 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Fusion of Multi-Source Knowledge via Evidence Theory for High-Entropy Alloy Discovery
Feb 20, 2025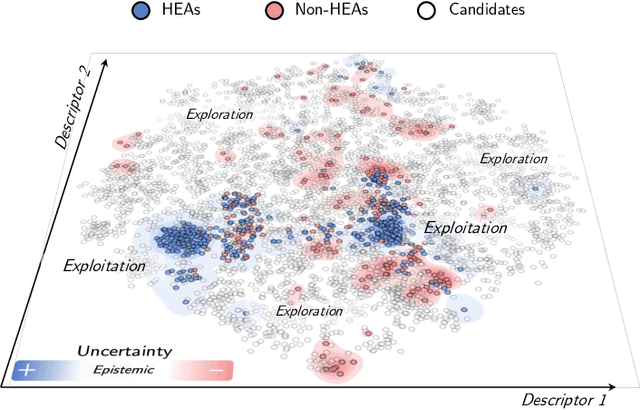



Discovering novel high-entropy alloys (HEAs) with desirable properties is challenging due to the vast compositional space and complex phase formation mechanisms. Efficient exploration of this space requires a strategic approach that integrates heterogeneous knowledge sources. Here, we propose a framework that systematically combines knowledge extracted from computational material datasets with domain knowledge distilled from scientific literature using large language models (LLMs). A central feature of this approach is the explicit consideration of element substitutability, identifying chemically similar elements that can be interchanged to potentially stabilize desired HEAs. Dempster-Shafer theory, a mathematical framework for reasoning under uncertainty, is employed to model and combine substitutabilities based on aggregated evidence from multiple sources. The framework predicts the phase stability of candidate HEA compositions and is systematically evaluated on both quaternary alloy systems, demonstrating superior performance compared to baseline machine learning models and methods reliant on single-source evidence in cross-validation experiments. By leveraging multi-source knowledge, the framework retains robust predictive power even when key elements are absent from the training data, underscoring its potential for knowledge transfer and extrapolation. Furthermore, the enhanced interpretability of the methodology offers insights into the fundamental factors governing HEA formation. Overall, this work provides a promising strategy for accelerating HEA discovery by integrating computational and textual knowledge sources, enabling efficient exploration of vast compositional spaces with improved generalization and interpretability.
Estimating the Optimal Number of Clusters in Categorical Data Clustering by Silhouette Coefficient
Jan 26, 2025The problem of estimating the number of clusters (say k) is one of the major challenges for the partitional clustering. This paper proposes an algorithm named k-SCC to estimate the optimal k in categorical data clustering. For the clustering step, the algorithm uses the kernel density estimation approach to define cluster centers. In addition, it uses an information-theoretic based dissimilarity to measure the distance between centers and objects in each cluster. The silhouette analysis based approach is then used to evaluate the quality of different clustering obtained in the former step to choose the best k. Comparative experiments were conducted on both synthetic and real datasets to compare the performance of k-SCC with three other algorithms. Experimental results show that k-SCC outperforms the compared algorithms in determining the number of clusters for each dataset.
Categorical data clustering: 25 years beyond K-modes
Aug 30, 2024



The clustering of categorical data is a common and important task in computer science, offering profound implications across a spectrum of applications. Unlike purely numerical datasets, categorical data often lack inherent ordering as in nominal data, or have varying levels of order as in ordinal data, thus requiring specialized methodologies for efficient organization and analysis. This review provides a comprehensive synthesis of categorical data clustering in the past twenty-five years, starting from the introduction of K-modes. It elucidates the pivotal role of categorical data clustering in diverse fields such as health sciences, natural sciences, social sciences, education, engineering and economics. Practical comparisons are conducted for algorithms having public implementations, highlighting distinguishing clustering methodologies and revealing the performance of recent algorithms on several benchmark categorical datasets. Finally, challenges and opportunities in the field are discussed.