 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecFwT: Efficient Privacy-Preserving Fine-Tuning of Large Language Models Using Forward-Only Passes
Jun 18, 2025Large language models (LLMs) have transformed numerous fields, yet their adaptation to specialized tasks in privacy-sensitive domains, such as healthcare and finance, is constrained by the scarcity of accessible training data due to stringent privacy requirements. Secure multi-party computation (MPC)-based privacy-preserving machine learning offers a powerful approach to protect both model parameters and user data, but its application to LLMs has been largely limited to inference, as fine-tuning introduces significant computational challenges, particularly in privacy-preserving backward propagation and optimizer operations. This paper identifies two primary obstacles to MPC-based privacy-preserving fine-tuning of LLMs: (1) the substantial computational overhead of backward and optimizer processes, and (2) the inefficiency of softmax-based attention mechanisms in MPC settings. To address these challenges, we propose SecFwT, the first MPC-based framework designed for efficient, privacy-preserving LLM fine-tuning. SecFwT introduces a forward-only tuning paradigm to eliminate backward and optimizer computations and employs MPC-friendly Random Feature Attention to approximate softmax attention, significantly reducing costly non-linear operations and computational complexity. Experimental results demonstrate that SecFwT delivers substantial improvements in efficiency and privacy preservation, enabling scalable and secure fine-tuning of LLMs for privacy-critical applications.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
Centaur: Bridging the Impossible Trinity of Privacy, Efficiency, and Performance in Privacy-Preserving Transformer Inference
Dec 14, 2024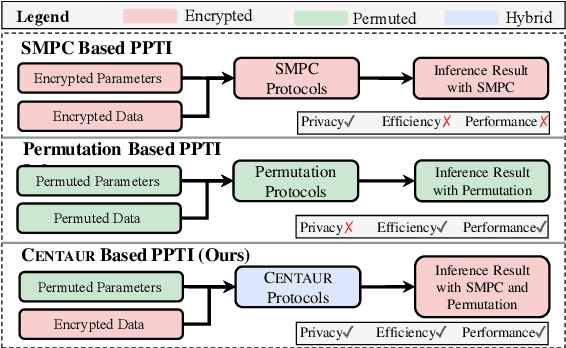
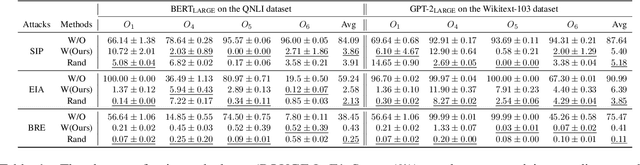
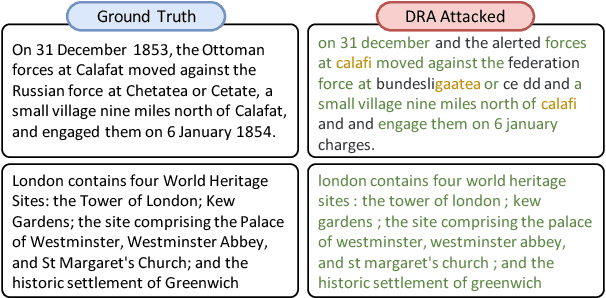
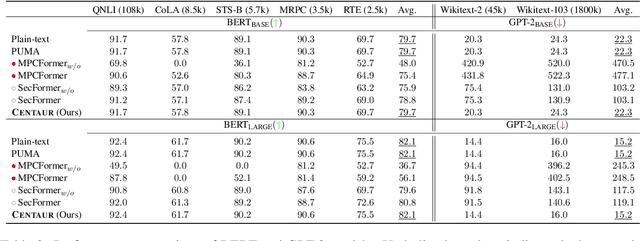
As pre-trained models, like Transformers, are increasingly deployed on cloud platforms for inference services, the privacy concerns surrounding model parameters and inference data are becoming more acute. Current Privacy-Preserving Transformer Inference (PPTI) frameworks struggle with the "impossible trinity" of privacy, efficiency, and performance. For instance, Secure Multi-Party Computation (SMPC)-based solutions offer strong privacy guarantees but come with significant inference overhead and performance trade-offs. On the other hand, PPTI frameworks that use random permutations achieve inference efficiency close to that of plaintext and maintain accurate results but require exposing some model parameters and intermediate results, thereby risking substantial privacy breaches. Addressing this "impossible trinity" with a single technique proves challenging. To overcome this challenge, we propose Centaur, a novel hybrid PPTI framework. Unlike existing methods, Centaur protects model parameters with random permutations and inference data with SMPC, leveraging the structure of Transformer models. By designing a series of efficient privacy-preserving algorithms, Centaur leverages the strengths of both techniques to achieve a better balance between privacy, efficiency, and performance in PPTI. We comprehensively evaluate the effectiveness of Centaur on various types of Transformer models and datasets. Experimental results demonstrate that the privacy protection capabilities offered by Centaur can withstand various existing model inversion attack methods. In terms of performance and efficiency, Centaur not only maintains the same performance as plaintext inference but also improves inference speed by $5.0-30.4$ times.
Incentives in Private Collaborative Machine Learning
Apr 02, 2024Collaborative machine learning involves training models on data from multiple parties but must incentivize their participation. Existing data valuation methods fairly value and reward each party based on shared data or model parameters but neglect the privacy risks involved. To address this, we introduce differential privacy (DP) as an incentive. Each party can select its required DP guarantee and perturb its sufficient statistic (SS) accordingly. The mediator values the perturbed SS by the Bayesian surprise it elicits about the model parameters. As our valuation function enforces a privacy-valuation trade-off, parties are deterred from selecting excessive DP guarantees that reduce the utility of the grand coalition's model. Finally, the mediator rewards each party with different posterior samples of the model parameters. Such rewards still satisfy existing incentives like fairness but additionally preserve DP and a high similarity to the grand coalition's posterior. We empirically demonstrate the effectiveness and practicality of our approach on synthetic and real-world datasets.
COPR: Continual Human Preference Learning via Optimal Policy Regularization
Feb 27, 2024Reinforcement Learning from Human Feedback (RLHF) is commonly utilized to improve the alignment of Large Language Models (LLMs) with human preferences. Given the evolving nature of human preferences, continual alignment becomes more crucial and practical in comparison to traditional static alignment. Nevertheless, making RLHF compatible with Continual Learning (CL) is challenging due to its complex process. Meanwhile, directly learning new human preferences may lead to Catastrophic Forgetting (CF) of historical preferences, resulting in helpless or harmful outputs. To overcome these challenges, we propose the Continual Optimal Policy Regularization (COPR) method, which draws inspiration from the optimal policy theory. COPR utilizes a sampling distribution as a demonstration and regularization constraints for CL. It adopts the Lagrangian Duality (LD) method to dynamically regularize the current policy based on the historically optimal policy, which prevents CF and avoids over-emphasizing unbalanced objectives. We also provide formal proof for the learnability of COPR. The experimental results show that COPR outperforms strong CL baselines on our proposed benchmark, in terms of reward-based, GPT-4 evaluations and human assessment. Furthermore, we validate the robustness of COPR under various CL settings, including different backbones, replay memory sizes, and learning orders.
SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models
Jan 06, 2024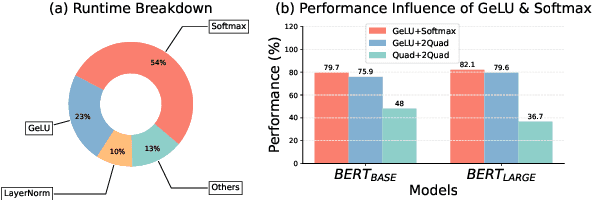
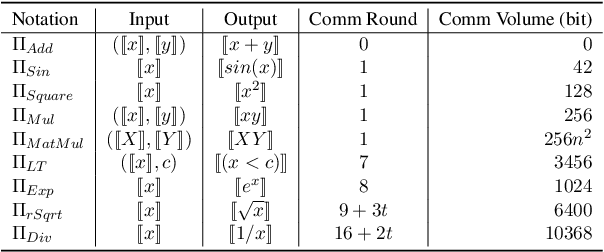
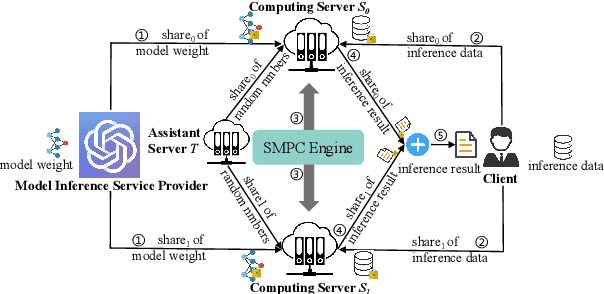
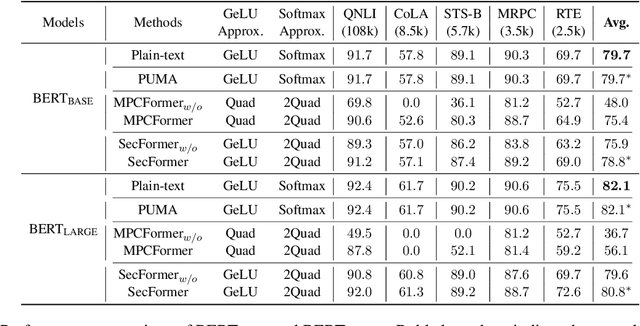
With the growing use of large language models hosted on cloud platforms to offer inference services, privacy concerns are escalating, especially concerning sensitive data like investment plans and bank account details. Secure Multi-Party Computing (SMPC) emerges as a promising solution to protect the privacy of inference data and model parameters. However, the application of SMPC in Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often leads to considerable slowdowns or declines in performance. This is largely due to the multitude of nonlinear operations in the Transformer architecture, which are not well-suited to SMPC and difficult to circumvent or optimize effectively. To address this concern, we introduce an advanced optimization framework called SecFormer, to achieve fast and accurate PPI for Transformer models. By implementing model design optimization, we successfully eliminate the high-cost exponential and maximum operations in PPI without sacrificing model performance. Additionally, we have developed a suite of efficient SMPC protocols that utilize segmented polynomials, Fourier series and Goldschmidt's method to handle other complex nonlinear functions within PPI, such as GeLU, LayerNorm, and Softmax. Our extensive experiments reveal that SecFormer outperforms MPCFormer in performance, showing improvements of $5.6\%$ and $24.2\%$ for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, respectively. In terms of efficiency, SecFormer is 3.56 and 3.58 times faster than Puma for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, demonstrating its effectiveness and speed.
EncryIP: A Practical Encryption-Based Framework for Model Intellectual Property Protection
Dec 19, 2023

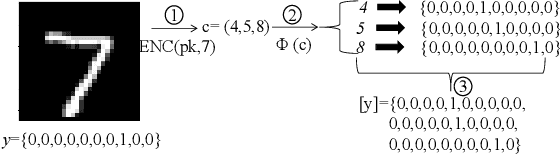

In the rapidly growing digital economy, protecting intellectual property (IP) associated with digital products has become increasingly important. Within this context, machine learning (ML) models, being highly valuable digital assets, have gained significant attention for IP protection. This paper introduces a practical encryption-based framework called \textit{EncryIP}, which seamlessly integrates a public-key encryption scheme into the model learning process. This approach enables the protected model to generate randomized and confused labels, ensuring that only individuals with accurate secret keys, signifying authorized users, can decrypt and reveal authentic labels. Importantly, the proposed framework not only facilitates the protected model to multiple authorized users without requiring repetitive training of the original ML model with IP protection methods but also maintains the model's performance without compromising its accuracy. Compared to existing methods like watermark-based, trigger-based, and passport-based approaches, \textit{EncryIP} demonstrates superior effectiveness in both training protected models and efficiently detecting the unauthorized spread of ML models.
Hessian-Aware Bayesian Optimization for Decision Making Systems
Aug 17, 2023



Many approaches for optimizing decision making systems rely on gradient based methods requiring informative feedback from the environment. However, in the case where such feedback is sparse or uninformative, such approaches may result in poor performance. Derivative-free approaches such as Bayesian Optimization mitigate the dependency on the quality of gradient feedback, but are known to scale poorly in the high-dimension setting of complex decision making systems. This problem is exacerbated if the system requires interactions between several actors cooperating to accomplish a shared goal. To address the dimensionality challenge, we propose a compact multi-layered architecture modeling the dynamics of actor interactions through the concept of role. Additionally, we introduce Hessian-aware Bayesian Optimization to efficiently optimize the multi-layered architecture parameterized by a large number of parameters. Experimental results demonstrate that our method (HA-GP-UCB) works effectively on several benchmarks under resource constraints and malformed feedback settings.
Model Provenance via Model DNA
Aug 04, 2023Understanding the life cycle of the machine learning (ML) model is an intriguing area of research (e.g., understanding where the model comes from, how it is trained, and how it is used). This paper focuses on a novel problem within this field, namely Model Provenance (MP), which concerns the relationship between a target model and its pre-training model and aims to determine whether a source model serves as the provenance for a target model. This is an important problem that has significant implications for ensuring the security and intellectual property of machine learning models but has not received much attention in the literature. To fill in this gap, we introduce a novel concept of Model DNA which represents the unique characteristics of a machine learning model. We utilize a data-driven and model-driven representation learning method to encode the model's training data and input-output information as a compact and comprehensive representation (i.e., DNA) of the model. Using this model DNA, we develop an efficient framework for model provenance identification, which enables us to identify whether a source model is a pre-training model of a target model. We conduct evaluations on both computer vision and natural language processing tasks using various models, datasets, and scenarios to demonstrate the effectiveness of our approach in accurately identifying model provenance.
Practical Privacy-Preserving Gaussian Process Regression via Secret Sharing
Jun 26, 2023Gaussian process regression (GPR) is a non-parametric model that has been used in many real-world applications that involve sensitive personal data (e.g., healthcare, finance, etc.) from multiple data owners. To fully and securely exploit the value of different data sources, this paper proposes a privacy-preserving GPR method based on secret sharing (SS), a secure multi-party computation (SMPC) technique. In contrast to existing studies that protect the data privacy of GPR via homomorphic encryption, differential privacy, or federated learning, our proposed method is more practical and can be used to preserve the data privacy of both the model inputs and outputs for various data-sharing scenarios (e.g., horizontally/vertically-partitioned data). However, it is non-trivial to directly apply SS on the conventional GPR algorithm, as it includes some operations whose accuracy and/or efficiency have not been well-enhanced in the current SMPC protocol. To address this issue, we derive a new SS-based exponentiation operation through the idea of 'confusion-correction' and construct an SS-based matrix inversion algorithm based on Cholesky decomposition. More importantly, we theoretically analyze the communication cost and the security of the proposed SS-based operations. Empirical results show that our proposed method can achieve reasonable accuracy and efficiency under the premise of preserving data privacy.