 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoJE: Mixture of Jailbreak Experts, Naive Tabular Classifiers as Guard for Prompt Attacks
Sep 27, 2024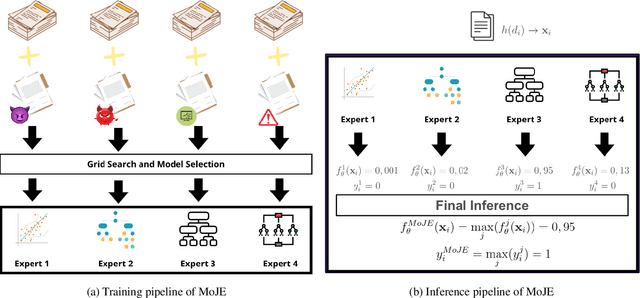
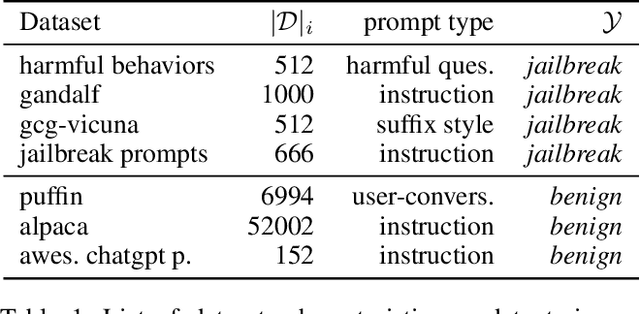
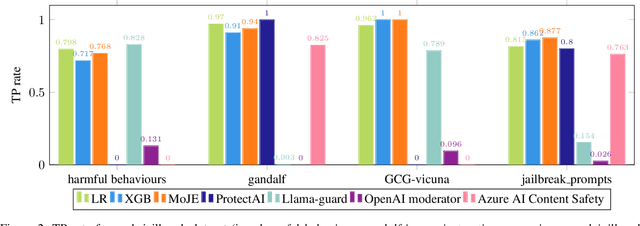
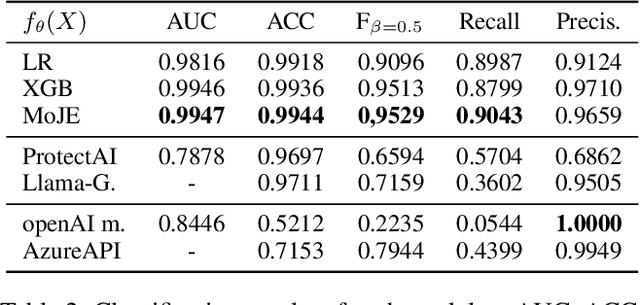
The proliferation of Large Language Models (LLMs) in diverse applications underscores the pressing need for robust security measures to thwart potential jailbreak attacks. These attacks exploit vulnerabilities within LLMs, endanger data integrity and user privacy. Guardrails serve as crucial protective mechanisms against such threats, but existing models often fall short in terms of both detection accuracy, and computational efficiency. This paper advocates for the significance of jailbreak attack prevention on LLMs, and emphasises the role of input guardrails in safeguarding these models. We introduce MoJE (Mixture of Jailbreak Expert), a novel guardrail architecture designed to surpass current limitations in existing state-of-the-art guardrails. By employing simple linguistic statistical techniques, MoJE excels in detecting jailbreak attacks while maintaining minimal computational overhead during model inference. Through rigorous experimentation, MoJE demonstrates superior performance capable of detecting 90% of the attacks without compromising benign prompts, enhancing LLMs security against jailbreak attacks.