 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Indoor to Open World: Revealing the Spatial Reasoning Gap in MLLMs
Dec 22, 2025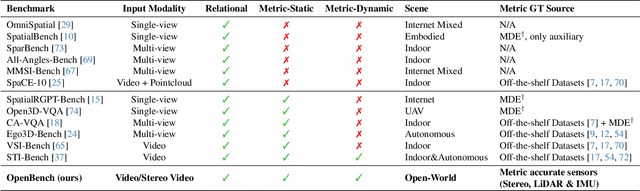

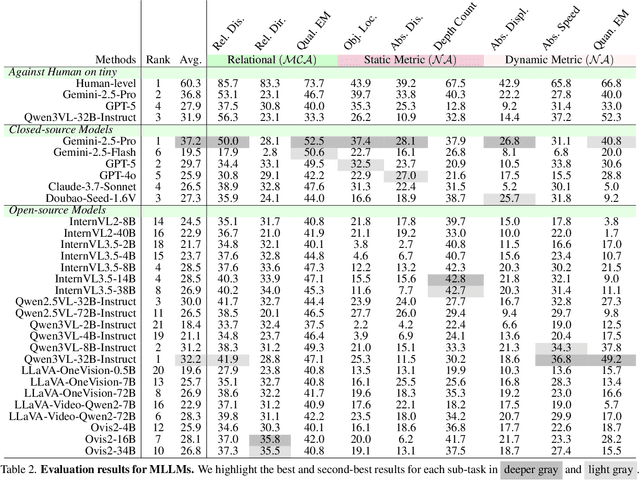
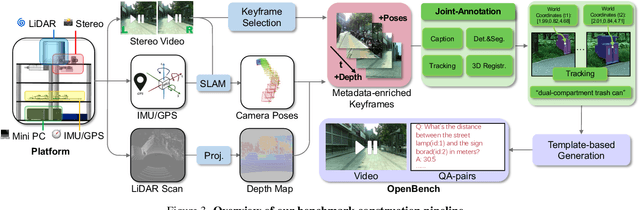
While Multimodal Large Language Models (MLLMs) have achieved impressive performance on semantic tasks, their spatial intelligence--crucial for robust and grounded AI systems--remains underdeveloped. Existing benchmarks fall short of diagnosing this limitation: they either focus on overly simplified qualitative reasoning or rely on domain-specific indoor data, constrained by the lack of outdoor datasets with verifiable metric ground truth. To bridge this gap, we introduce a large-scale benchmark built from pedestrian-perspective videos captured with synchronized stereo cameras, LiDAR, and IMU/GPS sensors. This dataset provides metrically precise 3D information, enabling the automatic generation of spatial reasoning questions that span a hierarchical spectrum--from qualitative relational reasoning to quantitative metric and kinematic understanding. Evaluations reveal that the performance gains observed in structured indoor benchmarks vanish in open-world settings. Further analysis using synthetic abnormal scenes and blinding tests confirms that current MLLMs depend heavily on linguistic priors instead of grounded visual reasoning. Our benchmark thus provides a principled platform for diagnosing these limitations and advancing physically grounded spatial intelligence.
Mixture of Physical Priors Adapter for Parameter-Efficient Fine-Tuning
Dec 03, 2024



Most parameter-efficient fine-tuning (PEFT) methods rely on low-rank representations to adapt models. However, these approaches often oversimplify representations, particularly when the underlying data has high-rank or high-frequency components. This limitation hinders the model's ability to capture complex data interactions effectively. In this paper, we propose a novel approach that models network weights by leveraging a combination of physical priors, enabling more accurate approximations. We use three foundational equations -- heat diffusion, wave propagation, and Poisson's steady-state equation -- each contributing distinctive modeling properties: heat diffusion enforces local smoothness, wave propagation facilitates long-range interactions, and Poisson's equation captures global equilibrium. To combine these priors effectively, we introduce the Mixture of Physical Priors Adapter (MoPPA), using an efficient Discrete Cosine Transform (DCT) implementation. To dynamically balance these priors, a route regularization mechanism is designed to adaptively tune their contributions. MoPPA serves as a lightweight, plug-and-play module that seamlessly integrates into transformer architectures, with adaptable complexity depending on the local context. Specifically, using MAE pre-trained ViT-B, MoPPA improves PEFT accuracy by up to 2.1% on VTAB-1K image classification with a comparable number of trainable parameters, and advantages are further validated through experiments across various vision backbones, showcasing MoPPA's effectiveness and adaptability. The code will be made public available.
RS-vHeat: Heat Conduction Guided Efficient Remote Sensing Foundation Model
Nov 27, 2024Remote sensing foundation models largely break away from the traditional paradigm of designing task-specific models, offering greater scalability across multiple tasks. However, they face challenges such as low computational efficiency and limited interpretability, especially when dealing with high-resolution remote sensing images. To overcome these, we draw inspiration from heat conduction, a physical process modeling local heat diffusion. Building on this idea, we are the first to explore the potential of using the parallel computing model of heat conduction to simulate the local region correlations in high-resolution remote sensing images, and introduce RS-vHeat, an efficient multi-modal remote sensing foundation model. Specifically, RS-vHeat 1) applies the Heat Conduction Operator (HCO) with a complexity of $O(N^{1.5})$ and a global receptive field, reducing computational overhead while capturing remote sensing object structure information to guide heat diffusion; 2) learns the frequency distribution representations of various scenes through a self-supervised strategy based on frequency domain hierarchical masking and multi-domain reconstruction; 3) significantly improves efficiency and performance over state-of-the-art techniques across 4 tasks and 10 datasets. Compared to attention-based remote sensing foundation models, we reduces memory consumption by 84%, decreases FLOPs by 24% and improves throughput by 2.7 times.
vHeat: Building Vision Models upon Heat Conduction
May 26, 2024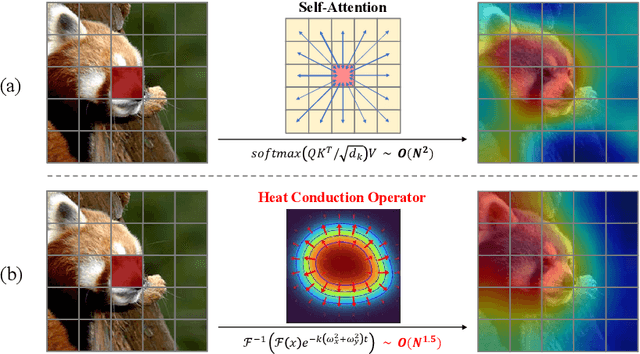

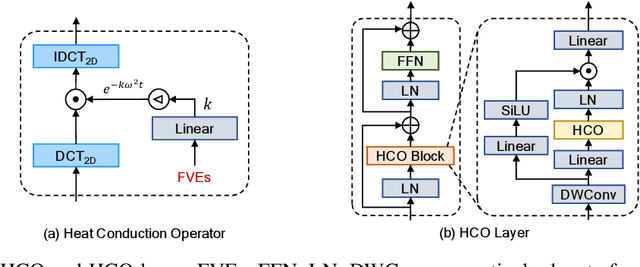

A fundamental problem in learning robust and expressive visual representations lies in efficiently estimating the spatial relationships of visual semantics throughout the entire image. In this study, we propose vHeat, a novel vision backbone model that simultaneously achieves both high computational efficiency and global receptive field. The essential idea, inspired by the physical principle of heat conduction, is to conceptualize image patches as heat sources and model the calculation of their correlations as the diffusion of thermal energy. This mechanism is incorporated into deep models through the newly proposed module, the Heat Conduction Operator (HCO), which is physically plausible and can be efficiently implemented using DCT and IDCT operations with a complexity of $\mathcal{O}(N^{1.5})$. Extensive experiments demonstrate that vHeat surpasses Vision Transformers (ViTs) across various vision tasks, while also providing higher inference speeds, reduced FLOPs, and lower GPU memory usage for high-resolution images. The code will be released at https://github.com/MzeroMiko/vHeat.
Integrally Pre-Trained Transformer Pyramid Networks
Nov 23, 2022



In this paper, we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pre-training stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular, the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1x training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead -- all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
Multi-Agent Automated Machine Learning
Oct 17, 2022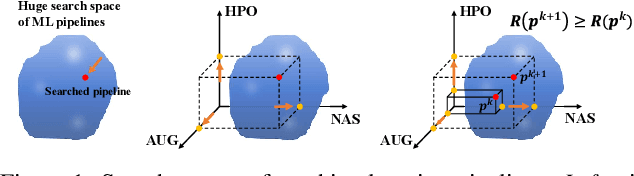
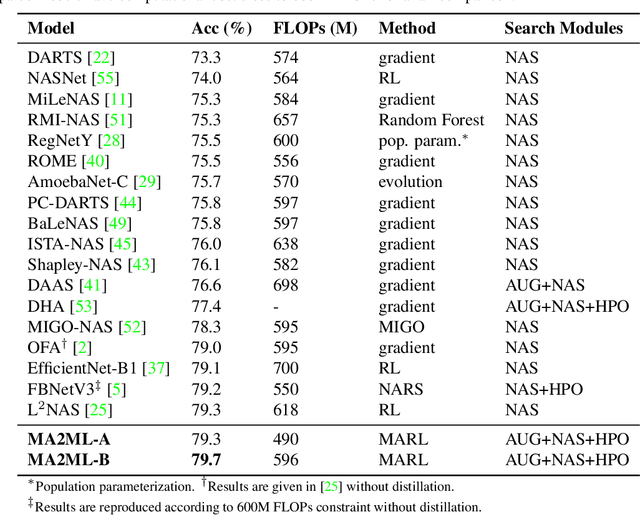
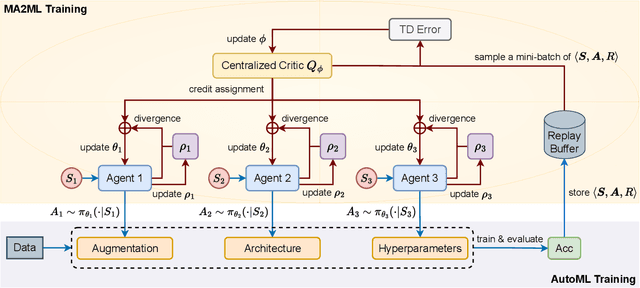
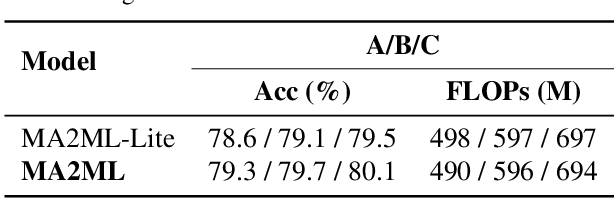
In this paper, we propose multi-agent automated machine learning (MA2ML) with the aim to effectively handle joint optimization of modules in automated machine learning (AutoML). MA2ML takes each machine learning module, such as data augmentation (AUG), neural architecture search (NAS), or hyper-parameters (HPO), as an agent and the final performance as the reward, to formulate a multi-agent reinforcement learning problem. MA2ML explicitly assigns credit to each agent according to its marginal contribution to enhance cooperation among modules, and incorporates off-policy learning to improve search efficiency. Theoretically, MA2ML guarantees monotonic improvement of joint optimization. Extensive experiments show that MA2ML yields the state-of-the-art top-1 accuracy on ImageNet under constraints of computational cost, e.g., $79.7\%/80.5\%$ with FLOPs fewer than 600M/800M. Extensive ablation studies verify the benefits of credit assignment and off-policy learning of MA2ML.