 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLLM-Eval: A Comprehensive Evaluation Suite for Vietnamese Large Language Models
Apr 18, 2024The rapid advancement of large language models (LLMs) necessitates the development of new benchmarks to accurately assess their capabilities. To address this need for Vietnamese, this work aims to introduce ViLLM-Eval, the comprehensive evaluation suite designed to measure the advanced knowledge and reasoning abilities of foundation models within a Vietnamese context. ViLLM-Eval consists of multiple-choice questions and predict next word tasks spanning various difficulty levels and diverse disciplines, ranging from humanities to science and engineering. A thorough evaluation of the most advanced LLMs on ViLLM-Eval revealed that even the best performing models have significant room for improvement in understanding and responding to Vietnamese language tasks. ViLLM-Eval is believed to be instrumental in identifying key strengths and weaknesses of foundation models, ultimately promoting their development and enhancing their performance for Vietnamese users. This paper provides a thorough overview of ViLLM-Eval as part of the Vietnamese Large Language Model shared task, held within the 10th International Workshop on Vietnamese Language and Speech Processing (VLSP 2023).
An Experimental Investigation of Part-Of-Speech Taggers for Vietnamese
Jun 14, 2022

Part-of-speech (POS) tagging plays an important role in Natural Language Processing (NLP). Its applications can be found in many NLP tasks such as named entity recognition, syntactic parsing, dependency parsing and text chunking. In the investigation conducted in this paper, we utilize the technologies of two widely-used toolkits, ClearNLP and Stanford POS Tagger, as well as develop two new POS taggers for Vietnamese, then compare them to three well-known Vietnamese taggers, namely JVnTagger, vnTagger and RDRPOSTagger. We make a systematic comparison to find out the tagger having the best performance. We also design a new feature set to measure the performance of the statistical taggers. Our new taggers built from Stanford Tagger and ClearNLP with the new feature set can outperform all other current Vietnamese taggers in term of tagging accuracy. Moreover, we also analyze the affection of some features to the performance of statistical taggers. Lastly, the experimental results also reveal that the transformation-based tagger, RDRPOSTagger, can run significantly faster than any other statistical tagger.
A Comparative Study of Neural Network Models for Sentence Classification
Oct 03, 2018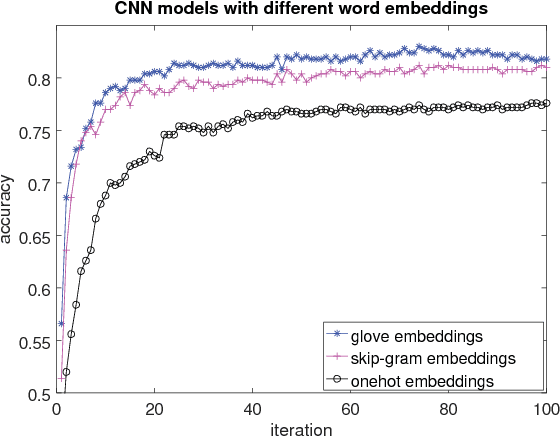
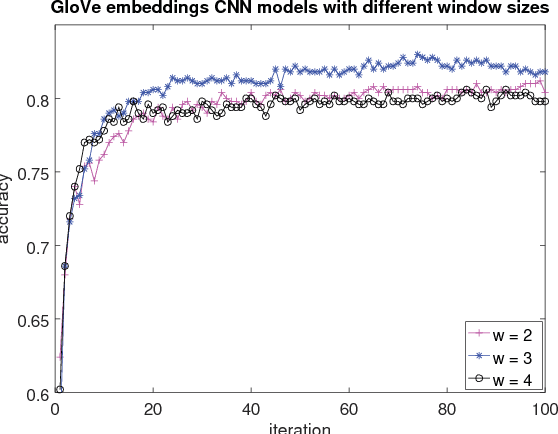
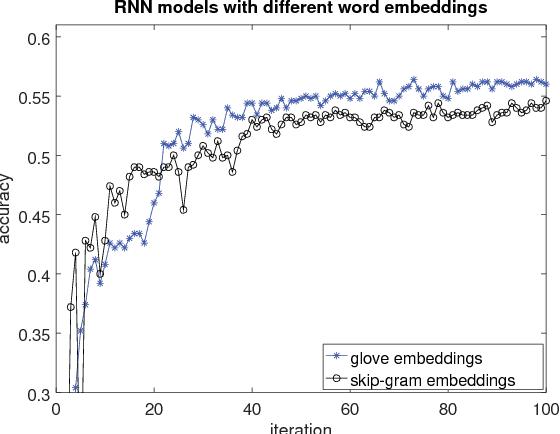
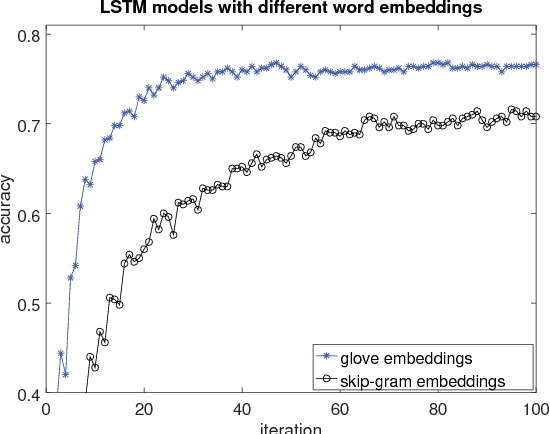
This paper presents an extensive comparative study of four neural network models, including feed-forward networks, convolutional networks, recurrent networks and long short-term memory networks, on two sentence classification datasets of English and Vietnamese text. We show that on the English dataset, the convolutional network models without any feature engineering outperform some competitive sentence classifiers with rich hand-crafted linguistic features. We demonstrate that the GloVe word embeddings are consistently better than both Skip-gram word embeddings and word count vectors. We also show the superiority of convolutional neural network models on a Vietnamese newspaper sentence dataset over strong baseline models. Our experimental results suggest some good practices for applying neural network models in sentence classification.