 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical data clustering: 25 years beyond K-modes
Aug 30, 2024



The clustering of categorical data is a common and important task in computer science, offering profound implications across a spectrum of applications. Unlike purely numerical datasets, categorical data often lack inherent ordering as in nominal data, or have varying levels of order as in ordinal data, thus requiring specialized methodologies for efficient organization and analysis. This review provides a comprehensive synthesis of categorical data clustering in the past twenty-five years, starting from the introduction of K-modes. It elucidates the pivotal role of categorical data clustering in diverse fields such as health sciences, natural sciences, social sciences, education, engineering and economics. Practical comparisons are conducted for algorithms having public implementations, highlighting distinguishing clustering methodologies and revealing the performance of recent algorithms on several benchmark categorical datasets. Finally, challenges and opportunities in the field are discussed.
$\mathcal{G}^2Pxy$: Generative Open-Set Node Classification on Graphs with Proxy Unknowns
Aug 10, 2023Node classification is the task of predicting the labels of unlabeled nodes in a graph. State-of-the-art methods based on graph neural networks achieve excellent performance when all labels are available during training. But in real-life, models are often applied on data with new classes, which can lead to massive misclassification and thus significantly degrade performance. Hence, developing open-set classification methods is crucial to determine if a given sample belongs to a known class. Existing methods for open-set node classification generally use transductive learning with part or all of the features of real unseen class nodes to help with open-set classification. In this paper, we propose a novel generative open-set node classification method, i.e. $\mathcal{G}^2Pxy$, which follows a stricter inductive learning setting where no information about unknown classes is available during training and validation. Two kinds of proxy unknown nodes, inter-class unknown proxies and external unknown proxies are generated via mixup to efficiently anticipate the distribution of novel classes. Using the generated proxies, a closed-set classifier can be transformed into an open-set one, by augmenting it with an extra proxy classifier. Under the constraints of both cross entropy loss and complement entropy loss, $\mathcal{G}^2Pxy$ achieves superior effectiveness for unknown class detection and known class classification, which is validated by experiments on benchmark graph datasets. Moreover, $\mathcal{G}^2Pxy$ does not have specific requirement on the GNN architecture and shows good generalizations.
Image-text Retrieval via Preserving Main Semantics of Vision
Apr 28, 2023



Image-text retrieval is one of the major tasks of cross-modal retrieval. Several approaches for this task map images and texts into a common space to create correspondences between the two modalities. However, due to the content (semantics) richness of an image, redundant secondary information in an image may cause false matches. To address this issue, this paper presents a semantic optimization approach, implemented as a Visual Semantic Loss (VSL), to assist the model in focusing on an image's main content. This approach is inspired by how people typically annotate the content of an image by describing its main content. Thus, we leverage the annotated texts corresponding to an image to assist the model in capturing the main content of the image, reducing the negative impact of secondary content. Extensive experiments on two benchmark datasets (MSCOCO and Flickr30K) demonstrate the superior performance of our method. The code is available at: https://github.com/ZhangXu0963/VSL.
Mining compact high utility sequential patterns
Feb 22, 2023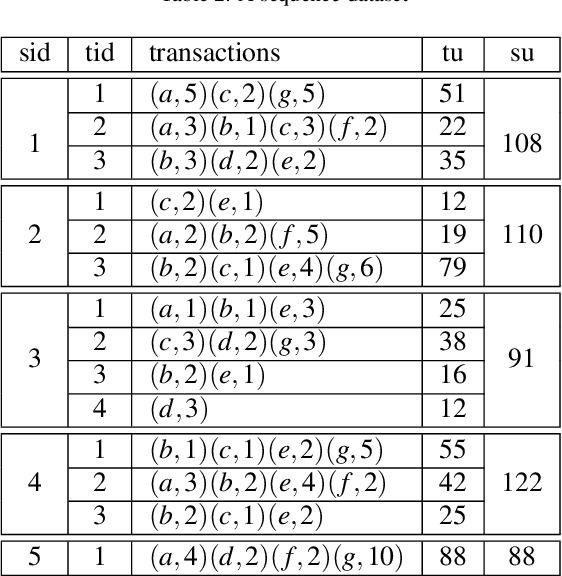
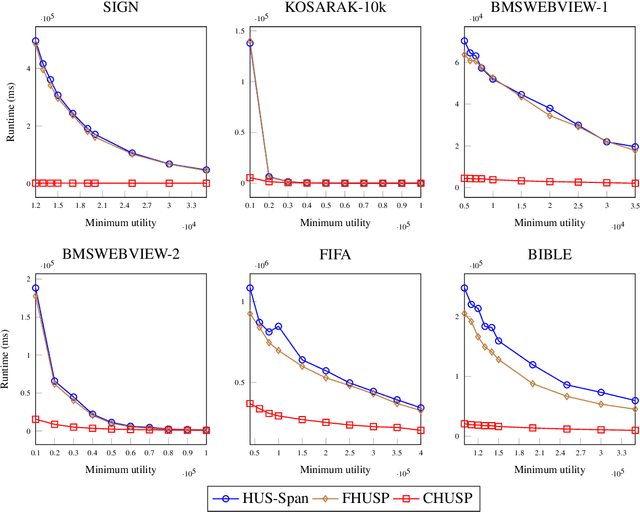
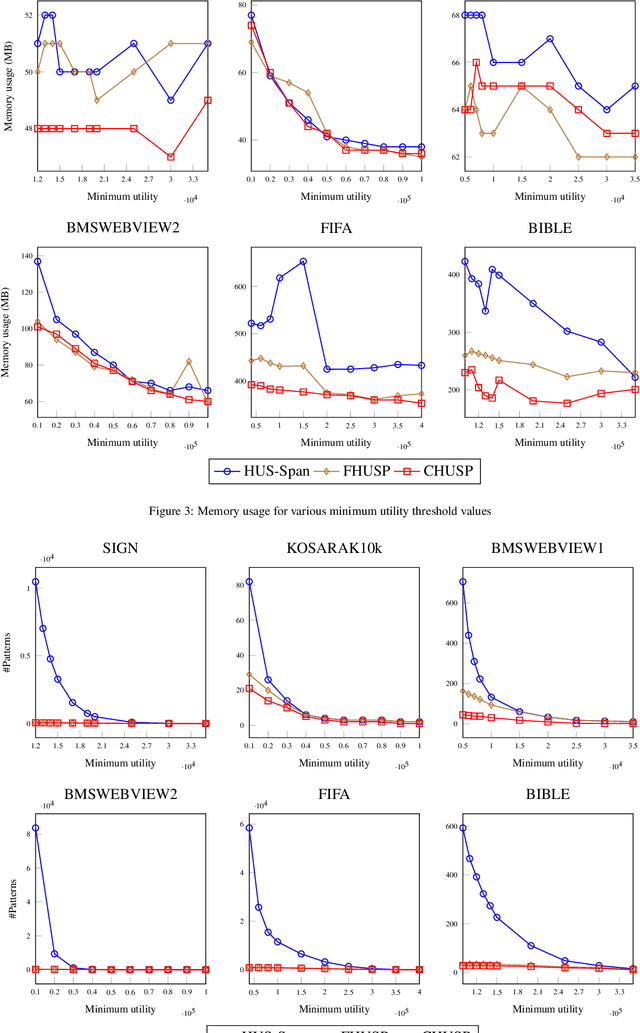
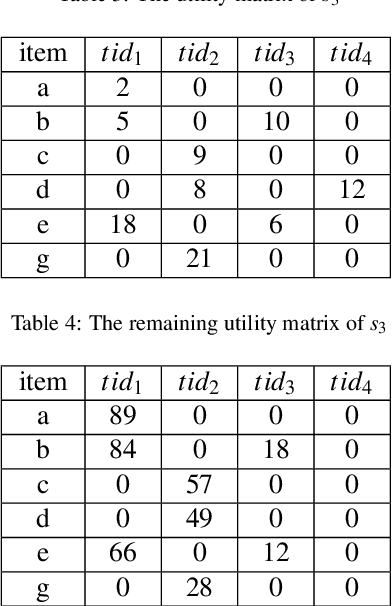
High utility sequential pattern mining (HUSPM) aims to mine all patterns that yield a high utility (profit) in a sequence dataset. HUSPM is useful for several applications such as market basket analysis, marketing, and website clickstream analysis. In these applications, users may also consider high utility patterns frequently appearing in the dataset to obtain more fruitful information. However, this task is high computation since algorithms may generate a combinatorial explosive number of candidates that may be redundant or of low importance. To reduce complexity and obtain a compact set of frequent high utility sequential patterns (FHUSPs), this paper proposes an algorithm named CHUSP for mining closed frequent high utility sequential patterns (CHUSPs). Such patterns keep a concise representation while preserving the same expressive power of the complete set of FHUSPs. The proposed algorithm relies on a CHUS data structure to maintain information during mining. It uses three pruning strategies to eliminate early low-utility and non-frequent patterns, thereby reducing the search space. An extensive experimental evaluation was performed on six real-life datasets to evaluate the performance of CHUSP in terms of execution time, memory usage, and the number of generated patterns. Experimental results show that CHUSP can efficiently discover the compact set of CHUSPs under different user-defined thresholds.
Towards Target High-Utility Itemsets
Jun 09, 2022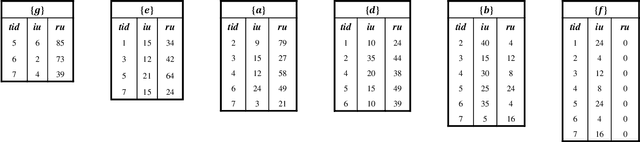

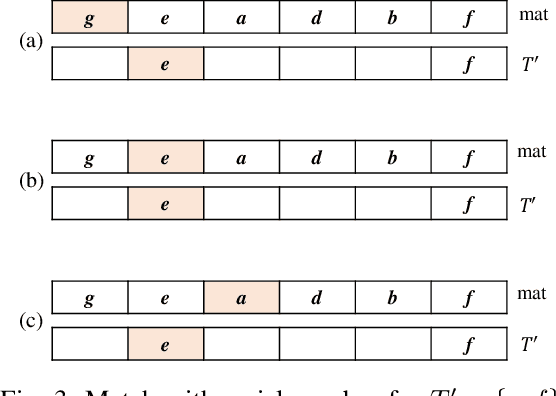
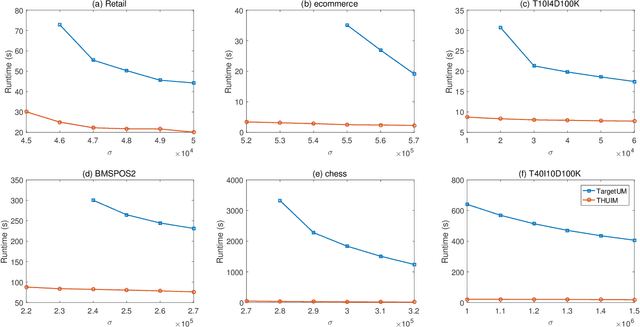
For applied intelligence, utility-driven pattern discovery algorithms can identify insightful and useful patterns in databases. However, in these techniques for pattern discovery, the number of patterns can be huge, and the user is often only interested in a few of those patterns. Hence, targeted high-utility itemset mining has emerged as a key research topic, where the aim is to find a subset of patterns that meet a targeted pattern constraint instead of all patterns. This is a challenging task because efficiently finding tailored patterns in a very large search space requires a targeted mining algorithm. A first algorithm called TargetUM has been proposed, which adopts an approach similar to post-processing using a tree structure, but the running time and memory consumption are unsatisfactory in many situations. In this paper, we address this issue by proposing a novel list-based algorithm with pattern matching mechanism, named THUIM (Targeted High-Utility Itemset Mining), which can quickly match high-utility itemsets during the mining process to select the targeted patterns. Extensive experiments were conducted on different datasets to compare the performance of the proposed algorithm with state-of-the-art algorithms. Results show that THUIM performs very well in terms of runtime and memory consumption, and has good scalability compared to TargetUM.
Discovering Representative Attribute-stars via Minimum Description Length
Apr 27, 2022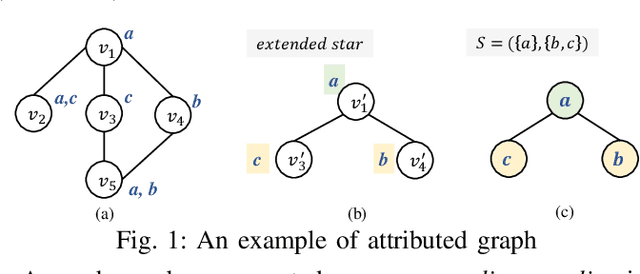
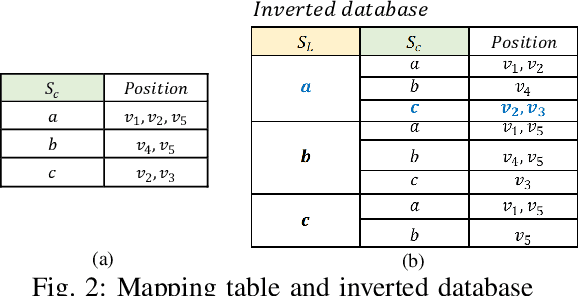
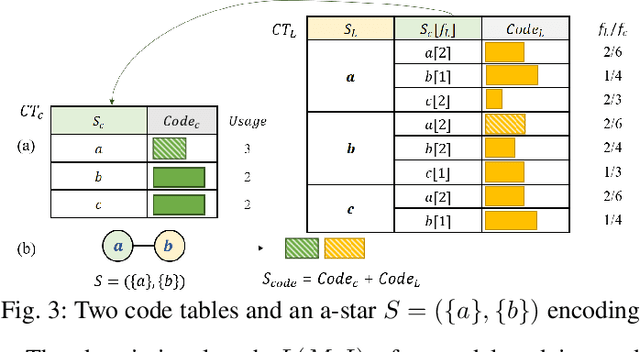

Graphs are a popular data type found in many domains. Numerous techniques have been proposed to find interesting patterns in graphs to help understand the data and support decision-making. However, there are generally two limitations that hinder their practical use: (1) they have multiple parameters that are hard to set but greatly influence results, (2) and they generally focus on identifying complex subgraphs while ignoring relationships between attributes of nodes.Graphs are a popular data type found in many domains. Numerous techniques have been proposed to find interesting patterns in graphs to help understand the data and support decision-making. However, there are generally two limitations that hinder their practical use: (1) they have multiple parameters that are hard to set but greatly influence results, (2) and they generally focus on identifying complex subgraphs while ignoring relationships between attributes of nodes. To address these problems, we propose a parameter-free algorithm named CSPM (Compressing Star Pattern Miner) which identifies star-shaped patterns that indicate strong correlations among attributes via the concept of conditional entropy and the minimum description length principle. Experiments performed on several benchmark datasets show that CSPM reveals insightful and interpretable patterns and is efficient in runtime. Moreover, quantitative evaluations on two real-world applications show that CSPM has broad applications as it successfully boosts the accuracy of graph attribute completion models by up to 30.68\% and uncovers important patterns in telecommunication alarm data.
Towards Revenue Maximization with Popular and Profitable Products
Feb 26, 2022
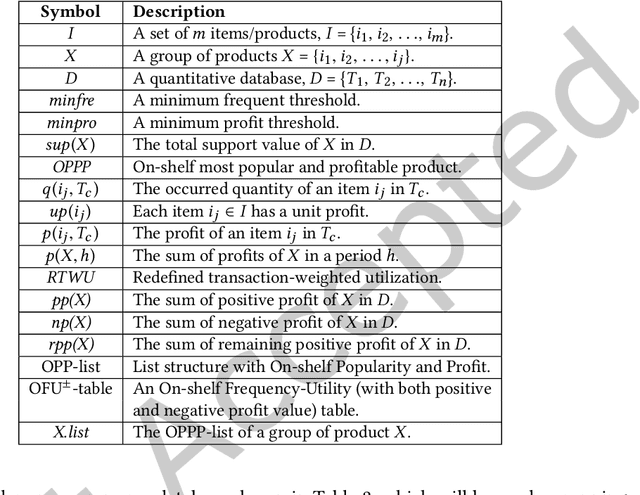

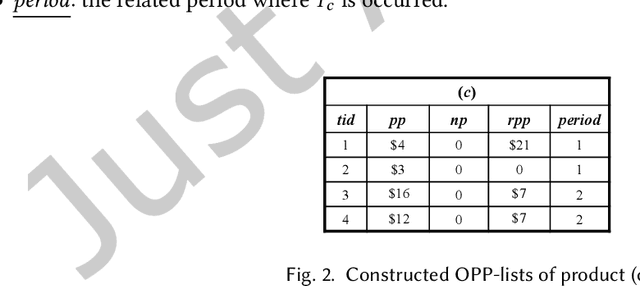
Economic-wise, a common goal for companies conducting marketing is to maximize the return revenue/profit by utilizing the various effective marketing strategies. Consumer behavior is crucially important in economy and targeted marketing, in which behavioral economics can provide valuable insights to identify the biases and profit from customers. Finding credible and reliable information on products' profitability is, however, quite difficult since most products tends to peak at certain times w.r.t. seasonal sales cycle in a year. On-Shelf Availability (OSA) plays a key factor for performance evaluation. Besides, staying ahead of hot product trends means we can increase marketing efforts without selling out the inventory. To fulfill this gap, in this paper, we first propose a general profit-oriented framework to address the problem of revenue maximization based on economic behavior, and compute the 0n-shelf Popular and most Profitable Products (OPPPs) for the targeted marketing. To tackle the revenue maximization problem, we model the k-satisfiable product concept and propose an algorithmic framework for searching OPPP and its variants. Extensive experiments are conducted on several real-world datasets to evaluate the effectiveness and efficiency of the proposed algorithm.
Enhancing Hyperbolic Graph Embeddings via Contrastive Learning
Jan 21, 2022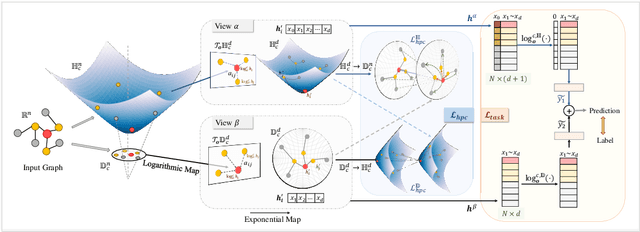
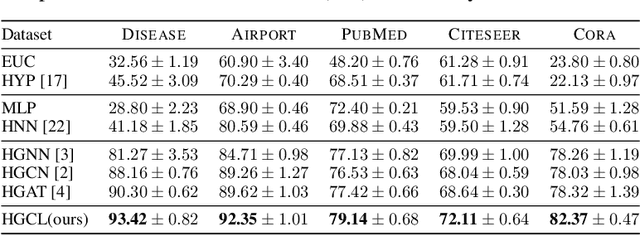
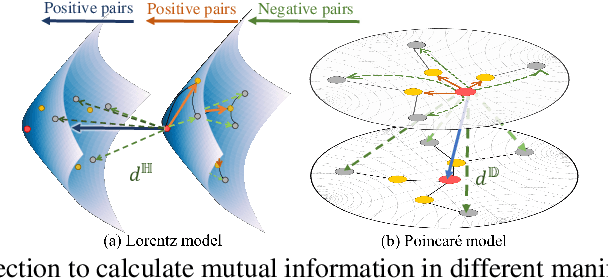

Recently, hyperbolic space has risen as a promising alternative for semi-supervised graph representation learning. Many efforts have been made to design hyperbolic versions of neural network operations. However, the inspiring geometric properties of this unique geometry have not been fully explored yet. The potency of graph models powered by the hyperbolic space is still largely underestimated. Besides, the rich information carried by abundant unlabelled samples is also not well utilized. Inspired by the recently active and emerging self-supervised learning, in this study, we attempt to enhance the representation power of hyperbolic graph models by drawing upon the advantages of contrastive learning. More specifically, we put forward a novel Hyperbolic Graph Contrastive Learning (HGCL) framework which learns node representations through multiple hyperbolic spaces to implicitly capture the hierarchical structure shared between different views. Then, we design a hyperbolic position consistency (HPC) constraint based on hyperbolic distance and the homophily assumption to make contrastive learning fit into hyperbolic space. Experimental results on multiple real-world datasets demonstrate the superiority of the proposed HGCL as it consistently outperforms competing methods by considerable margins for the node classification task.
How Emotional Mechanism Helps Episodic Learning in a Cognitive Agent
Jan 30, 2009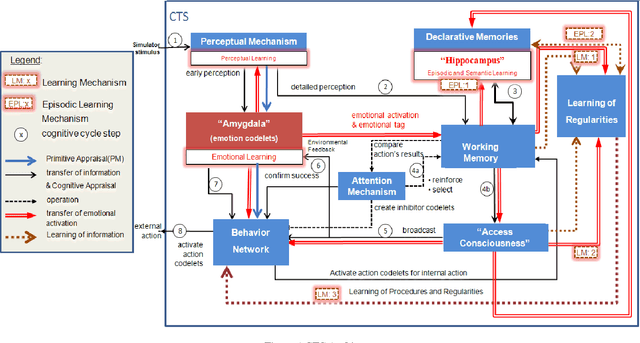
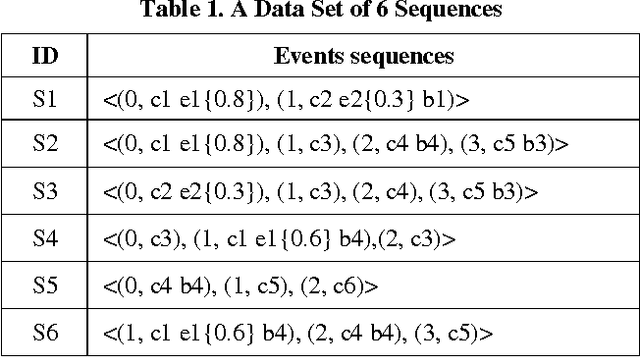
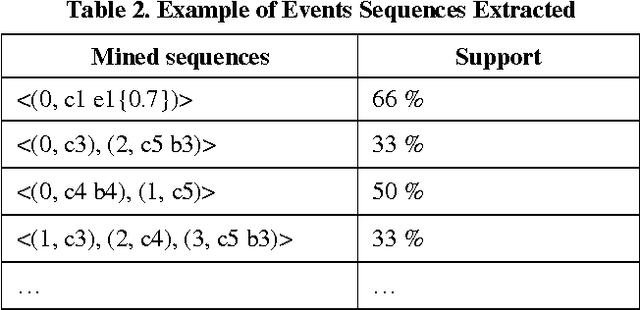
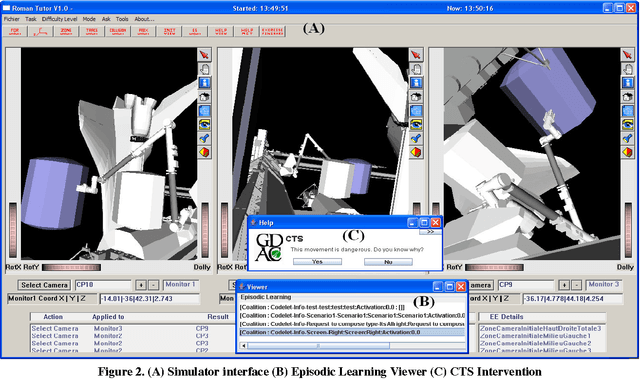
In this paper we propose the CTS (Concious Tutoring System) technology, a biologically plausible cognitive agent based on human brain functions.This agent is capable of learning and remembering events and any related information such as corresponding procedures, stimuli and their emotional valences. Our proposed episodic memory and episodic learning mechanism are closer to the current multiple-trace theory in neuroscience, because they are inspired by it [5] contrary to other mechanisms that are incorporated in cognitive agents. This is because in our model emotions play a role in the encoding and remembering of events. This allows the agent to improve its behavior by remembering previously selected behaviors which are influenced by its emotional mechanism. Moreover, the architecture incorporates a realistic memory consolidation process based on a data mining algorithm.