 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-driven personalized information retrieval for XML documents
Mar 22, 2026This paper addresses the challenge of improving information retrieval from semi-structured eXtensible Markup Language (XML) documents. Traditional information retrieval systems (IRS) often overlook user-specific needs and return identical results for the same query, despite differences in users' knowledge, preferences, and objectives. We integrate external semantic resources, namely a domain ontology and user profiles, into the retrieval process. Documents, queries, and user profiles are represented as vectors of weighted concepts. The ontology applies a concept-weighting mechanism that emphasizes highly specific concepts, as lower-level nodes in the hierarchy provide more precise and targeted information. Relevance is assessed using semantic similarity measures that capture conceptual relationships beyond keyword matching, enabling personalized and fine-grained matching among user profiles, queries, and documents. Experimental results show that combining ontologies with user profiles improves retrieval effectiveness, achieving higher precision and recall than keyword-based approaches. Overall, the proposed framework enhances the relevance and adaptability of XML search results, supporting more user-centered retrieval.
An upper bound of the silhouette validation metric for clustering
Sep 10, 2025The silhouette coefficient summarizes, per observation, cohesion versus separation in [-1, 1]; the average silhouette width (ASW) is a common internal measure of clustering quality where higher values indicate more coveted results. However, the dataset-specific maximum of ASW is typically unknown, and the standard upper limit 1 is often unattainable. In this work, we derive for each data point in a given dataset a sharp upper bound on its silhouette width. By aggregating these individual bounds, we present a canonical data-dependent upper bound on ASW that often assumes values well below 1. The presented bounds can indicate whether individual data points can ever be well placed, enable early stopping of silhouette-based optimization loops, and help answer a key question: How close is my clustering result to the best possible outcome on this specific data? Across synthetic and real datasets, the bounds are provably near-tight in many cases and offer significant enrichment of cluster quality evaluation.
Data clustering: an essential technique in data science
Dec 25, 2024This paper provides a comprehensive exploration of data clustering, emphasizing its methodologies and applications across different fields. Traditional techniques, including partitional and hierarchical clustering, are discussed alongside other approaches such as data stream, subspace and network clustering, highlighting their role in addressing complex, high-dimensional datasets. The paper also reviews the foundational principles of clustering, introduces common tools and methods, and examines its diverse applications in data science. Finally, the discussion concludes with insights into future directions, underscoring the centrality of clustering in driving innovation and enabling data-driven decision making.
Categorical data clustering: 25 years beyond K-modes
Aug 30, 2024



The clustering of categorical data is a common and important task in computer science, offering profound implications across a spectrum of applications. Unlike purely numerical datasets, categorical data often lack inherent ordering as in nominal data, or have varying levels of order as in ordinal data, thus requiring specialized methodologies for efficient organization and analysis. This review provides a comprehensive synthesis of categorical data clustering in the past twenty-five years, starting from the introduction of K-modes. It elucidates the pivotal role of categorical data clustering in diverse fields such as health sciences, natural sciences, social sciences, education, engineering and economics. Practical comparisons are conducted for algorithms having public implementations, highlighting distinguishing clustering methodologies and revealing the performance of recent algorithms on several benchmark categorical datasets. Finally, challenges and opportunities in the field are discussed.
Mining compact high utility sequential patterns
Feb 22, 2023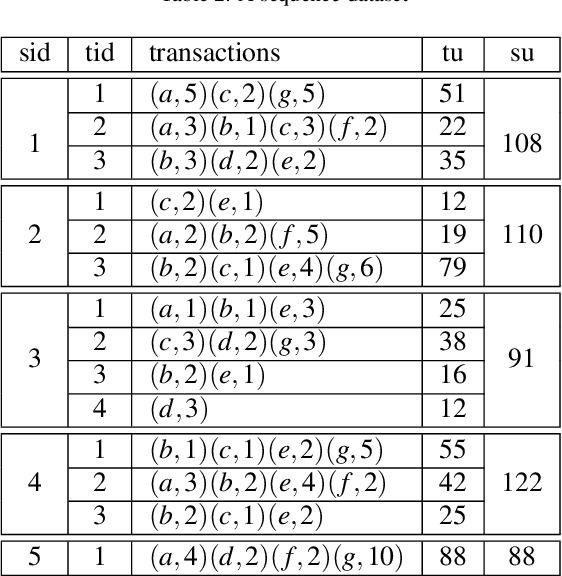
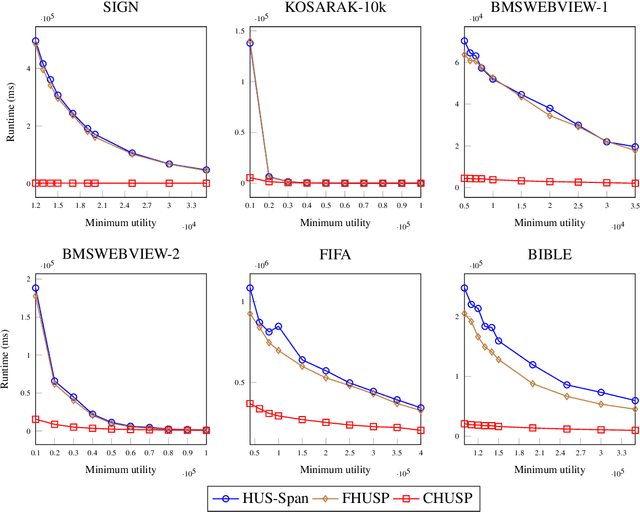
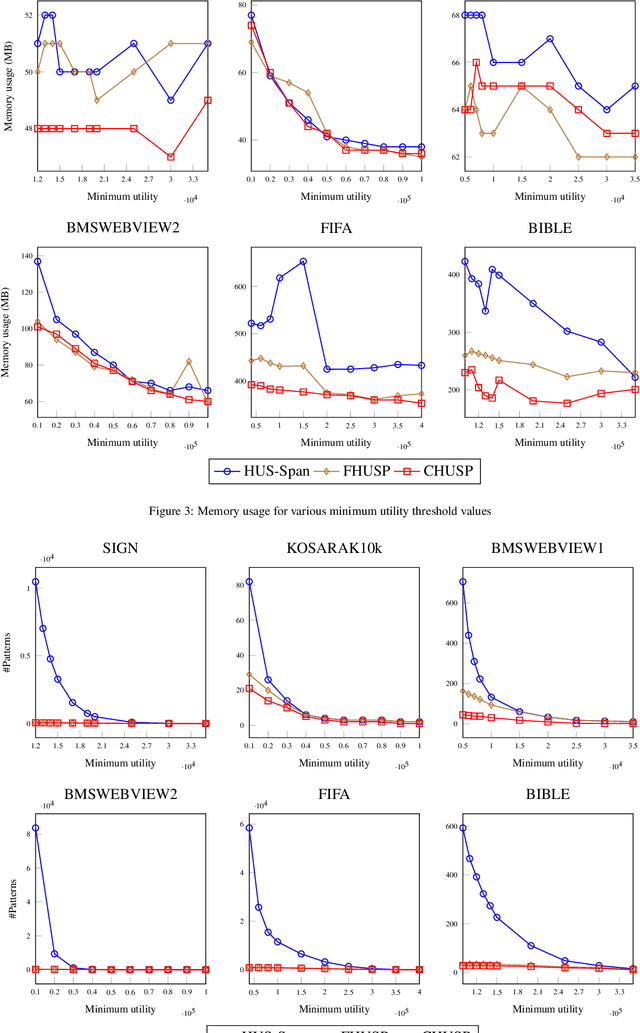
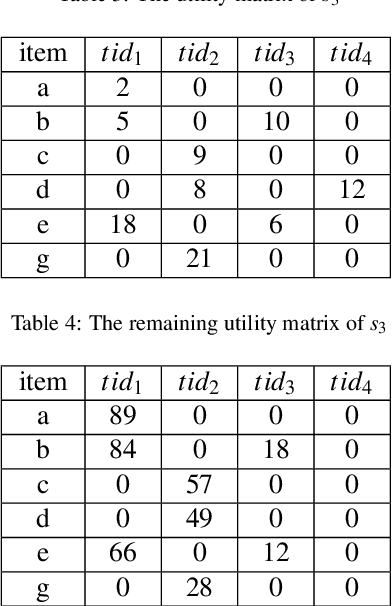
High utility sequential pattern mining (HUSPM) aims to mine all patterns that yield a high utility (profit) in a sequence dataset. HUSPM is useful for several applications such as market basket analysis, marketing, and website clickstream analysis. In these applications, users may also consider high utility patterns frequently appearing in the dataset to obtain more fruitful information. However, this task is high computation since algorithms may generate a combinatorial explosive number of candidates that may be redundant or of low importance. To reduce complexity and obtain a compact set of frequent high utility sequential patterns (FHUSPs), this paper proposes an algorithm named CHUSP for mining closed frequent high utility sequential patterns (CHUSPs). Such patterns keep a concise representation while preserving the same expressive power of the complete set of FHUSPs. The proposed algorithm relies on a CHUS data structure to maintain information during mining. It uses three pruning strategies to eliminate early low-utility and non-frequent patterns, thereby reducing the search space. An extensive experimental evaluation was performed on six real-life datasets to evaluate the performance of CHUSP in terms of execution time, memory usage, and the number of generated patterns. Experimental results show that CHUSP can efficiently discover the compact set of CHUSPs under different user-defined thresholds.