 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Target High-Utility Itemsets
Jun 09, 2022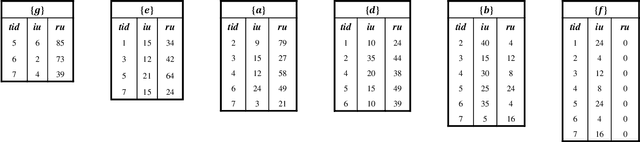

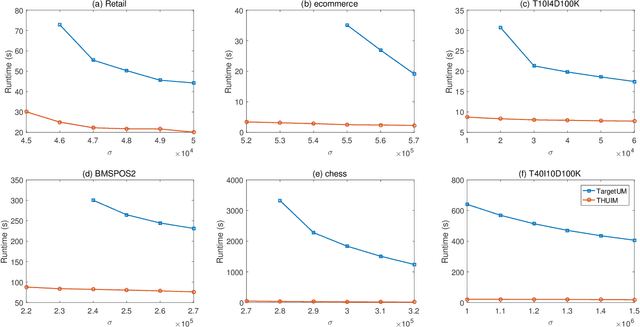
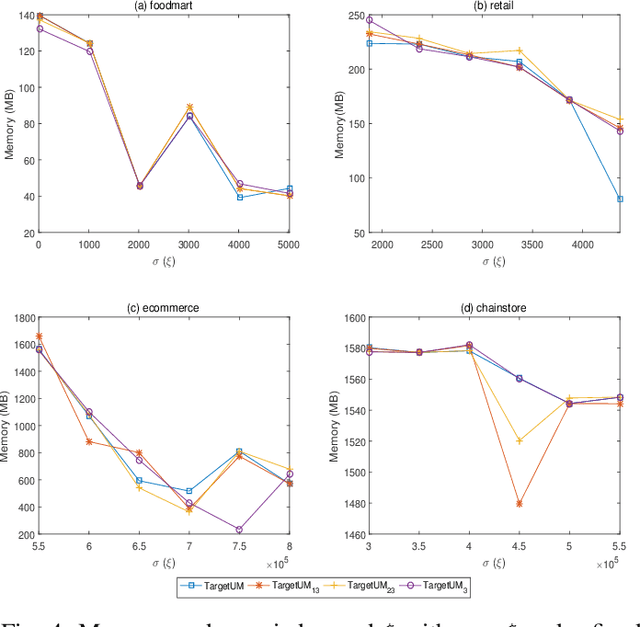
For applied intelligence, utility-driven pattern discovery algorithms can identify insightful and useful patterns in databases. However, in these techniques for pattern discovery, the number of patterns can be huge, and the user is often only interested in a few of those patterns. Hence, targeted high-utility itemset mining has emerged as a key research topic, where the aim is to find a subset of patterns that meet a targeted pattern constraint instead of all patterns. This is a challenging task because efficiently finding tailored patterns in a very large search space requires a targeted mining algorithm. A first algorithm called TargetUM has been proposed, which adopts an approach similar to post-processing using a tree structure, but the running time and memory consumption are unsatisfactory in many situations. In this paper, we address this issue by proposing a novel list-based algorithm with pattern matching mechanism, named THUIM (Targeted High-Utility Itemset Mining), which can quickly match high-utility itemsets during the mining process to select the targeted patterns. Extensive experiments were conducted on different datasets to compare the performance of the proposed algorithm with state-of-the-art algorithms. Results show that THUIM performs very well in terms of runtime and memory consumption, and has good scalability compared to TargetUM.
TargetUM: Targeted High-Utility Itemset Querying
Oct 30, 2021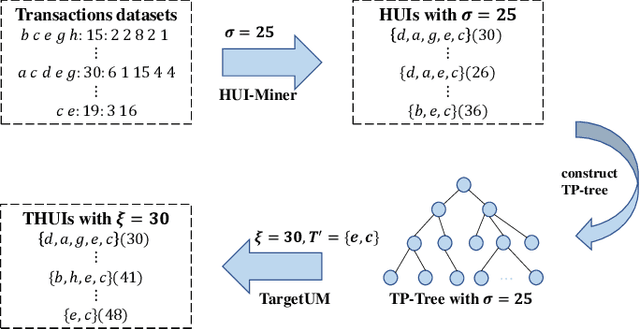
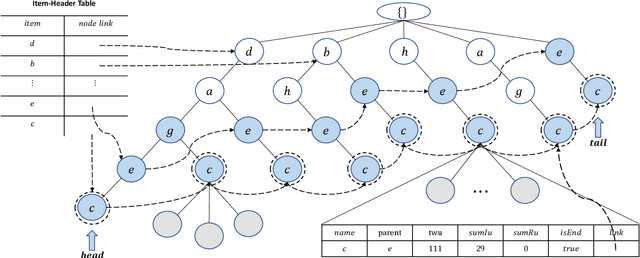

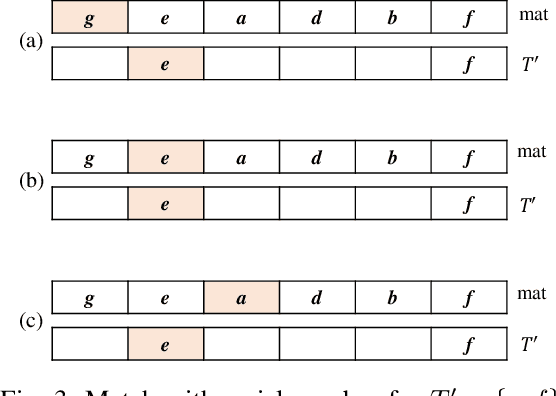
Traditional high-utility itemset mining (HUIM) aims to determine all high-utility itemsets (HUIs) that satisfy the minimum utility threshold (\textit{minUtil}) in transaction databases. However, in most applications, not all HUIs are interesting because only specific parts are required. Thus, targeted mining based on user preferences is more important than traditional mining tasks. This paper is the first to propose a target-based HUIM problem and to provide a clear formulation of the targeted utility mining task in a quantitative transaction database. A tree-based algorithm known as Target-based high-Utility iteMset querying using (TargetUM) is proposed. The algorithm uses a lexicographic querying tree and three effective pruning strategies to improve the mining efficiency. We implemented experimental validation on several real and synthetic databases, and the results demonstrate that the performance of \textbf{TargetUM} is satisfactory, complete, and correct. Finally, owing to the lexicographic querying tree, the database no longer needs to be scanned repeatedly for multiple queries.