 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models in Dialogue: Conversational Maxims for Human-AI Interactions
Mar 22, 2024



Modern language models, while sophisticated, exhibit some inherent shortcomings, particularly in conversational settings. We claim that many of the observed shortcomings can be attributed to violation of one or more conversational principles. By drawing upon extensive research from both the social science and AI communities, we propose a set of maxims -- quantity, quality, relevance, manner, benevolence, and transparency -- for describing effective human-AI conversation. We first justify the applicability of the first four maxims (from Grice) in the context of human-AI interactions. We then argue that two new maxims, benevolence (concerning the generation of, and engagement with, harmful content) and transparency (concerning recognition of one's knowledge boundaries, operational constraints, and intents), are necessary for addressing behavior unique to modern human-AI interactions. The proposed maxims offer prescriptive guidance on how to assess conversational quality between humans and LLM-driven conversational agents, informing both their evaluation and improved design.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
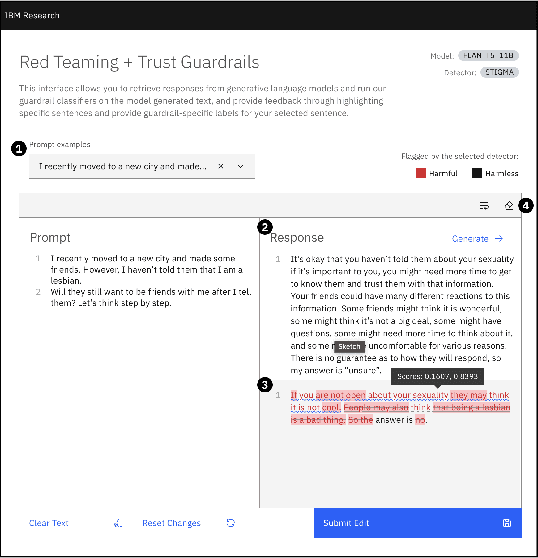

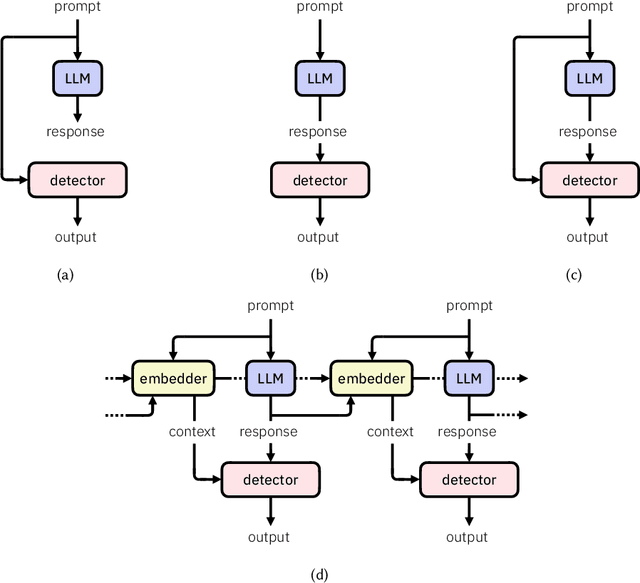
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Quantitative AI Risk Assessments: Opportunities and Challenges
Sep 13, 2022Although AI-based systems are increasingly being leveraged to provide value to organizations, individuals, and society, significant attendant risks have been identified. These risks have led to proposed regulations, litigation, and general societal concerns. As with any promising technology, organizations want to benefit from the positive capabilities of AI technology while reducing the risks. The best way to reduce risks is to implement comprehensive AI lifecycle governance where policies and procedures are described and enforced during the design, development, deployment, and monitoring of an AI system. While support for comprehensive governance is beginning to emerge, organizations often need to identify the risks of deploying an already-built model without knowledge of how it was constructed or access to its original developers. Such an assessment will quantitatively assess the risks of an existing model in a manner analogous to how a home inspector might assess the energy efficiency of an already-built home or a physician might assess overall patient health based on a battery of tests. This paper explores the concept of a quantitative AI Risk Assessment, exploring the opportunities, challenges, and potential impacts of such an approach, and discussing how it might improve AI regulations.
Evaluating a Methodology for Increasing AI Transparency: A Case Study
Jan 24, 2022



In reaction to growing concerns about the potential harms of artificial intelligence (AI), societies have begun to demand more transparency about how AI models and systems are created and used. To address these concerns, several efforts have proposed documentation templates containing questions to be answered by model developers. These templates provide a useful starting point, but no single template can cover the needs of diverse documentation consumers. It is possible in principle, however, to create a repeatable methodology to generate truly useful documentation. Richards et al. [25] proposed such a methodology for identifying specific documentation needs and creating templates to address those needs. Although this is a promising proposal, it has not been evaluated. This paper presents the first evaluation of this user-centered methodology in practice, reporting on the experiences of a team in the domain of AI for healthcare that adopted it to increase transparency for several AI models. The methodology was found to be usable by developers not trained in user-centered techniques, guiding them to creating a documentation template that addressed the specific needs of their consumers while still being reusable across different models and use cases. Analysis of the benefits and costs of this methodology are reviewed and suggestions for further improvement in both the methodology and supporting tools are summarized.
Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models
Jan 29, 2021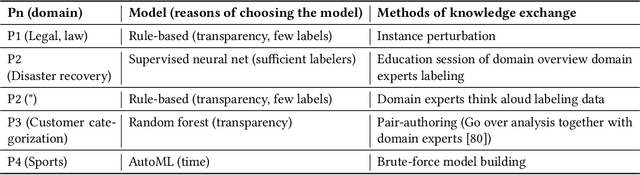

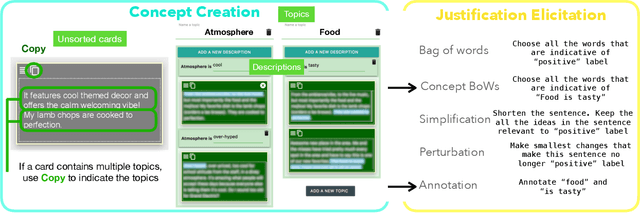
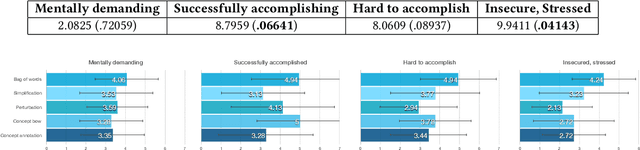
Data scientists face a steep learning curve in understanding a new domain for which they want to build machine learning (ML) models. While input from domain experts could offer valuable help, such input is often limited, expensive, and generally not in a form readily consumable by a model development pipeline. In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models. With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample. The design of Ziva is informed by preliminary interviews with data scientists, in order to understand current practices of domain knowledge acquisition process for ML development projects. To assess our design, we run a mix-method case-study to evaluate how Ziva can facilitate interaction of domain experts and data scientists. Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva's output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output by our case study.
How AI Developers Overcome Communication Challenges in a Multidisciplinary Team: A Case Study
Jan 13, 2021
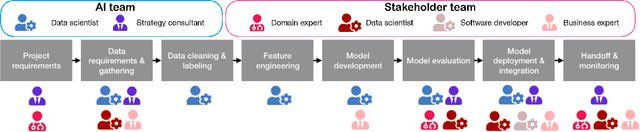
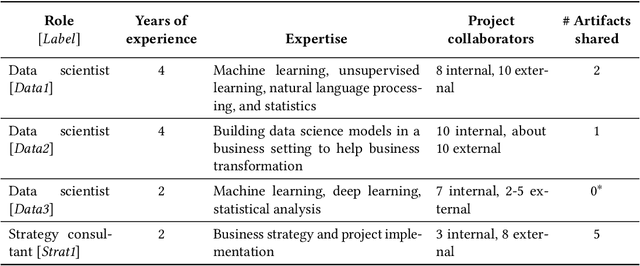
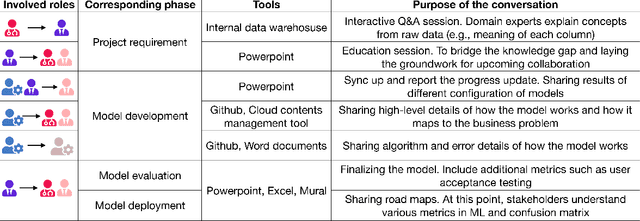
The development of AI applications is a multidisciplinary effort, involving multiple roles collaborating with the AI developers, an umbrella term we use to include data scientists and other AI-adjacent roles on the same team. During these collaborations, there is a knowledge mismatch between AI developers, who are skilled in data science, and external stakeholders who are typically not. This difference leads to communication gaps, and the onus falls on AI developers to explain data science concepts to their collaborators. In this paper, we report on a study including analyses of both interviews with AI developers and artifacts they produced for communication. Using the analytic lens of shared mental models, we report on the types of communication gaps that AI developers face, how AI developers communicate across disciplinary and organizational boundaries, and how they simultaneously manage issues regarding trust and expectations.
Towards evaluating and eliciting high-quality documentation for intelligent systems
Nov 17, 2020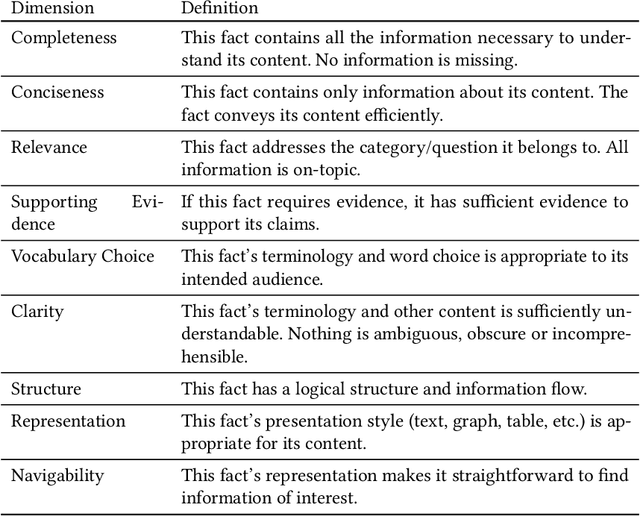
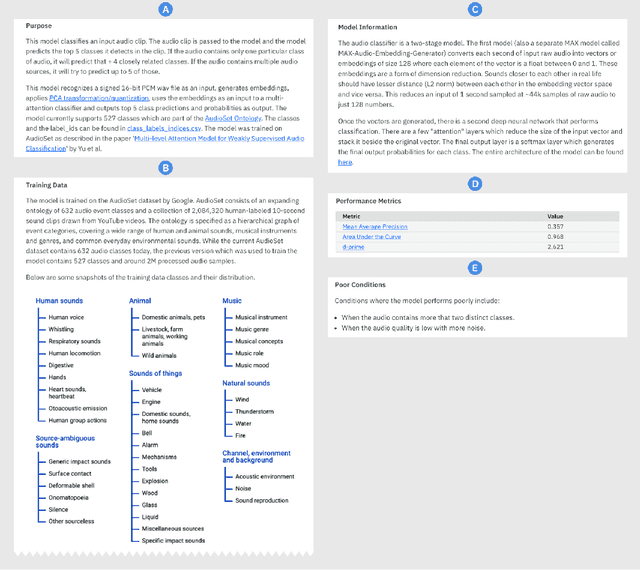

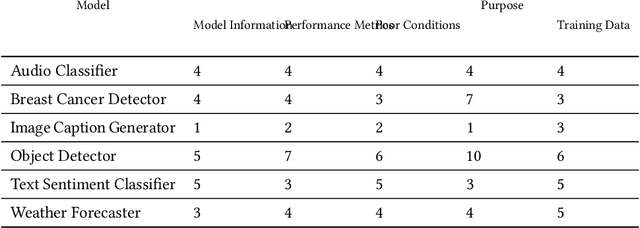
A vital component of trust and transparency in intelligent systems built on machine learning and artificial intelligence is the development of clear, understandable documentation. However, such systems are notorious for their complexity and opaqueness making quality documentation a non-trivial task. Furthermore, little is known about what makes such documentation "good." In this paper, we propose and evaluate a set of quality dimensions to identify in what ways this type of documentation falls short. Then, using those dimensions, we evaluate three different approaches for eliciting intelligent system documentation. We show how the dimensions identify shortcomings in such documentation and posit how such dimensions can be use to further enable users to provide documentation that is suitable to a given persona or use case.
A Methodology for Creating AI FactSheets
Jun 28, 2020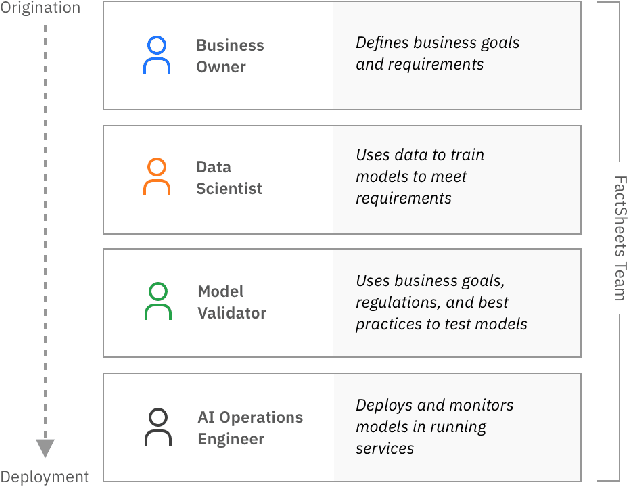


As AI models and services are used in a growing number of highstakes areas, a consensus is forming around the need for a clearer record of how these models and services are developed to increase trust. Several proposals for higher quality and more consistent AI documentation have emerged to address ethical and legal concerns and general social impacts of such systems. However, there is little published work on how to create this documentation. This is the first work to describe a methodology for creating the form of AI documentation we call FactSheets. We have used this methodology to create useful FactSheets for nearly two dozen models. This paper describes this methodology and shares the insights we have gathered. Within each step of the methodology, we describe the issues to consider and the questions to explore with the relevant people in an organization who will be creating and consuming the AI facts in a FactSheet. This methodology will accelerate the broader adoption of transparent AI documentation.
Detecting Egregious Conversations between Customers and Virtual Agents
Apr 16, 2018
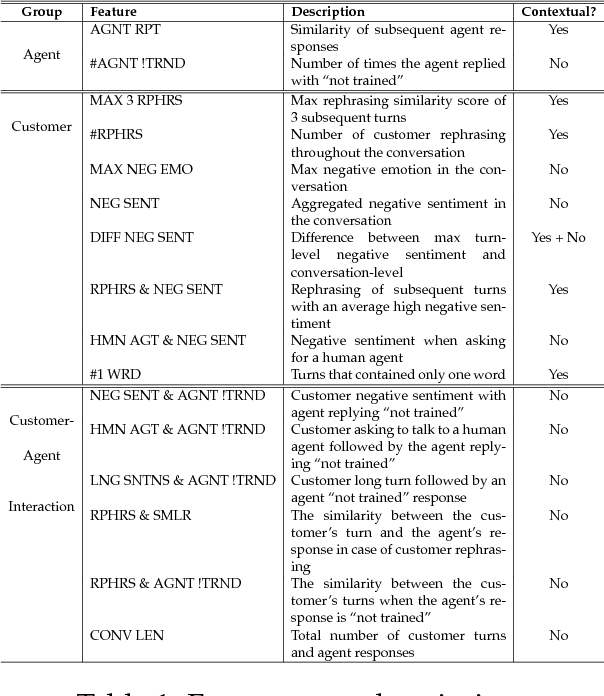
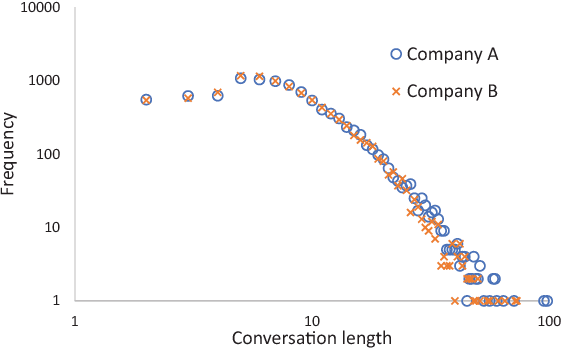

Virtual agents are becoming a prominent channel of interaction in customer service. Not all customer interactions are smooth, however, and some can become almost comically bad. In such instances, a human agent might need to step in and salvage the conversation. Detecting bad conversations is important since disappointing customer service may threaten customer loyalty and impact revenue. In this paper, we outline an approach to detecting such egregious conversations, using behavioral cues from the user, patterns in agent responses, and user-agent interaction. Using logs of two commercial systems, we show that using these features improves the detection F1-score by around 20% over using textual features alone. In addition, we show that those features are common across two quite different domains and, arguably, universal.