 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmics-scale polymer computational database transferable to real-world artificial intelligence applications
Nov 07, 2025Developing large-scale foundational datasets is a critical milestone in advancing artificial intelligence (AI)-driven scientific innovation. However, unlike AI-mature fields such as natural language processing, materials science, particularly polymer research, has significantly lagged in developing extensive open datasets. This lag is primarily due to the high costs of polymer synthesis and property measurements, along with the vastness and complexity of the chemical space. This study presents PolyOmics, an omics-scale computational database generated through fully automated molecular dynamics simulation pipelines that provide diverse physical properties for over $10^5$ polymeric materials. The PolyOmics database is collaboratively developed by approximately 260 researchers from 48 institutions to bridge the gap between academia and industry. Machine learning models pretrained on PolyOmics can be efficiently fine-tuned for a wide range of real-world downstream tasks, even when only limited experimental data are available. Notably, the generalisation capability of these simulation-to-real transfer models improve significantly as the size of the PolyOmics database increases, exhibiting power-law scaling. The emergence of scaling laws supports the "more is better" principle, highlighting the significance of ultralarge-scale computational materials data for improving real-world prediction performance. This unprecedented omics-scale database reveals vast unexplored regions of polymer materials, providing a foundation for AI-driven polymer science.
Synergistic Fusion of Multi-Source Knowledge via Evidence Theory for High-Entropy Alloy Discovery
Feb 20, 2025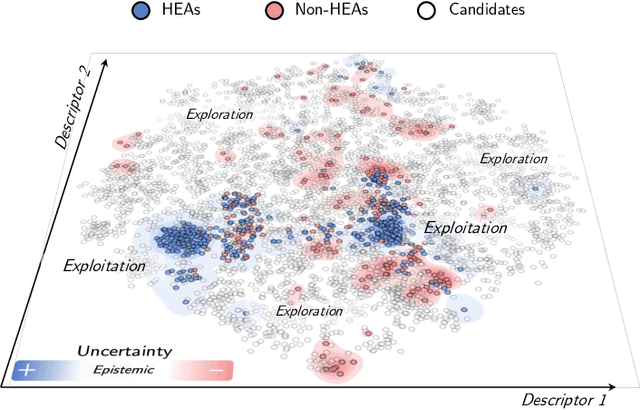



Discovering novel high-entropy alloys (HEAs) with desirable properties is challenging due to the vast compositional space and complex phase formation mechanisms. Efficient exploration of this space requires a strategic approach that integrates heterogeneous knowledge sources. Here, we propose a framework that systematically combines knowledge extracted from computational material datasets with domain knowledge distilled from scientific literature using large language models (LLMs). A central feature of this approach is the explicit consideration of element substitutability, identifying chemically similar elements that can be interchanged to potentially stabilize desired HEAs. Dempster-Shafer theory, a mathematical framework for reasoning under uncertainty, is employed to model and combine substitutabilities based on aggregated evidence from multiple sources. The framework predicts the phase stability of candidate HEA compositions and is systematically evaluated on both quaternary alloy systems, demonstrating superior performance compared to baseline machine learning models and methods reliant on single-source evidence in cross-validation experiments. By leveraging multi-source knowledge, the framework retains robust predictive power even when key elements are absent from the training data, underscoring its potential for knowledge transfer and extrapolation. Furthermore, the enhanced interpretability of the methodology offers insights into the fundamental factors governing HEA formation. Overall, this work provides a promising strategy for accelerating HEA discovery by integrating computational and textual knowledge sources, enabling efficient exploration of vast compositional spaces with improved generalization and interpretability.
Function Decomposition Tree with Causality-First Perspective and Systematic Description of Problems in Materials Informatics
Apr 26, 2022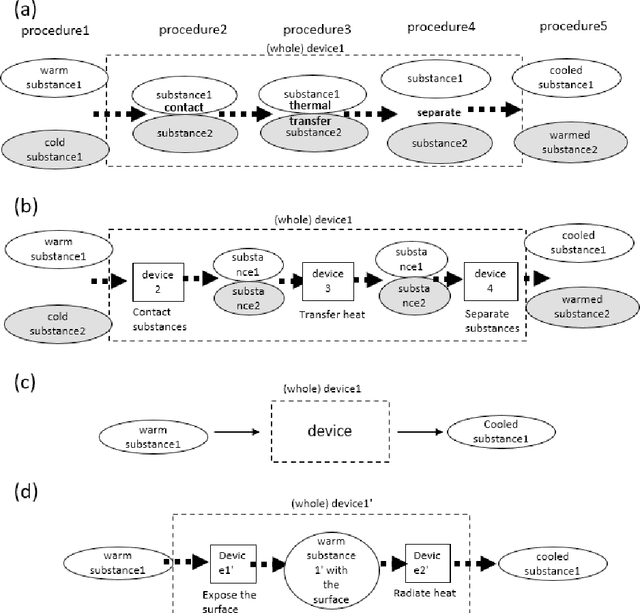
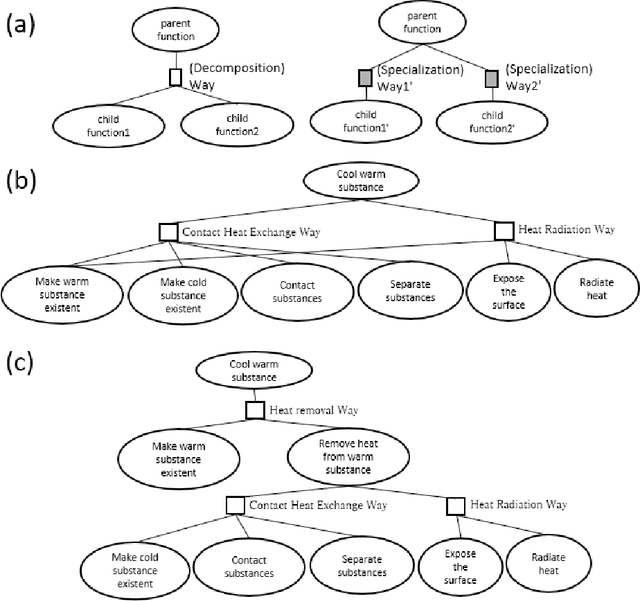
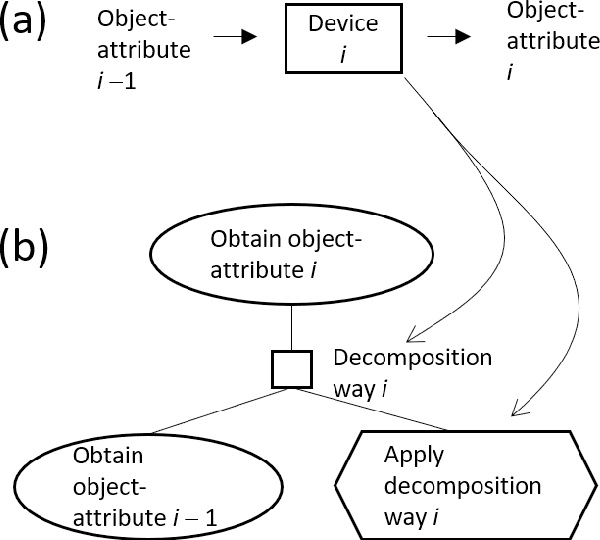

As interdisciplinary science is flourishing because of materials informatics and additional factors; a systematic way is required for expressing knowledge and facilitating communication between scientists in various fields. A function decomposition tree is such a representation, but domain scientists face difficulty in constructing it. Thus, this study cites the general problems encountered by beginners in generating function decomposition trees and proposes a new function decomposition representation method based on a causality-first perspective for resolution of these problems. The causality-first decomposition tree was obtained from a workflow expressed according to the processing sequence. Moreover, we developed a program that performed automatic conversion using the features of the causality-first decomposition trees. The proposed method was applied to materials informatics to demonstrate the systematic representation of expert knowledge and its usefullness.
Ensemble learning reveals dissimilarity between rare-earth transition metal binary alloys with respect to the Curie temperature
Aug 20, 2020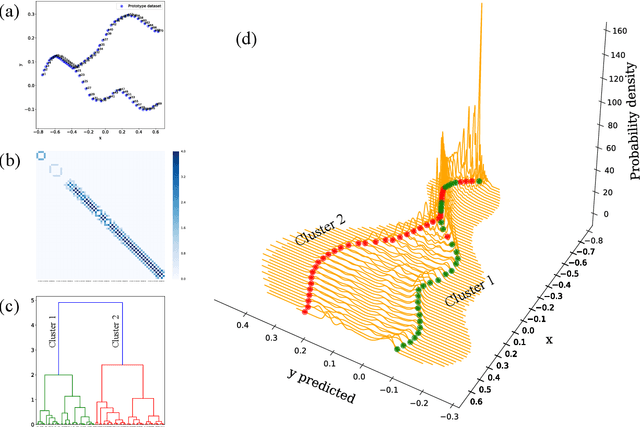
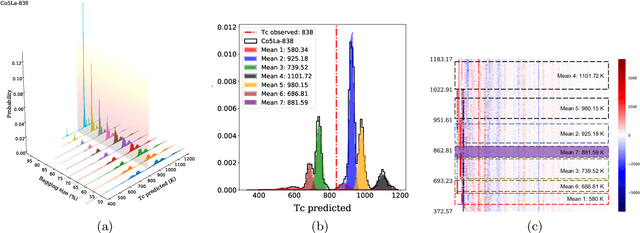
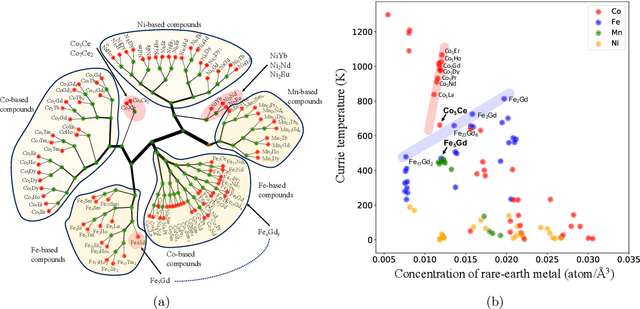
We propose a data-driven method to extract dissimilarity between materials, with respect to a given target physical property. The technique is based on an ensemble method with Kernel ridge regression as the predicting model; multiple random subset sampling of the materials is done to generate prediction models and the corresponding contributions of the reference training materials in detail. The distribution of the predicted values for each material can be approximated by a Gaussian mixture model. The reference training materials contributed to the prediction model that accurately predicts the physical property value of a specific material, are considered to be similar to that material, or vice versa. Evaluations using synthesized data demonstrate that the proposed method can effectively measure the dissimilarity between data instances. An application of the analysis method on the data of Curie temperature (TC) of binary 3d transition metal 4f rare earth binary alloys also reveals meaningful results on the relations between the materials. The proposed method can be considered as a potential tool for obtaining a deeper understanding of the structure of data, with respect to a target property, in particular.
Measuring the Similarity between Materials with an Emphasis on the Materials Distinctiveness
Mar 23, 2019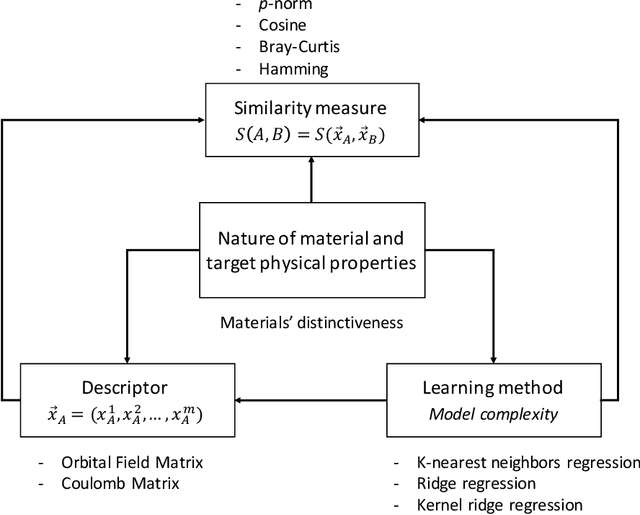
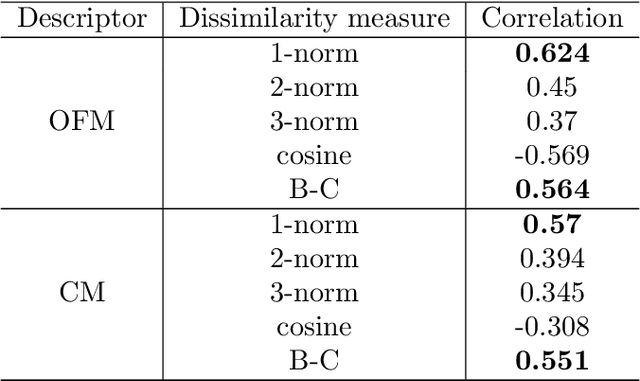
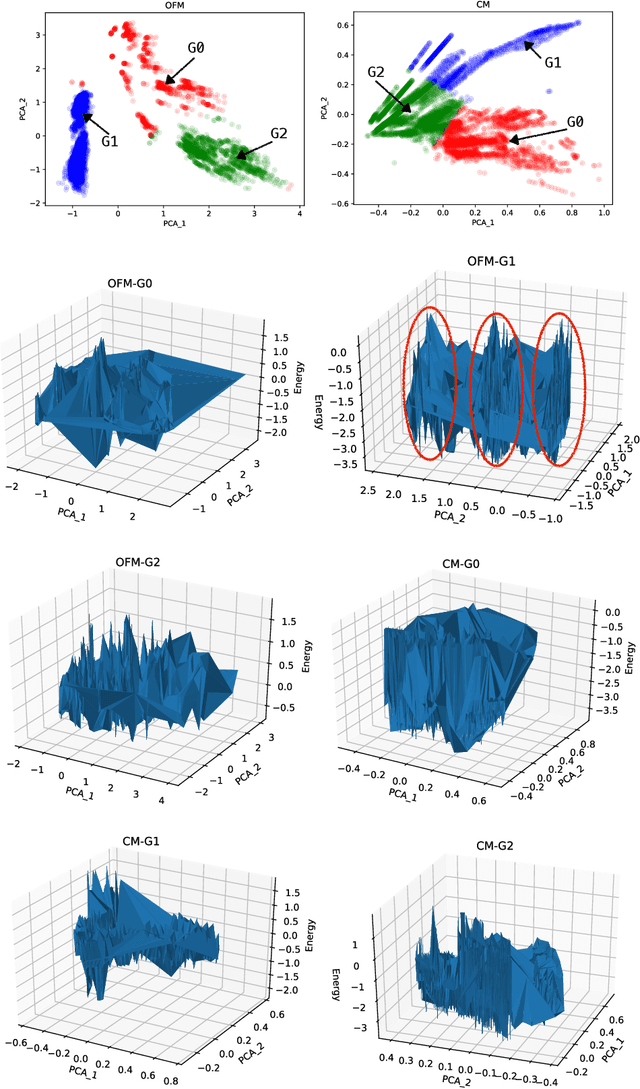

In this study, we establish a basis for selecting similarity measures when applying machine learning techniques to solve materials science problems. This selection is considered with an emphasis on the distinctiveness between materials that reflect their nature well. We perform a case study with a dataset of rare-earth transition metal crystalline compounds represented using the Orbital Field Matrix descriptor and the Coulomb Matrix descriptor. We perform predictions of the formation energies using k-nearest neighbors regression, ridge regression, and kernel ridge regression. Through detailed analyses of the yield prediction accuracy, we examine the relationship between the characteristics of the material representation and similarity measures, and the complexity of the energy function they can capture. Empirical experiments and theoretical analysis reveal that similarity measures and kernels that minimize the loss of materials distinctiveness improve the prediction performance.