 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Bias Propagation in LLM-Based Tabular Data Generation
Jun 11, 2025Large Language Models (LLMs) are increasingly used for synthetic tabular data generation through in-context learning (ICL), offering a practical solution for data augmentation in data scarce scenarios. While prior work has shown the potential of LLMs to improve downstream task performance through augmenting underrepresented groups, these benefits often assume access to a subset of unbiased in-context examples, representative of the real dataset. In real-world settings, however, data is frequently noisy and demographically skewed. In this paper, we systematically study how statistical biases within in-context examples propagate to the distribution of synthetic tabular data, showing that even mild in-context biases lead to global statistical distortions. We further introduce an adversarial scenario where a malicious contributor can inject bias into the synthetic dataset via a subset of in-context examples, ultimately compromising the fairness of downstream classifiers for a targeted and protected subgroup. Our findings demonstrate a new vulnerability associated with LLM-based data generation pipelines that rely on in-context prompts with in sensitive domains.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025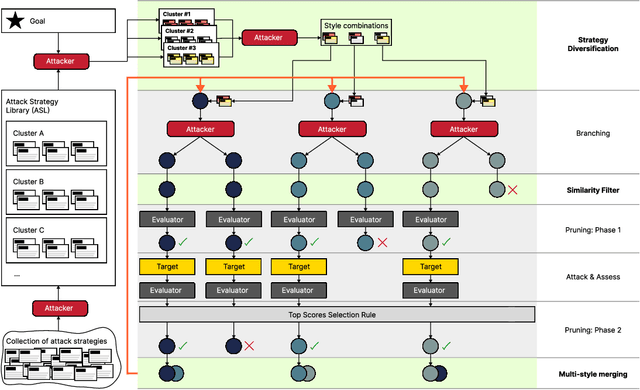
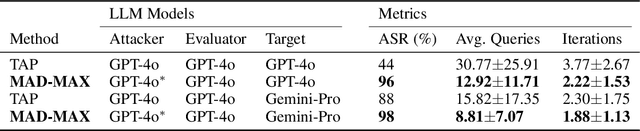
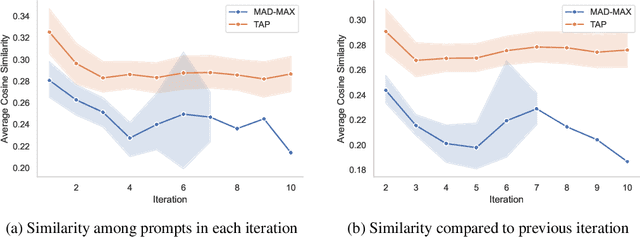
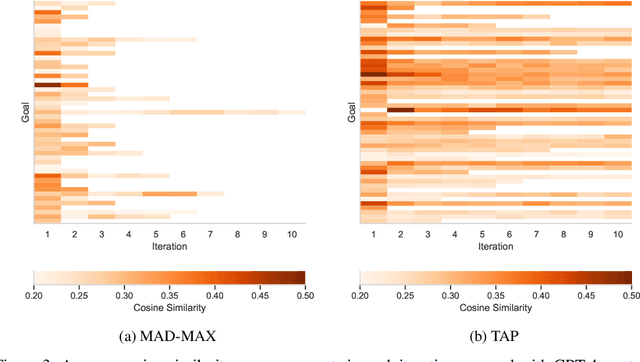
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Adversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025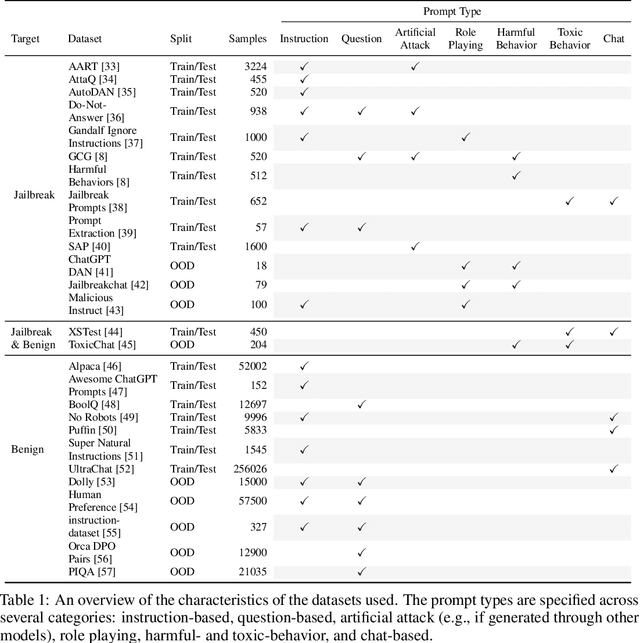
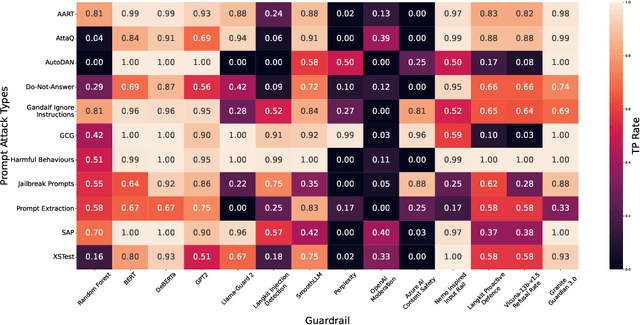
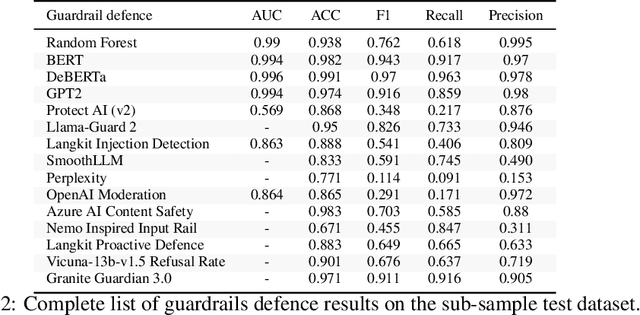
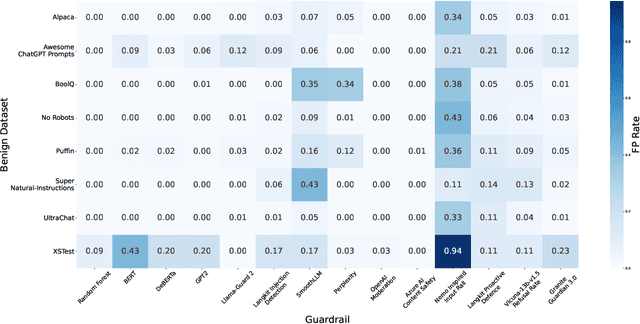
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
MoJE: Mixture of Jailbreak Experts, Naive Tabular Classifiers as Guard for Prompt Attacks
Sep 27, 2024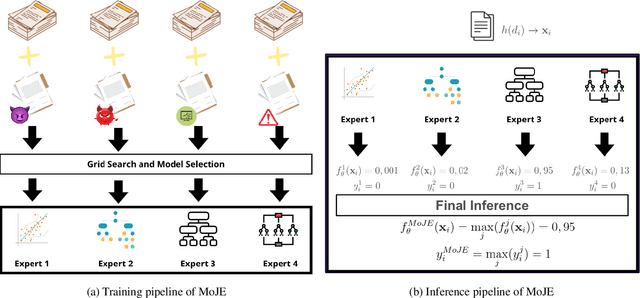
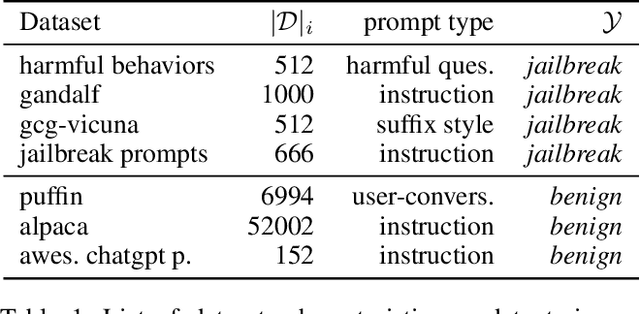
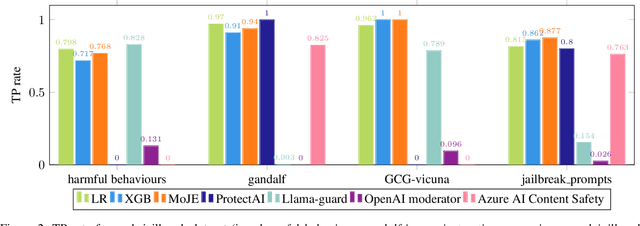
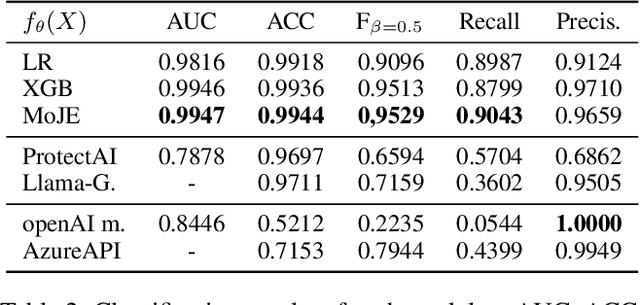
The proliferation of Large Language Models (LLMs) in diverse applications underscores the pressing need for robust security measures to thwart potential jailbreak attacks. These attacks exploit vulnerabilities within LLMs, endanger data integrity and user privacy. Guardrails serve as crucial protective mechanisms against such threats, but existing models often fall short in terms of both detection accuracy, and computational efficiency. This paper advocates for the significance of jailbreak attack prevention on LLMs, and emphasises the role of input guardrails in safeguarding these models. We introduce MoJE (Mixture of Jailbreak Expert), a novel guardrail architecture designed to surpass current limitations in existing state-of-the-art guardrails. By employing simple linguistic statistical techniques, MoJE excels in detecting jailbreak attacks while maintaining minimal computational overhead during model inference. Through rigorous experimentation, MoJE demonstrates superior performance capable of detecting 90% of the attacks without compromising benign prompts, enhancing LLMs security against jailbreak attacks.