 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Correlated Sequential Rules
Oct 27, 2022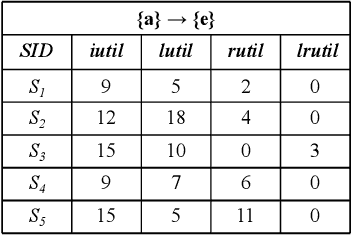
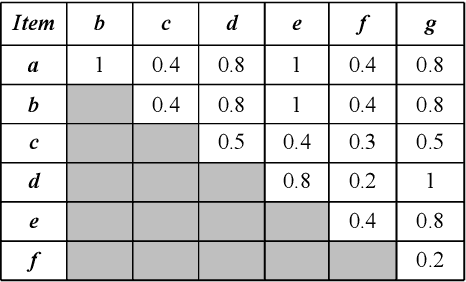
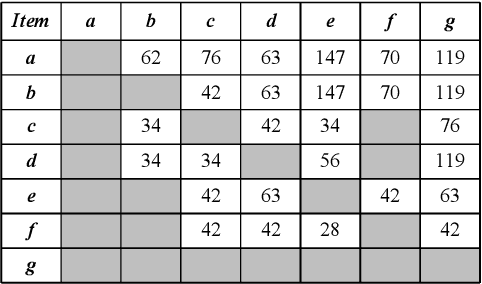
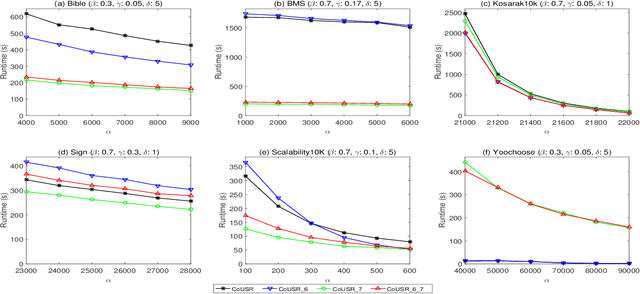
The goal of high-utility sequential pattern mining (HUSPM) is to efficiently discover profitable or useful sequential patterns in a large number of sequences. However, simply being aware of utility-eligible patterns is insufficient for making predictions. To compensate for this deficiency, high-utility sequential rule mining (HUSRM) is designed to explore the confidence or probability of predicting the occurrence of consequence sequential patterns based on the appearance of premise sequential patterns. It has numerous applications, such as product recommendation and weather prediction. However, the existing algorithm, known as HUSRM, is limited to extracting all eligible rules while neglecting the correlation between the generated sequential rules. To address this issue, we propose a novel algorithm called correlated high-utility sequential rule miner (CoUSR) to integrate the concept of correlation into HUSRM. The proposed algorithm requires not only that each rule be correlated but also that the patterns in the antecedent and consequent of the high-utility sequential rule be correlated. The algorithm adopts a utility-list structure to avoid multiple database scans. Additionally, several pruning strategies are used to improve the algorithm's efficiency and performance. Based on several real-world datasets, subsequent experiments demonstrated that CoUSR is effective and efficient in terms of operation time and memory consumption.
Smart System: Joint Utility and Frequency for Pattern Classification
Jun 09, 2022


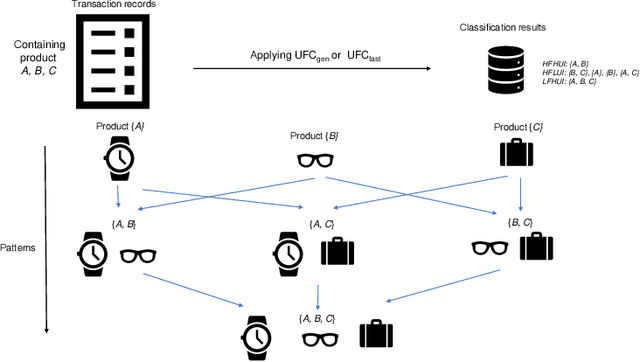
Nowadays, the environments of smart systems for Industry 4.0 and Internet of Things (IoT) are experiencing fast industrial upgrading. Big data technologies such as design making, event detection, and classification are developed to help manufacturing organizations to achieve smart systems. By applying data analysis, the potential values of rich data can be maximized and thus help manufacturing organizations to finish another round of upgrading. In this paper, we propose two new algorithms with respect to big data analysis, namely UFC$_{gen}$ and UFC$_{fast}$. Both algorithms are designed to collect three types of patterns to help people determine the market positions for different product combinations. We compare these algorithms on various types of datasets, both real and synthetic. The experimental results show that both algorithms can successfully achieve pattern classification by utilizing three different types of interesting patterns from all candidate patterns based on user-specified thresholds of utility and frequency. Furthermore, the list-based UFC$_{fast}$ algorithm outperforms the level-wise-based UFC$_{gen}$ algorithm in terms of both execution time and memory consumption.
Towards Revenue Maximization with Popular and Profitable Products
Feb 26, 2022
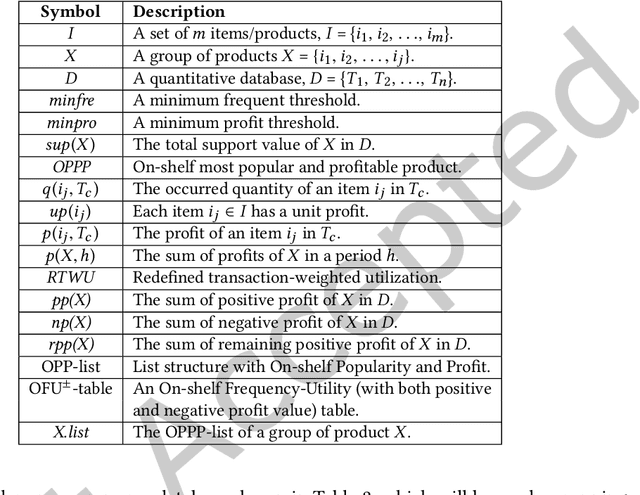

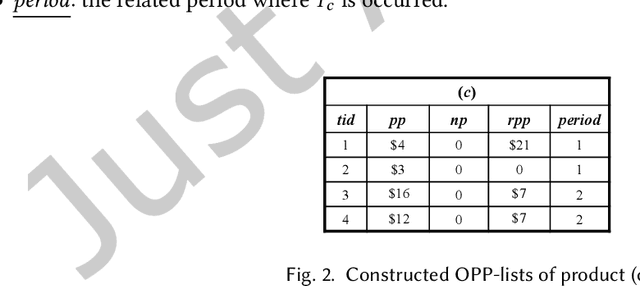
Economic-wise, a common goal for companies conducting marketing is to maximize the return revenue/profit by utilizing the various effective marketing strategies. Consumer behavior is crucially important in economy and targeted marketing, in which behavioral economics can provide valuable insights to identify the biases and profit from customers. Finding credible and reliable information on products' profitability is, however, quite difficult since most products tends to peak at certain times w.r.t. seasonal sales cycle in a year. On-Shelf Availability (OSA) plays a key factor for performance evaluation. Besides, staying ahead of hot product trends means we can increase marketing efforts without selling out the inventory. To fulfill this gap, in this paper, we first propose a general profit-oriented framework to address the problem of revenue maximization based on economic behavior, and compute the 0n-shelf Popular and most Profitable Products (OPPPs) for the targeted marketing. To tackle the revenue maximization problem, we model the k-satisfiable product concept and propose an algorithmic framework for searching OPPP and its variants. Extensive experiments are conducted on several real-world datasets to evaluate the effectiveness and efficiency of the proposed algorithm.
Anomaly Rule Detection in Sequence Data
Nov 29, 2021
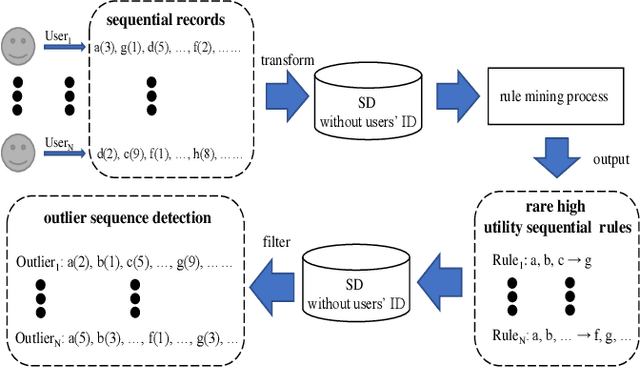


Analyzing sequence data usually leads to the discovery of interesting patterns and then anomaly detection. In recent years, numerous frameworks and methods have been proposed to discover interesting patterns in sequence data as well as detect anomalous behavior. However, existing algorithms mainly focus on frequency-driven analytic, and they are challenging to be applied in real-world settings. In this work, we present a new anomaly detection framework called DUOS that enables Discovery of Utility-aware Outlier Sequential rules from a set of sequences. In this pattern-based anomaly detection algorithm, we incorporate both the anomalousness and utility of a group, and then introduce the concept of utility-aware outlier sequential rule (UOSR). We show that this is a more meaningful way for detecting anomalies. Besides, we propose some efficient pruning strategies w.r.t. upper bounds for mining UOSR, as well as the outlier detection. An extensive experimental study conducted on several real-world datasets shows that the proposed DUOS algorithm has a better effectiveness and efficiency. Finally, DUOS outperforms the baseline algorithm and has a suitable scalability.
Flexible Pattern Discovery and Analysis
Nov 24, 2021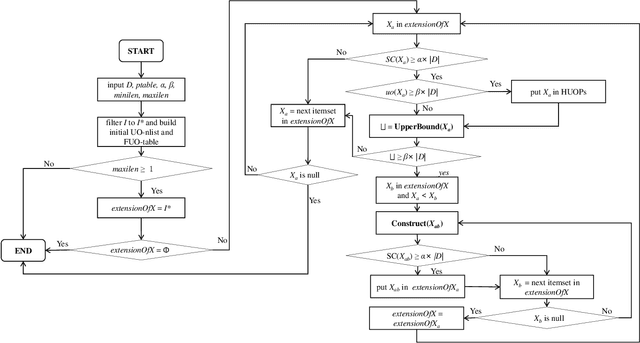
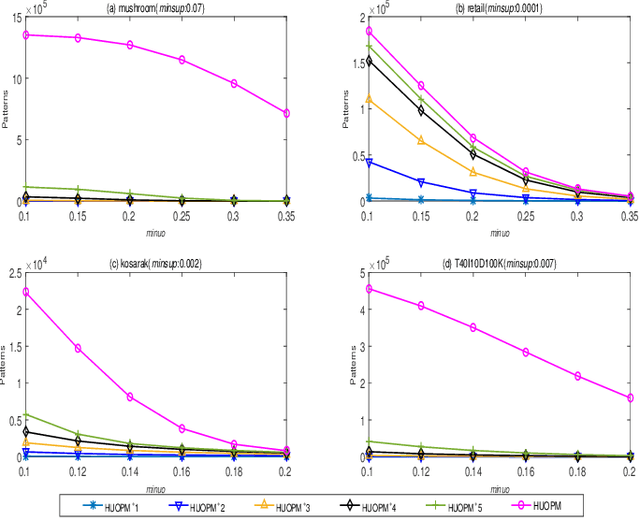
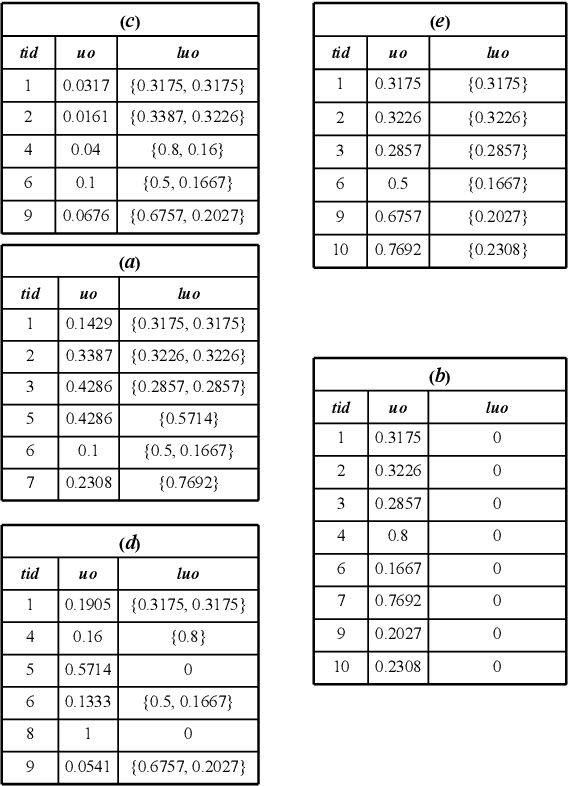
Based on the analysis of the proportion of utility in the supporting transactions used in the field of data mining, high utility-occupancy pattern mining (HUOPM) has recently attracted widespread attention. Unlike high-utility pattern mining (HUPM), which involves the enumeration of high-utility (e.g., profitable) patterns, HUOPM aims to find patterns representing a collection of existing transactions. In practical applications, however, not all patterns are used or valuable. For example, a pattern might contain too many items, that is, the pattern might be too specific and therefore lack value for users in real life. To achieve qualified patterns with a flexible length, we constrain the minimum and maximum lengths during the mining process and introduce a novel algorithm for the mining of flexible high utility-occupancy patterns. Our algorithm is referred to as HUOPM+. To ensure the flexibility of the patterns and tighten the upper bound of the utility-occupancy, a strategy called the length upper-bound (LUB) is presented to prune the search space. In addition, a utility-occupancy nested list (UO-nlist) and a frequency-utility-occupancy table (FUO-table) are employed to avoid multiple scans of the database. Evaluation results of the subsequent experiments confirm that the proposed algorithm can effectively control the length of the derived patterns, for both real-world and synthetic datasets. Moreover, it can decrease the execution time and memory consumption.