 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Designated Detector Watermarking for Language Models
Sep 26, 2024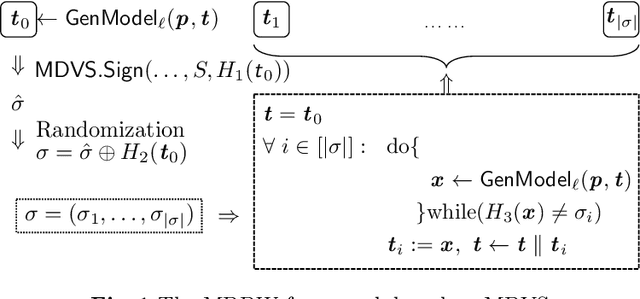



In this paper, we initiate the study of \emph{multi-designated detector watermarking (MDDW)} for large language models (LLMs). This technique allows model providers to generate watermarked outputs from LLMs with two key properties: (i) only specific, possibly multiple, designated detectors can identify the watermarks, and (ii) there is no perceptible degradation in the output quality for ordinary users. We formalize the security definitions for MDDW and present a framework for constructing MDDW for any LLM using multi-designated verifier signatures (MDVS). Recognizing the significant economic value of LLM outputs, we introduce claimability as an optional security feature for MDDW, enabling model providers to assert ownership of LLM outputs within designated-detector settings. To support claimable MDDW, we propose a generic transformation converting any MDVS to a claimable MDVS. Our implementation of the MDDW scheme highlights its advanced functionalities and flexibility over existing methods, with satisfactory performance metrics.
EncryIP: A Practical Encryption-Based Framework for Model Intellectual Property Protection
Dec 19, 2023

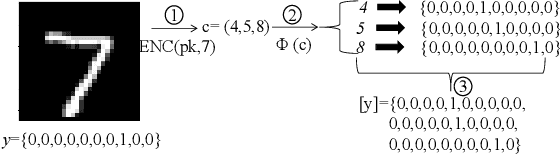

In the rapidly growing digital economy, protecting intellectual property (IP) associated with digital products has become increasingly important. Within this context, machine learning (ML) models, being highly valuable digital assets, have gained significant attention for IP protection. This paper introduces a practical encryption-based framework called \textit{EncryIP}, which seamlessly integrates a public-key encryption scheme into the model learning process. This approach enables the protected model to generate randomized and confused labels, ensuring that only individuals with accurate secret keys, signifying authorized users, can decrypt and reveal authentic labels. Importantly, the proposed framework not only facilitates the protected model to multiple authorized users without requiring repetitive training of the original ML model with IP protection methods but also maintains the model's performance without compromising its accuracy. Compared to existing methods like watermark-based, trigger-based, and passport-based approaches, \textit{EncryIP} demonstrates superior effectiveness in both training protected models and efficiently detecting the unauthorized spread of ML models.