 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
Jan 27, 2026Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.
Short Wins Long: Short Codes with Language Model Semantic Correction Outperform Long Codes
May 13, 2025This paper presents a novel semantic-enhanced decoding scheme for transmitting natural language sentences with multiple short block codes over noisy wireless channels. After ASCII source coding, the natural language sentence message is divided into segments, where each is encoded with short block channel codes independently before transmission. At the receiver, each short block of codewords is decoded in parallel, followed by a semantic error correction (SEC) model to reconstruct corrupted segments semantically. We design and train the SEC model based on Bidirectional and Auto-Regressive Transformers (BART). Simulations demonstrate that the proposed scheme can significantly outperform encoding the sentence with one conventional long LDPC code, in terms of block error rate (BLER), semantic metrics, and decoding latency. Finally, we proposed a semantic hybrid automatic repeat request (HARQ) scheme to further enhance the error performance, which selectively requests retransmission depends on semantic uncertainty.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
RS-vHeat: Heat Conduction Guided Efficient Remote Sensing Foundation Model
Nov 27, 2024Remote sensing foundation models largely break away from the traditional paradigm of designing task-specific models, offering greater scalability across multiple tasks. However, they face challenges such as low computational efficiency and limited interpretability, especially when dealing with high-resolution remote sensing images. To overcome these, we draw inspiration from heat conduction, a physical process modeling local heat diffusion. Building on this idea, we are the first to explore the potential of using the parallel computing model of heat conduction to simulate the local region correlations in high-resolution remote sensing images, and introduce RS-vHeat, an efficient multi-modal remote sensing foundation model. Specifically, RS-vHeat 1) applies the Heat Conduction Operator (HCO) with a complexity of $O(N^{1.5})$ and a global receptive field, reducing computational overhead while capturing remote sensing object structure information to guide heat diffusion; 2) learns the frequency distribution representations of various scenes through a self-supervised strategy based on frequency domain hierarchical masking and multi-domain reconstruction; 3) significantly improves efficiency and performance over state-of-the-art techniques across 4 tasks and 10 datasets. Compared to attention-based remote sensing foundation models, we reduces memory consumption by 84%, decreases FLOPs by 24% and improves throughput by 2.7 times.
Approaching Maximum Likelihood Performance via End-to-End Learning in MU-MIMO Systems
Nov 25, 2024



Multi-user multiple-input multiple-output (MU-MIMO) systems allow multiple users to share the same wireless spectrum. Each user transmits one symbol drawn from an M-ary quadrature amplitude modulation (M-QAM) constellation set, and the resulting multi-user interference (MUI) is cancelled at the receiver. End-to-End (E2E) learning has recently been proposed to jointly design the constellation set for a modulator and symbol detector for a single user under an additive white Gaussian noise (AWGN) channel by using deep neural networks (DNN) with a symbol-error-rate (SER) performance, exceeding that of Maximum likelihood (ML) M-QAM detectors. In this paper, we extend the E2E concept to the MU-MIMO systems, where a DNN-based modulator that generates learned M constellation points and graph expectation propagation network (GEPNet) detector that cancels MUI are jointly optimised with respect to SER performance loss. Simulation results demonstrate that the proposed E2E with learned constellation outperforms GEPNet with 16-QAM by around 5 dB in terms of SER in a high MUI environment and even surpasses ML with 16-QAM in a low MUI condition, both with no additional computational complexity.
Graph-based Untrained Neural Network Detector for OTFS Systems
Apr 08, 2024
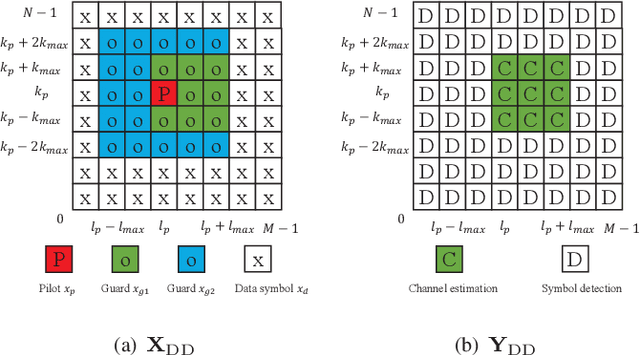
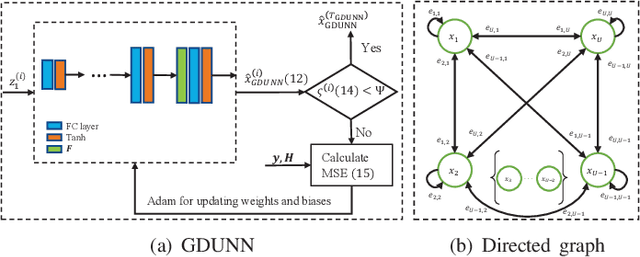

Inter-carrier interference (ICI) caused by mobile reflectors significantly degrades the conventional orthogonal frequency division multiplexing (OFDM) performance in high-mobility environments. The orthogonal time frequency space (OTFS) modulation system effectively represents ICI in the delay-Doppler domain, thus significantly outperforming OFDM. Existing iterative and neural network (NN) based OTFS detectors suffer from high complex matrix operations and performance degradation in untrained environments, where the real wireless channel does not match the one used in the training, which often happens in real wireless networks. In this paper, we propose to embed the prior knowledge of interference extracted from the estimated channel state information (CSI) as a directed graph into a decoder untrained neural network (DUNN), namely graph-based DUNN (GDUNN). We then combine it with Bayesian parallel interference cancellation (BPIC) for OTFS symbol detection, resulting in GDUNN-BPIC. Simulation results show that the proposed GDUNN-BPIC outperforms state-of-the-art OTFS detectors under imperfect CSI.
See SIFT in a Rain
Nov 01, 2023Rain streaks bring complicated pixel intensity changes and additional gradients, greatly obstructing the extraction of image features from background. This causes serious performance degradation in feature-based applications. Thus, it is critical to remove rain streaks from a single rainy image to recover image features. Recently, many excellent image deraining methods have made remarkable progress. However, these human visual system-driven approaches mainly focus on improving image quality with pixel recovery as loss function, and neglect how to enhance image feature recovery ability. To address this issue, we propose a task-driven image deraining algorithm to strengthen image feature supply for subsequent feature-based applications. Due to the extensive use and strong practicability of Scale-Invariant Feature Transform (SIFT), we first propose two separate networks using distinct losses and modules to achieve two goals, respectively. One is difference of Gaussian (DoG) pyramid recovery network (DPRNet) for SIFT detection, and the other gradients of Gaussian images recovery network (GGIRNet) for SIFT description. Second, in the DPRNet we propose an alternative interest point loss that directly penalizes scale response extrema to recover the DoG pyramid. Third, we advance a gradient attention module in the GGIRNet to recover those gradients of Gaussian images. Finally, with the recovered DoG pyramid and gradients, we can regain SIFT key points. This divide-and-conquer scheme to set different objectives for SIFT detection and description leads to good robustness. Compared with state-of-the-art methods, experimental results demonstrate that our proposed algorithm achieves better performance in both the number of recovered SIFT key points and their accuracy.
* A direct DoG feature pyramid recovery from rainy pixels solution for SIFT detection, accepted by T-CSVT, 2023
Untrained Neural Network based Bayesian Detector for OTFS Modulation Systems
May 08, 2023The orthogonal time frequency space (OTFS) symbol detector design for high mobility communication scenarios has received numerous attention lately. Current state-of-the-art OTFS detectors mainly can be divided into two categories; iterative and training-based deep neural network (DNN) detectors. Many practical iterative detectors rely on minimum-mean-square-error (MMSE) denoiser to get the initial symbol estimates. However, their computational complexity increases exponentially with the number of detected symbols. Training-based DNN detectors typically suffer from dependency on the availability of large computation resources and the fidelity of synthetic datasets for the training phase, which are both costly. In this paper, we propose an untrained DNN based on the deep image prior (DIP) and decoder architecture, referred to as D-DIP that replaces the MMSE denoiser in the iterative detector. DIP is a type of DNN that requires no training, which makes it beneficial in OTFS detector design. Then we propose to combine the D-DIP denoiser with the Bayesian parallel interference cancellation (BPIC) detector to perform iterative symbol detection, referred to as D-DIP-BPIC. Our simulation results show that the symbol error rate (SER) performance of the proposed D-DIP-BPIC detector outperforms practical state-of-the-art detectors by 0.5 dB and retains low computational complexity.
Scene Clustering Based Pseudo-labeling Strategy for Multi-modal Aerial View Object Classification
May 19, 2022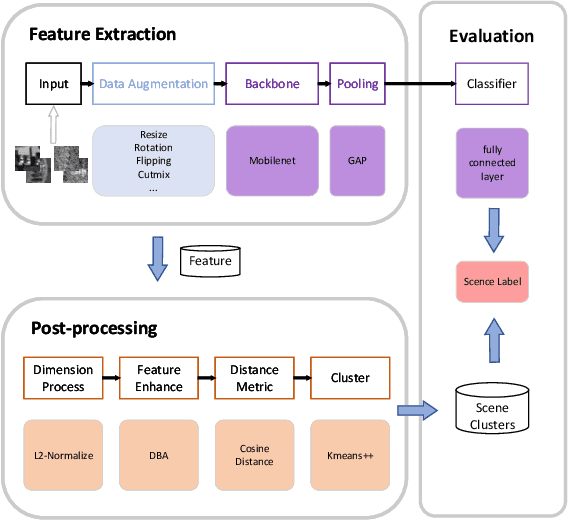
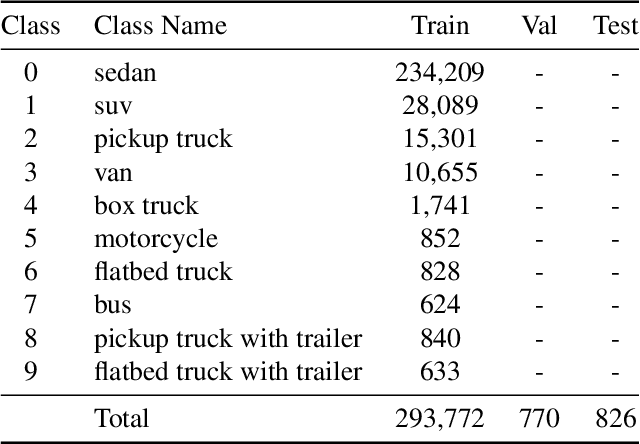
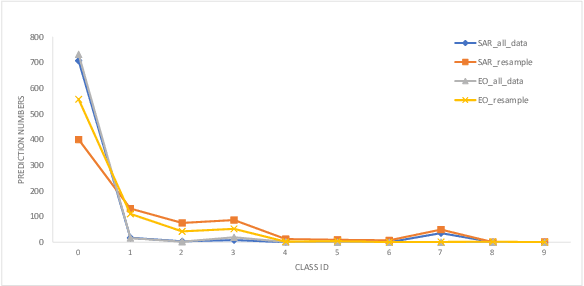

Multi-modal aerial view object classification (MAVOC) in Automatic target recognition (ATR), although an important and challenging problem, has been under studied. This paper firstly finds that fine-grained data, class imbalance and various shooting conditions preclude the representational ability of general image classification. Moreover, the MAVOC dataset has scene aggregation characteristics. By exploiting these properties, we propose Scene Clustering Based Pseudo-labeling Strategy (SCP-Label), a simple yet effective method to employ in post-processing. The SCP-Label brings greater accuracy by assigning the same label to objects within the same scene while also mitigating bias and confusion with model ensembles. Its performance surpasses the official baseline by a large margin of +20.57% Accuracy on Track 1 (SAR), and +31.86% Accuracy on Track 2 (SAR+EO), demonstrating the potential of SCP-Label as post-processing. Finally, we win the championship both on Track1 and Track2 in the CVPR 2022 Perception Beyond the Visible Spectrum (PBVS) Workshop MAVOC Challenge. Our code is available at https://github.com/HowieChangchn/SCP-Label.
BiSTF: Bilateral-Branch Self-Training Framework for Semi-Supervised Large-scale Fine-Grained Recognition
Jul 14, 2021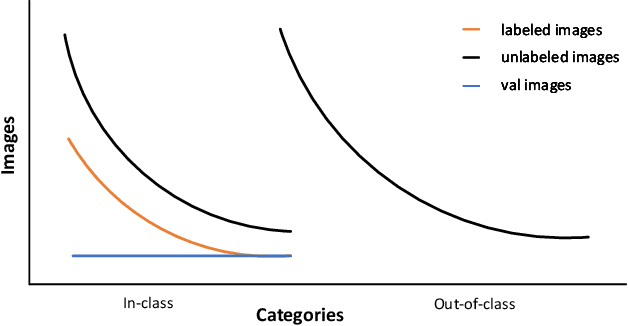
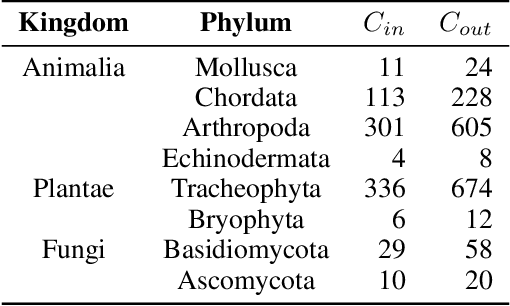
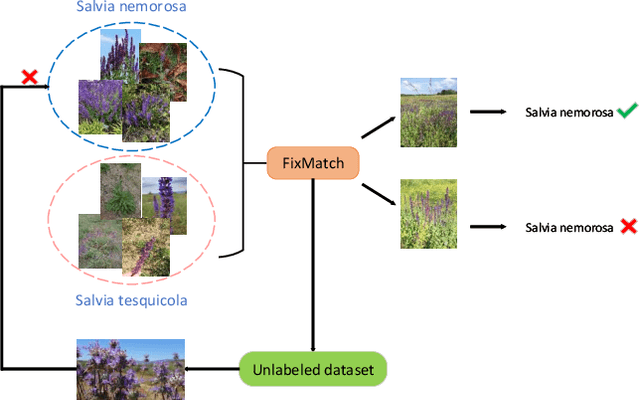
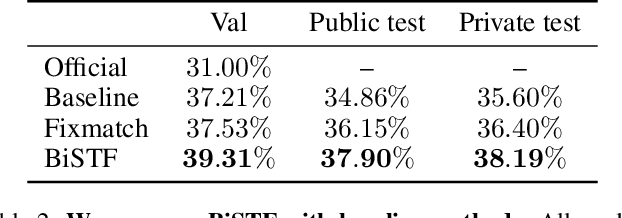
Semi-supervised Fine-Grained Recognition is a challenge task due to the difficulty of data imbalance, high inter-class similarity and domain mismatch. Recent years, this field has witnessed great progress and many methods has gained great performance. However, these methods can hardly generalize to the large-scale datasets, such as Semi-iNat, as they are prone to suffer from noise in unlabeled data and the incompetence for learning features from imbalanced fine-grained data. In this work, we propose Bilateral-Branch Self-Training Framework (BiSTF), a simple yet effective framework to improve existing semi-supervised learning methods on class-imbalanced and domain-shifted fine-grained data. By adjusting the update frequency through stochastic epoch update, BiSTF iteratively retrains a baseline SSL model with a labeled set expanded by selectively adding pseudo-labeled samples from an unlabeled set, where the distribution of pseudo-labeled samples are the same as the labeled data. We show that BiSTF outperforms the existing state-of-the-art SSL algorithm on Semi-iNat dataset.