 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming Refusal with Conditional Activation Steering
Paper and Code
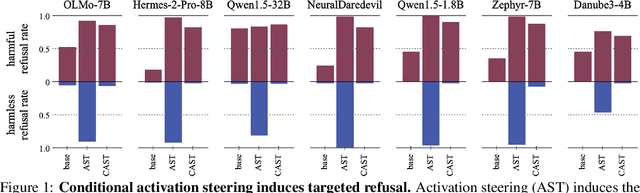



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.