neural MT. To this end, we also analyze the information captured in the encoder hidden state representations of a neural MT system. We investigate the extent to which syntactic and lexical-semantic information from the source side is captured by hidden state representations of different neural MT architectures.
Classifying Wikipedia in a fine-grained hierarchy: what graphs can contribute
Jan 22, 2020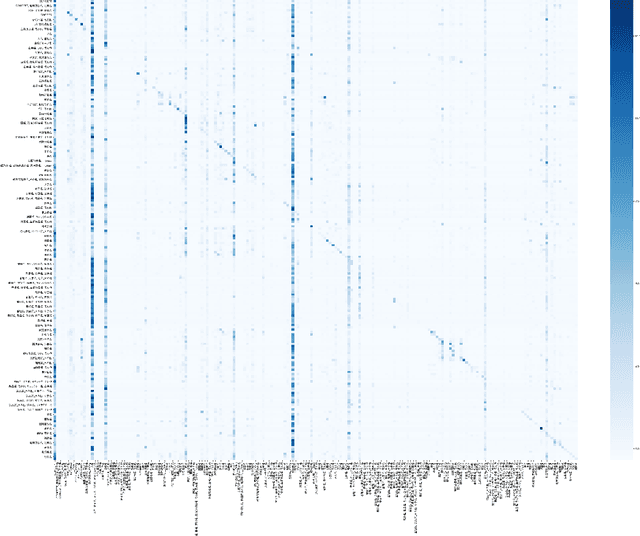
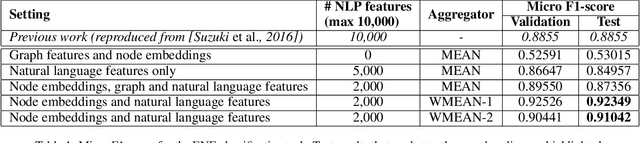
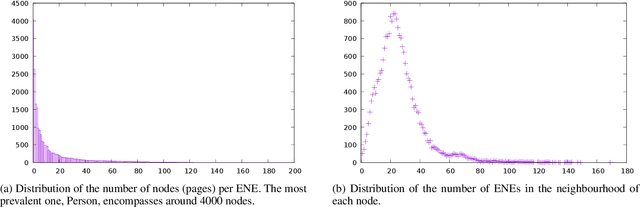
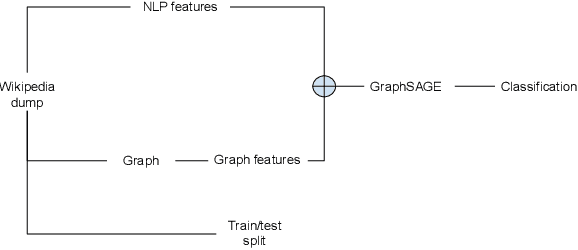
Wikipedia is a huge opportunity for machine learning, being the largest semi-structured base of knowledge available. Because of this, many works examine its contents, and focus on structuring it in order to make it usable in learning tasks, for example by classifying it into an ontology. Beyond its textual contents, Wikipedia also displays a typical graph structure, where pages are linked together through citations. In this paper, we address the task of integrating graph (i.e. structure) information to classify Wikipedia into a fine-grained named entity ontology (NE), the Extended Named Entity hierarchy. To address this task, we first start by assessing the relevance of the graph structure for NE classification. We then explore two directions, one related to feature vectors using graph descriptors commonly used in large-scale network analysis, and one extending flat classification to a weighted model taking into account semantic similarity. We conduct at-scale practical experiments, on a manually labeled subset of 22,000 pages extracted from the Japanese Wikipedia. Our results show that integrating graph information succeeds at reducing sparsity of the input feature space, and yields classification results that are comparable or better than previous works.
An Intrinsic Nearest Neighbor Analysis of Neural Machine Translation Architectures
Jul 08, 2019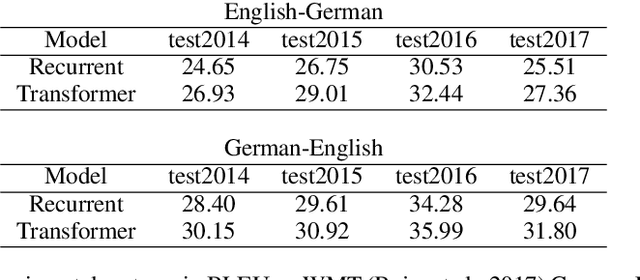
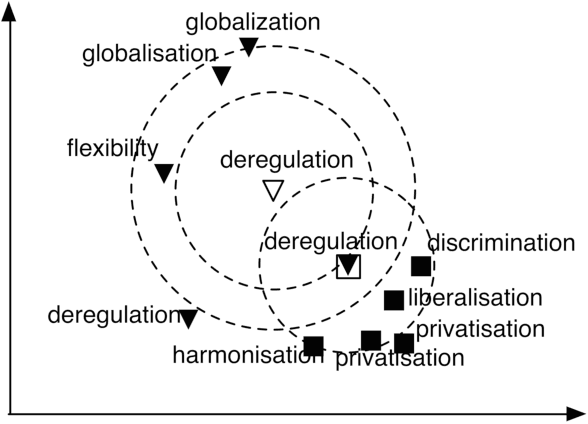
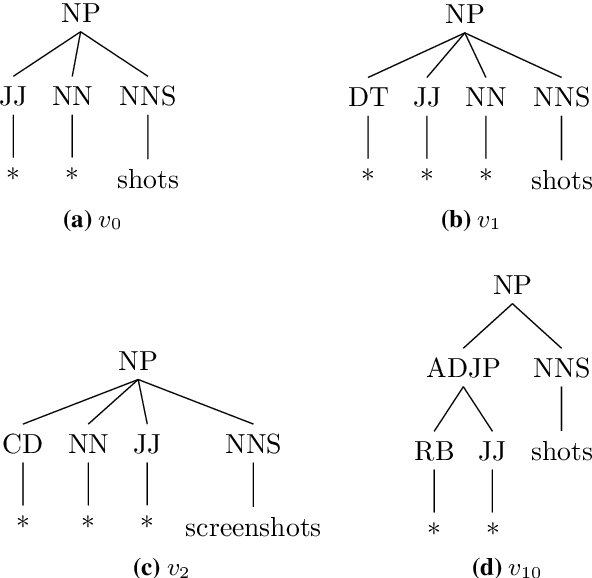
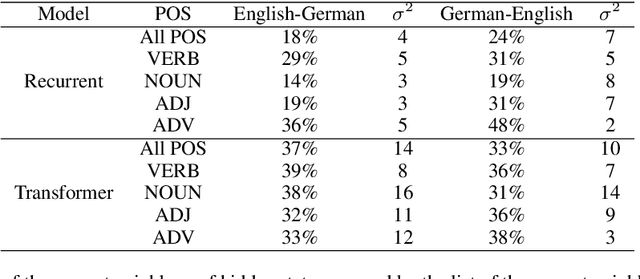
Earlier approaches indirectly studied the information captured by the hidden states of recurrent and non-recurrent neural machine translation models by feeding them into different classifiers. In this paper, we look at the encoder hidden states of both transformer and recurrent machine translation models from the nearest neighbors perspective. We investigate to what extent the nearest neighbors share information with the underlying word embeddings as well as related WordNet entries. Additionally, we study the underlying syntactic structure of the nearest neighbors to shed light on the role of syntactic similarities in bringing the neighbors together. We compare transformer and recurrent models in a more intrinsic way in terms of capturing lexical semantics and syntactic structures, in contrast to extrinsic approaches used by previous works. In agreement with the extrinsic evaluations in the earlier works, our experimental results show that transformers are superior in capturing lexical semantics, but not necessarily better in capturing the underlying syntax. Additionally, we show that the backward recurrent layer in a recurrent model learns more about the semantics of words, whereas the forward recurrent layer encodes more context.
What does Attention in Neural Machine Translation Pay Attention to?
Oct 09, 2017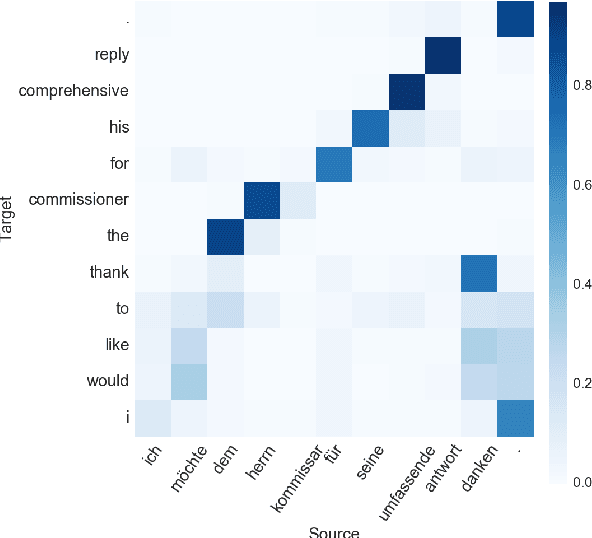
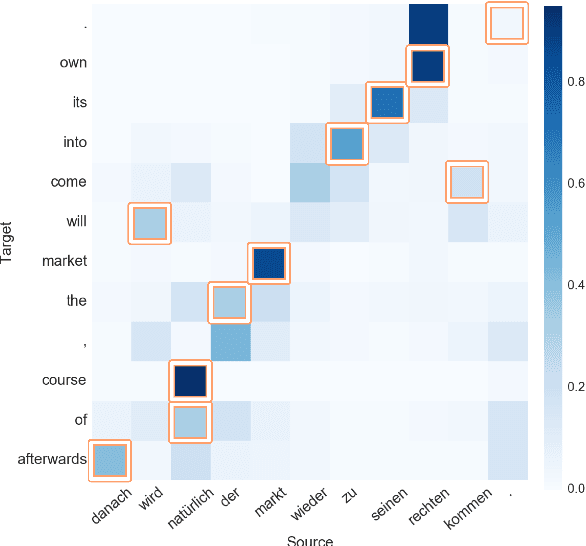

Attention in neural machine translation provides the possibility to encode relevant parts of the source sentence at each translation step. As a result, attention is considered to be an alignment model as well. However, there is no work that specifically studies attention and provides analysis of what is being learned by attention models. Thus, the question still remains that how attention is similar or different from the traditional alignment. In this paper, we provide detailed analysis of attention and compare it to traditional alignment. We answer the question of whether attention is only capable of modelling translational equivalent or it captures more information. We show that attention is different from alignment in some cases and is capturing useful information other than alignments.