 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Fusion of Multi-Source Knowledge via Evidence Theory for High-Entropy Alloy Discovery
Feb 20, 2025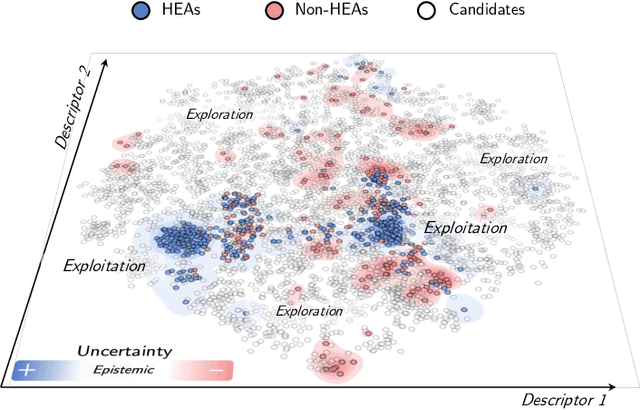



Discovering novel high-entropy alloys (HEAs) with desirable properties is challenging due to the vast compositional space and complex phase formation mechanisms. Efficient exploration of this space requires a strategic approach that integrates heterogeneous knowledge sources. Here, we propose a framework that systematically combines knowledge extracted from computational material datasets with domain knowledge distilled from scientific literature using large language models (LLMs). A central feature of this approach is the explicit consideration of element substitutability, identifying chemically similar elements that can be interchanged to potentially stabilize desired HEAs. Dempster-Shafer theory, a mathematical framework for reasoning under uncertainty, is employed to model and combine substitutabilities based on aggregated evidence from multiple sources. The framework predicts the phase stability of candidate HEA compositions and is systematically evaluated on both quaternary alloy systems, demonstrating superior performance compared to baseline machine learning models and methods reliant on single-source evidence in cross-validation experiments. By leveraging multi-source knowledge, the framework retains robust predictive power even when key elements are absent from the training data, underscoring its potential for knowledge transfer and extrapolation. Furthermore, the enhanced interpretability of the methodology offers insights into the fundamental factors governing HEA formation. Overall, this work provides a promising strategy for accelerating HEA discovery by integrating computational and textual knowledge sources, enabling efficient exploration of vast compositional spaces with improved generalization and interpretability.
ViLLM-Eval: A Comprehensive Evaluation Suite for Vietnamese Large Language Models
Apr 18, 2024The rapid advancement of large language models (LLMs) necessitates the development of new benchmarks to accurately assess their capabilities. To address this need for Vietnamese, this work aims to introduce ViLLM-Eval, the comprehensive evaluation suite designed to measure the advanced knowledge and reasoning abilities of foundation models within a Vietnamese context. ViLLM-Eval consists of multiple-choice questions and predict next word tasks spanning various difficulty levels and diverse disciplines, ranging from humanities to science and engineering. A thorough evaluation of the most advanced LLMs on ViLLM-Eval revealed that even the best performing models have significant room for improvement in understanding and responding to Vietnamese language tasks. ViLLM-Eval is believed to be instrumental in identifying key strengths and weaknesses of foundation models, ultimately promoting their development and enhancing their performance for Vietnamese users. This paper provides a thorough overview of ViLLM-Eval as part of the Vietnamese Large Language Model shared task, held within the 10th International Workshop on Vietnamese Language and Speech Processing (VLSP 2023).
Ensemble learning reveals dissimilarity between rare-earth transition metal binary alloys with respect to the Curie temperature
Aug 20, 2020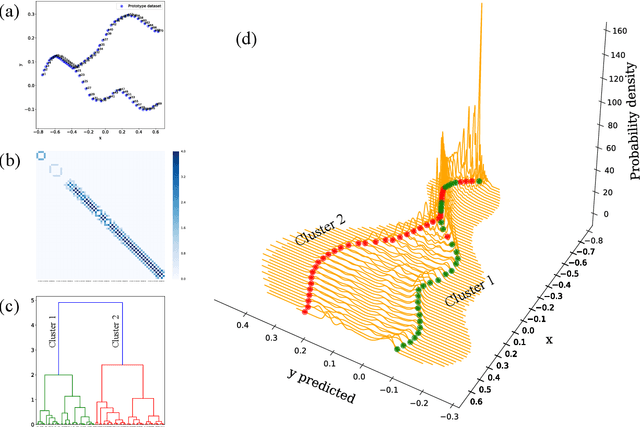
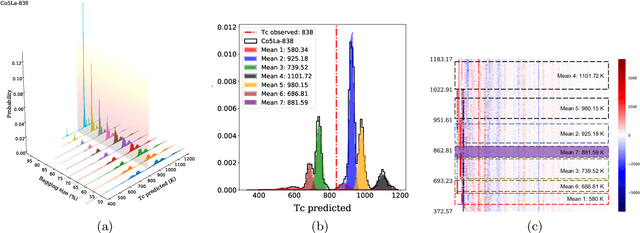
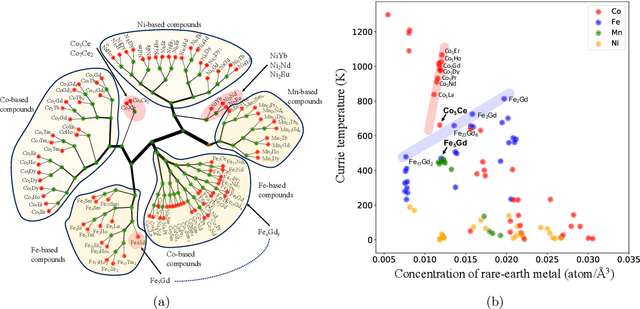
We propose a data-driven method to extract dissimilarity between materials, with respect to a given target physical property. The technique is based on an ensemble method with Kernel ridge regression as the predicting model; multiple random subset sampling of the materials is done to generate prediction models and the corresponding contributions of the reference training materials in detail. The distribution of the predicted values for each material can be approximated by a Gaussian mixture model. The reference training materials contributed to the prediction model that accurately predicts the physical property value of a specific material, are considered to be similar to that material, or vice versa. Evaluations using synthesized data demonstrate that the proposed method can effectively measure the dissimilarity between data instances. An application of the analysis method on the data of Curie temperature (TC) of binary 3d transition metal 4f rare earth binary alloys also reveals meaningful results on the relations between the materials. The proposed method can be considered as a potential tool for obtaining a deeper understanding of the structure of data, with respect to a target property, in particular.