 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Understanding and Generation in Discrete Diffusion Models
Feb 01, 2026In discrete generative modeling, two dominant paradigms demonstrate divergent capabilities: Masked Diffusion Language Models (MDLM) excel at semantic understanding and zero-shot generalization, whereas Uniform-noise Diffusion Language Models (UDLM) achieve strong few-step generation quality, yet neither attains balanced performance across both dimensions. To address this, we propose XDLM, which bridges the two paradigms via a stationary noise kernel. XDLM offers two key contributions: (1) it provides a principled theoretical unification of MDLM and UDLM, recovering each paradigm as a special case; and (2) an alleviated memory bottleneck enabled by an algebraic simplification of the posterior probabilities. Experiments demonstrate that XDLM advances the Pareto frontier between understanding capability and generation quality. Quantitatively, XDLM surpasses UDLM by 5.4 points on zero-shot text benchmarks and outperforms MDLM in few-step image generation (FID 54.1 vs. 80.8). When scaled to tune an 8B-parameter large language model, XDLM achieves 15.0 MBPP in just 32 steps, effectively doubling the baseline performance. Finally, analysis of training dynamics reveals XDLM's superior potential for long-term scaling. Code is available at https://github.com/MzeroMiko/XDLM
Affinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
Departures: Distributional Transport for Single-Cell Perturbation Prediction with Neural Schrödinger Bridges
Nov 17, 2025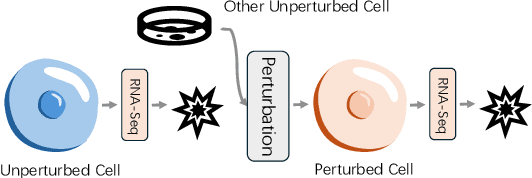
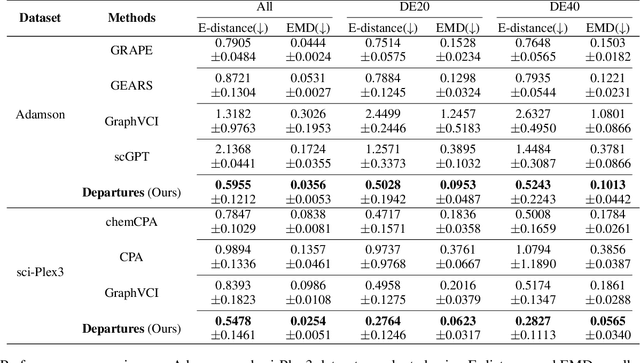
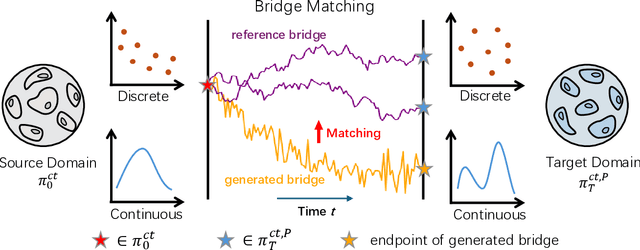

Predicting single-cell perturbation outcomes directly advances gene function analysis and facilitates drug candidate selection, making it a key driver of both basic and translational biomedical research. However, a major bottleneck in this task is the unpaired nature of single-cell data, as the same cell cannot be observed both before and after perturbation due to the destructive nature of sequencing. Although some neural generative transport models attempt to tackle unpaired single-cell perturbation data, they either lack explicit conditioning or depend on prior spaces for indirect distribution alignment, limiting precise perturbation modeling. In this work, we approximate Schrödinger Bridge (SB), which defines stochastic dynamic mappings recovering the entropy-regularized optimal transport (OT), to directly align the distributions of control and perturbed single-cell populations across different perturbation conditions. Unlike prior SB approximations that rely on bidirectional modeling to infer optimal source-target sample coupling, we leverage Minibatch-OT based pairing to avoid such bidirectional inference and the associated ill-posedness of defining the reverse process. This pairing directly guides bridge learning, yielding a scalable approximation to the SB. We approximate two SB models, one modeling discrete gene activation states and the other continuous expression distributions. Joint training enables accurate perturbation modeling and captures single-cell heterogeneity. Experiments on public genetic and drug perturbation datasets show that our model effectively captures heterogeneous single-cell responses and achieves state-of-the-art performance.
Tokenizing Electron Cloud in Protein-Ligand Interaction Learning
May 25, 2025



The affinity and specificity of protein-molecule binding directly impact functional outcomes, uncovering the mechanisms underlying biological regulation and signal transduction. Most deep-learning-based prediction approaches focus on structures of atoms or fragments. However, quantum chemical properties, such as electronic structures, are the key to unveiling interaction patterns but remain largely underexplored. To bridge this gap, we propose ECBind, a method for tokenizing electron cloud signals into quantized embeddings, enabling their integration into downstream tasks such as binding affinity prediction. By incorporating electron densities, ECBind helps uncover binding modes that cannot be fully represented by atom-level models. Specifically, to remove the redundancy inherent in electron cloud signals, a structure-aware transformer and hierarchical codebooks encode 3D binding sites enriched with electron structures into tokens. These tokenized codes are then used for specific tasks with labels. To extend its applicability to a wider range of scenarios, we utilize knowledge distillation to develop an electron-cloud-agnostic prediction model. Experimentally, ECBind demonstrates state-of-the-art performance across multiple tasks, achieving improvements of 6.42\% and 15.58\% in per-structure Pearson and Spearman correlation coefficients, respectively.
A Simple yet Effective DDG Predictor is An Unsupervised Antibody Optimizer and Explainer
Feb 10, 2025The proteins that exist today have been optimized over billions of years of natural evolution, during which nature creates random mutations and selects them. The discovery of functionally promising mutations is challenged by the limited evolutionary accessible regions, i.e., only a small region on the fitness landscape is beneficial. There have been numerous priors used to constrain protein evolution to regions of landscapes with high-fitness variants, among which the change in binding free energy (DDG) of protein complexes upon mutations is one of the most commonly used priors. However, the huge mutation space poses two challenges: (1) how to improve the efficiency of DDG prediction for fast mutation screening; and (2) how to explain mutation preferences and efficiently explore accessible evolutionary regions. To address these challenges, we propose a lightweight DDG predictor (Light-DDG), which adopts a structure-aware Transformer as the backbone and enhances it by knowledge distilled from existing powerful but computationally heavy DDG predictors. Additionally, we augmented, annotated, and released a large-scale dataset containing millions of mutation data for pre-training Light-DDG. We find that such a simple yet effective Light-DDG can serve as a good unsupervised antibody optimizer and explainer. For the target antibody, we propose a novel Mutation Explainer to learn mutation preferences, which accounts for the marginal benefit of each mutation per residue. To further explore accessible evolutionary regions, we conduct preference-guided antibody optimization and evaluate antibody candidates quickly using Light-DDG to identify desirable mutations.
CC-Diff: Enhancing Contextual Coherence in Remote Sensing Image Synthesis
Dec 11, 2024Accurately depicting real-world landscapes in remote sensing (RS) images requires precise alignment between objects and their environment. However, most existing synthesis methods for natural images prioritize foreground control, often reducing the background to plain textures. This neglects the interaction between foreground and background, which can lead to incoherence in RS scenarios. In this paper, we introduce CC-Diff, a Diffusion Model-based approach for RS image generation with enhanced Context Coherence. To capture spatial interdependence, we propose a sequential pipeline where background generation is conditioned on synthesized foreground instances. Distinct learnable queries are also employed to model both the complex background texture and its semantic relation to the foreground. Extensive experiments demonstrate that CC-Diff outperforms state-of-the-art methods in visual fidelity, semantic accuracy, and positional precision, excelling in both RS and natural image domains. CC-Diff also shows strong trainability, improving detection accuracy by 2.04 mAP on DOTA and 2.25 mAP on the COCO benchmark.
Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
Nov 28, 2024In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
Vision Calorimeter for Anti-neutron Reconstruction: A Baseline
Aug 20, 2024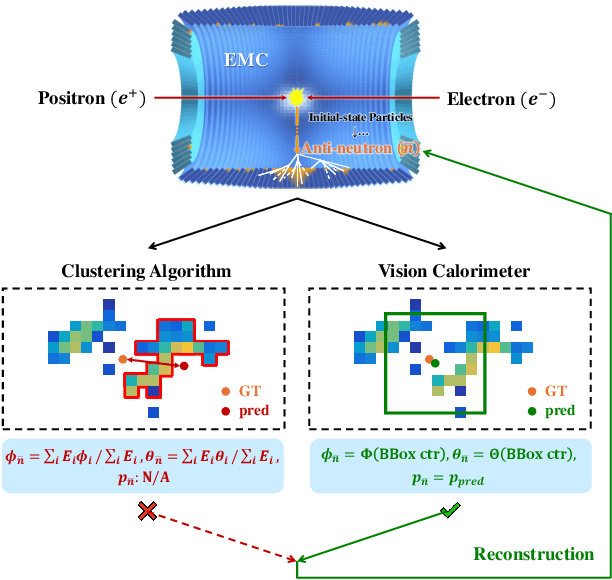



In high-energy physics, anti-neutrons ($\bar{n}$) are fundamental particles that frequently appear as final-state particles, and the reconstruction of their kinematic properties provides an important probe for understanding the governing principles. However, this confronts significant challenges instrumentally with the electromagnetic calorimeter (EMC), a typical experimental sensor but recovering the information of incident $\bar{n}$ insufficiently. In this study, we introduce Vision Calorimeter (ViC), a baseline method for anti-neutron reconstruction that leverages deep learning detectors to analyze the implicit relationships between EMC responses and incident $\bar{n}$ characteristics. Our motivation lies in that energy distributions of $\bar{n}$ samples deposited in the EMC cell arrays embody rich contextual information. Converted to 2-D images, such contextual energy distributions can be used to predict the status of $\bar{n}$ ($i.e.$, incident position and momentum) through a deep learning detector along with pseudo bounding boxes and a specified training objective. Experimental results demonstrate that ViC substantially outperforms the conventional reconstruction approach, reducing the prediction error of incident position by 42.81% (from 17.31$^{\circ}$ to 9.90$^{\circ}$). More importantly, this study for the first time realizes the measurement of incident $\bar{n}$ momentum, underscoring the potential of deep learning detectors for particle reconstruction. Code is available at https://github.com/yuhongtian17/ViC.
Teach Harder, Learn Poorer: Rethinking Hard Sample Distillation for GNN-to-MLP Knowledge Distillation
Jul 20, 2024


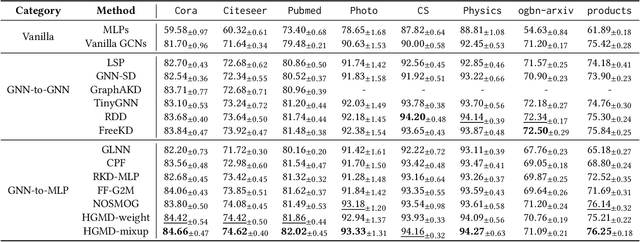
To bridge the gaps between powerful Graph Neural Networks (GNNs) and lightweight Multi-Layer Perceptron (MLPs), GNN-to-MLP Knowledge Distillation (KD) proposes to distill knowledge from a well-trained teacher GNN into a student MLP. In this paper, we revisit the knowledge samples (nodes) in teacher GNNs from the perspective of hardness, and identify that hard sample distillation may be a major performance bottleneck of existing graph KD algorithms. The GNN-to-MLP KD involves two different types of hardness, one student-free knowledge hardness describing the inherent complexity of GNN knowledge, and the other student-dependent distillation hardness describing the difficulty of teacher-to-student distillation. However, most of the existing work focuses on only one of these aspects or regards them as one thing. This paper proposes a simple yet effective Hardness-aware GNN-to-MLP Distillation (HGMD) framework, which decouples the two hardnesses and estimates them using a non-parametric approach. Finally, two hardness-aware distillation schemes (i.e., HGMD-weight and HGMD-mixup) are further proposed to distill hardness-aware knowledge from teacher GNNs into the corresponding nodes of student MLPs. As non-parametric distillation, HGMD does not involve any additional learnable parameters beyond the student MLPs, but it still outperforms most of the state-of-the-art competitors. HGMD-mixup improves over the vanilla MLPs by 12.95% and outperforms its teacher GNNs by 2.48% averaged over seven real-world datasets.
Short-Long Convolutions Help Hardware-Efficient Linear Attention to Focus on Long Sequences
Jun 12, 2024



To mitigate the computational complexity in the self-attention mechanism on long sequences, linear attention utilizes computation tricks to achieve linear complexity, while state space models (SSMs) popularize a favorable practice of using non-data-dependent memory pattern, i.e., emphasize the near and neglect the distant, to processing sequences. Recent studies have shown the priorities by combining them as one. However, the efficiency of linear attention remains only at the theoretical level in a causal setting, and SSMs require various designed constraints to operate effectively on specific data. Therefore, in order to unveil the true power of the hybrid design, the following two issues need to be addressed: (1) hardware-efficient implementation for linear attention and (2) stabilization of SSMs. To achieve this, we leverage the thought of tiling and hierarchy to propose CHELA (short-long Convolutions with Hardware-Efficient Linear Attention), which replaces SSMs with short-long convolutions and implements linear attention in a divide-and-conquer manner. This approach enjoys global abstraction and data-dependent selection from stable SSM and linear attention while maintaining real linear complexity. Our comprehensive experiments on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method.