 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Mathematical Equations with Diffusion Language Model
Sep 16, 2025Discovering valid and meaningful mathematical equations from observed data plays a crucial role in scientific discovery. While this task, symbolic regression, remains challenging due to the vast search space and the trade-off between accuracy and complexity. In this paper, we introduce DiffuSR, a pre-training framework for symbolic regression built upon a continuous-state diffusion language model. DiffuSR employs a trainable embedding layer within the diffusion process to map discrete mathematical symbols into a continuous latent space, modeling equation distributions effectively. Through iterative denoising, DiffuSR converts an initial noisy sequence into a symbolic equation, guided by numerical data injected via a cross-attention mechanism. We also design an effective inference strategy to enhance the accuracy of the diffusion-based equation generator, which injects logit priors into genetic programming. Experimental results on standard symbolic regression benchmarks demonstrate that DiffuSR achieves competitive performance with state-of-the-art autoregressive methods and generates more interpretable and diverse mathematical expressions.
Multi-Designated Detector Watermarking for Language Models
Sep 26, 2024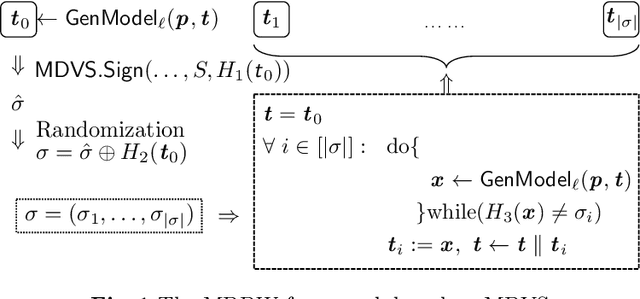



In this paper, we initiate the study of \emph{multi-designated detector watermarking (MDDW)} for large language models (LLMs). This technique allows model providers to generate watermarked outputs from LLMs with two key properties: (i) only specific, possibly multiple, designated detectors can identify the watermarks, and (ii) there is no perceptible degradation in the output quality for ordinary users. We formalize the security definitions for MDDW and present a framework for constructing MDDW for any LLM using multi-designated verifier signatures (MDVS). Recognizing the significant economic value of LLM outputs, we introduce claimability as an optional security feature for MDDW, enabling model providers to assert ownership of LLM outputs within designated-detector settings. To support claimable MDDW, we propose a generic transformation converting any MDVS to a claimable MDVS. Our implementation of the MDDW scheme highlights its advanced functionalities and flexibility over existing methods, with satisfactory performance metrics.
SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models
Jan 06, 2024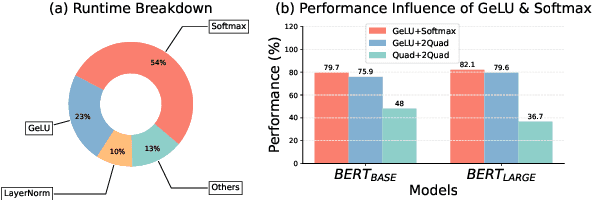
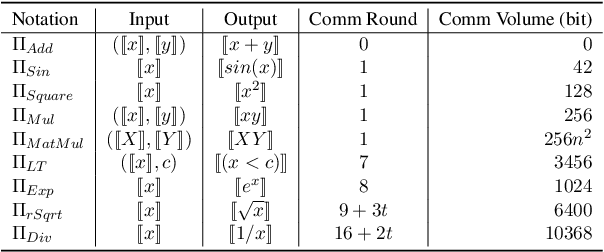
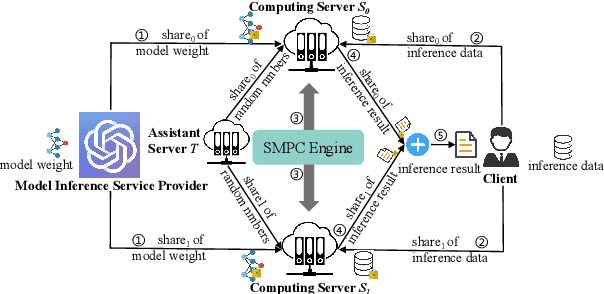
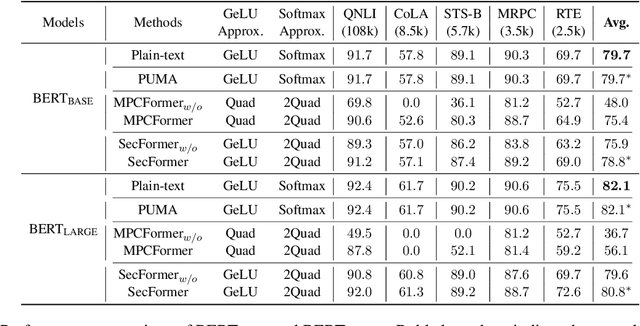
With the growing use of large language models hosted on cloud platforms to offer inference services, privacy concerns are escalating, especially concerning sensitive data like investment plans and bank account details. Secure Multi-Party Computing (SMPC) emerges as a promising solution to protect the privacy of inference data and model parameters. However, the application of SMPC in Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often leads to considerable slowdowns or declines in performance. This is largely due to the multitude of nonlinear operations in the Transformer architecture, which are not well-suited to SMPC and difficult to circumvent or optimize effectively. To address this concern, we introduce an advanced optimization framework called SecFormer, to achieve fast and accurate PPI for Transformer models. By implementing model design optimization, we successfully eliminate the high-cost exponential and maximum operations in PPI without sacrificing model performance. Additionally, we have developed a suite of efficient SMPC protocols that utilize segmented polynomials, Fourier series and Goldschmidt's method to handle other complex nonlinear functions within PPI, such as GeLU, LayerNorm, and Softmax. Our extensive experiments reveal that SecFormer outperforms MPCFormer in performance, showing improvements of $5.6\%$ and $24.2\%$ for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, respectively. In terms of efficiency, SecFormer is 3.56 and 3.58 times faster than Puma for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, demonstrating its effectiveness and speed.
EncryIP: A Practical Encryption-Based Framework for Model Intellectual Property Protection
Dec 19, 2023

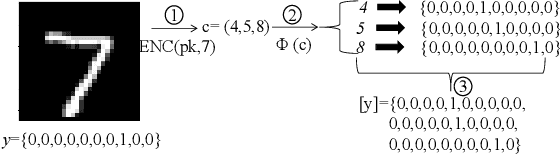

In the rapidly growing digital economy, protecting intellectual property (IP) associated with digital products has become increasingly important. Within this context, machine learning (ML) models, being highly valuable digital assets, have gained significant attention for IP protection. This paper introduces a practical encryption-based framework called \textit{EncryIP}, which seamlessly integrates a public-key encryption scheme into the model learning process. This approach enables the protected model to generate randomized and confused labels, ensuring that only individuals with accurate secret keys, signifying authorized users, can decrypt and reveal authentic labels. Importantly, the proposed framework not only facilitates the protected model to multiple authorized users without requiring repetitive training of the original ML model with IP protection methods but also maintains the model's performance without compromising its accuracy. Compared to existing methods like watermark-based, trigger-based, and passport-based approaches, \textit{EncryIP} demonstrates superior effectiveness in both training protected models and efficiently detecting the unauthorized spread of ML models.
Migrant Resettlement by Evolutionary Multi-objective Optimization
Oct 26, 2023Migration has been a universal phenomenon, which brings opportunities as well as challenges for global development. As the number of migrants (e.g., refugees) increases rapidly in recent years, a key challenge faced by each country is the problem of migrant resettlement. This problem has attracted scientific research attention, from the perspective of maximizing the employment rate. Previous works mainly formulated migrant resettlement as an approximately submodular optimization problem subject to multiple matroid constraints and employed the greedy algorithm, whose performance, however, may be limited due to its greedy nature. In this paper, we propose a new framework MR-EMO based on Evolutionary Multi-objective Optimization, which reformulates Migrant Resettlement as a bi-objective optimization problem that maximizes the expected number of employed migrants and minimizes the number of dispatched migrants simultaneously, and employs a Multi-Objective Evolutionary Algorithm (MOEA) to solve the bi-objective problem. We implement MR-EMO using three MOEAs, the popular NSGA-II, MOEA/D as well as the theoretically grounded GSEMO. To further improve the performance of MR-EMO, we propose a specific MOEA, called GSEMO-SR, using matrix-swap mutation and repair mechanism, which has a better ability to search for feasible solutions. We prove that MR-EMO using either GSEMO or GSEMO-SR can achieve better theoretical guarantees than the previous greedy algorithm. Experimental results under the interview and coordination migration models clearly show the superiority of MR-EMO (with either NSGA-II, MOEA/D, GSEMO or GSEMO-SR) over previous algorithms, and that using GSEMO-SR leads to the best performance of MR-EMO.
Model Provenance via Model DNA
Aug 04, 2023Understanding the life cycle of the machine learning (ML) model is an intriguing area of research (e.g., understanding where the model comes from, how it is trained, and how it is used). This paper focuses on a novel problem within this field, namely Model Provenance (MP), which concerns the relationship between a target model and its pre-training model and aims to determine whether a source model serves as the provenance for a target model. This is an important problem that has significant implications for ensuring the security and intellectual property of machine learning models but has not received much attention in the literature. To fill in this gap, we introduce a novel concept of Model DNA which represents the unique characteristics of a machine learning model. We utilize a data-driven and model-driven representation learning method to encode the model's training data and input-output information as a compact and comprehensive representation (i.e., DNA) of the model. Using this model DNA, we develop an efficient framework for model provenance identification, which enables us to identify whether a source model is a pre-training model of a target model. We conduct evaluations on both computer vision and natural language processing tasks using various models, datasets, and scenarios to demonstrate the effectiveness of our approach in accurately identifying model provenance.
A Generative Approach for Script Event Prediction via Contrastive Fine-tuning
Dec 09, 2022



Script event prediction aims to predict the subsequent event given the context. This requires the capability to infer the correlations between events. Recent works have attempted to improve event correlation reasoning by using pretrained language models and incorporating external knowledge~(e.g., discourse relations). Though promising results have been achieved, some challenges still remain. First, the pretrained language models adopted by current works ignore event-level knowledge, resulting in an inability to capture the correlations between events well. Second, modeling correlations between events with discourse relations is limited because it can only capture explicit correlations between events with discourse markers, and cannot capture many implicit correlations. To this end, we propose a novel generative approach for this task, in which a pretrained language model is fine-tuned with an event-centric pretraining objective and predicts the next event within a generative paradigm. Specifically, we first introduce a novel event-level blank infilling strategy as the learning objective to inject event-level knowledge into the pretrained language model, and then design a likelihood-based contrastive loss for fine-tuning the generative model. Instead of using an additional prediction layer, we perform prediction by using sequence likelihoods generated by the generative model. Our approach models correlations between events in a soft way without any external knowledge. The likelihood-based prediction eliminates the need to use additional networks to make predictions and is somewhat interpretable since it scores each word in the event. Experimental results on the multi-choice narrative cloze~(MCNC) task demonstrate that our approach achieves better results than other state-of-the-art baselines. Our code will be available at https://github.com/zhufq00/mcnc.
Data Provenance via Differential Auditing
Sep 04, 2022



Auditing Data Provenance (ADP), i.e., auditing if a certain piece of data has been used to train a machine learning model, is an important problem in data provenance. The feasibility of the task has been demonstrated by existing auditing techniques, e.g., shadow auditing methods, under certain conditions such as the availability of label information and the knowledge of training protocols for the target model. Unfortunately, both of these conditions are often unavailable in real applications. In this paper, we introduce Data Provenance via Differential Auditing (DPDA), a practical framework for auditing data provenance with a different approach based on statistically significant differentials, i.e., after carefully designed transformation, perturbed input data from the target model's training set would result in much more drastic changes in the output than those from the model's non-training set. This framework allows auditors to distinguish training data from non-training ones without the need of training any shadow models with the help of labeled output data. Furthermore, we propose two effective auditing function implementations, an additive one and a multiplicative one. We report evaluations on real-world data sets demonstrating the effectiveness of our proposed auditing technique.
Classification under Streaming Emerging New Classes: A Solution using Completely Random Trees
May 30, 2016

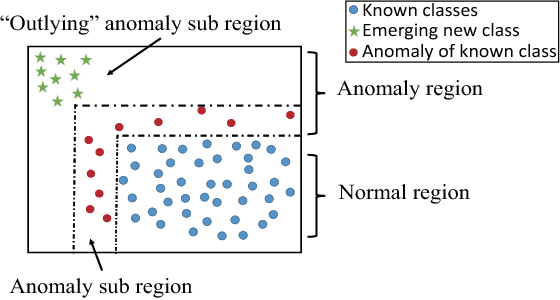

This paper investigates an important problem in stream mining, i.e., classification under streaming emerging new classes or SENC. The common approach is to treat it as a classification problem and solve it using either a supervised learner or a semi-supervised learner. We propose an alternative approach by using unsupervised learning as the basis to solve this problem. The SENC problem can be decomposed into three sub problems: detecting emerging new classes, classifying for known classes, and updating models to enable classification of instances of the new class and detection of more emerging new classes. The proposed method employs completely random trees which have been shown to work well in unsupervised learning and supervised learning independently in the literature. This is the first time, as far as we know, that completely random trees are used as a single common core to solve all three sub problems: unsupervised learning, supervised learning and model update in data streams. We show that the proposed unsupervised-learning-focused method often achieves significantly better outcomes than existing classification-focused methods.