 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonmyopic Gaussian Process Optimization with Macro-Actions
Paper and Code
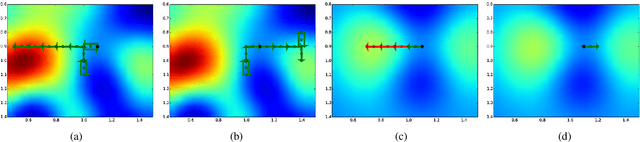
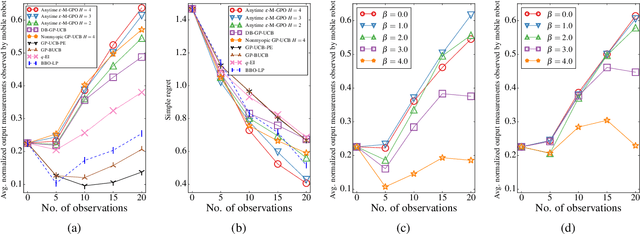
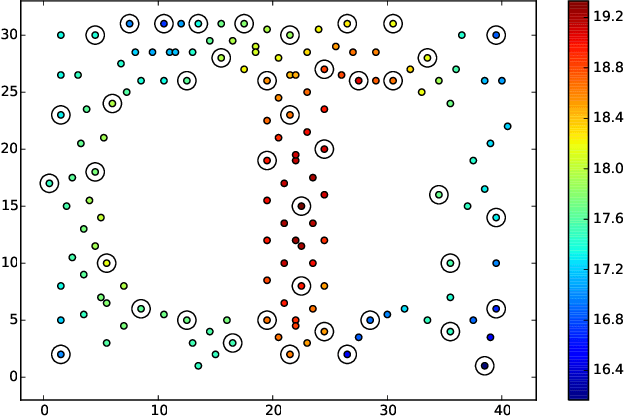
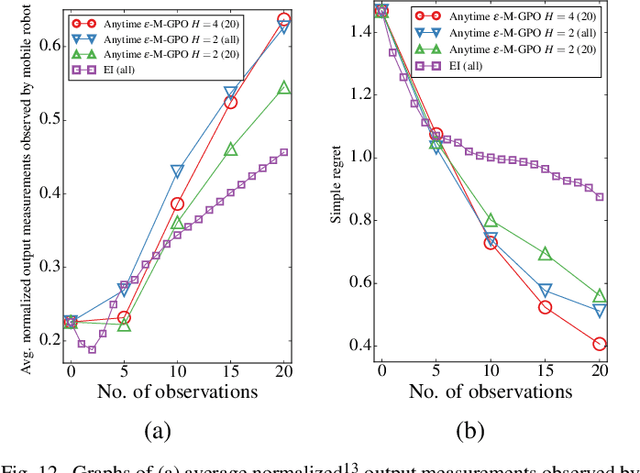
This paper presents a multi-staged approach to nonmyopic adaptive Gaussian process optimization (GPO) for Bayesian optimization (BO) of unknown, highly complex objective functions that, in contrast to existing nonmyopic adaptive BO algorithms, exploits the notion of macro-actions for scaling up to a further lookahead to match up to a larger available budget. To achieve this, we generalize GP upper confidence bound to a new acquisition function defined w.r.t. a nonmyopic adaptive macro-action policy, which is intractable to be optimized exactly due to an uncountable set of candidate outputs. The contribution of our work here is thus to derive a nonmyopic adaptive epsilon-Bayes-optimal macro-action GPO (epsilon-Macro-GPO) policy. To perform nonmyopic adaptive BO in real time, we then propose an asymptotically optimal anytime variant of our epsilon-Macro-GPO policy with a performance guarantee. We empirically evaluate the performance of our epsilon-Macro-GPO policy and its anytime variant in BO with synthetic and real-world datasets.