 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical analysis of phrase-based and neural machine translation
Paper and Code
Mar 04, 2021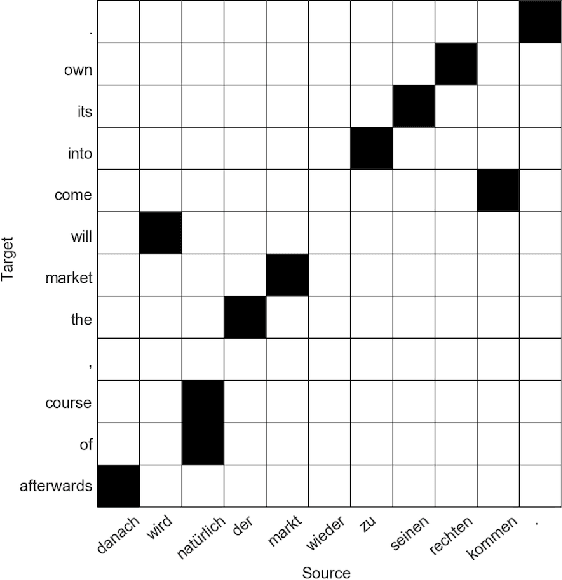
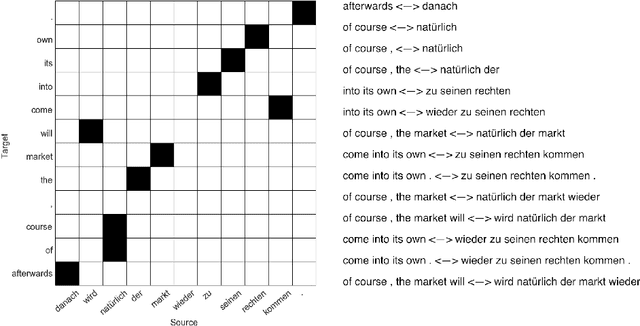
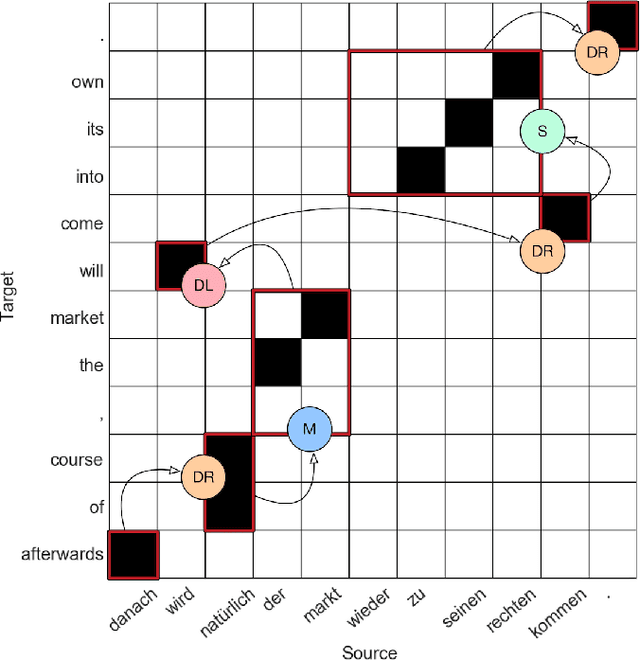
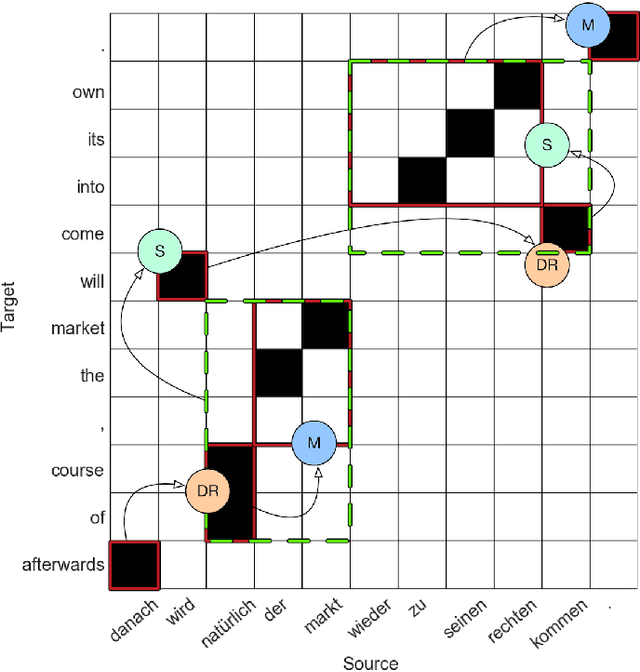
Two popular types of machine translation (MT) are phrase-based and neural machine translation systems. Both of these types of systems are composed of multiple complex models or layers. Each of these models and layers learns different linguistic aspects of the source language. However, for some of these models and layers, it is not clear which linguistic phenomena are learned or how this information is learned. For phrase-based MT systems, it is often clear what information is learned by each model, and the question is rather how this information is learned, especially for its phrase reordering model. For neural machine translation systems, the situation is even more complex, since for many cases it is not exactly clear what information is learned and how it is learned. To shed light on what linguistic phenomena are captured by MT systems, we analyze the behavior of important models in both phrase-based and neural MT systems. We consider phrase reordering models from phrase-based MT systems to investigate which words from inside of a phrase have the biggest impact on defining the phrase reordering behavior. Additionally, to contribute to the interpretability of neural MT systems we study the behavior of the attention model, which is a key component in neural MT systems and the closest model in functionality to phrase reordering models in phrase-based systems. The attention model together with the encoder hidden state representations form the main components to encode source side linguistic information in neural MT. To this end, we also analyze the information captured in the encoder hidden state representations of a neural MT system. We investigate the extent to which syntactic and lexical-semantic information from the source side is captured by hidden state representations of different neural MT architectures.