 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interactive Tool for Natural Language Processing on Clinical Text
Jul 07, 2017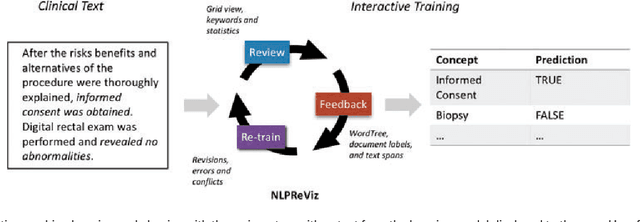
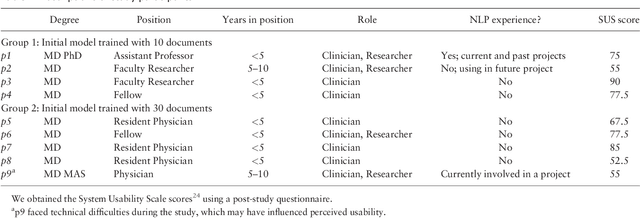
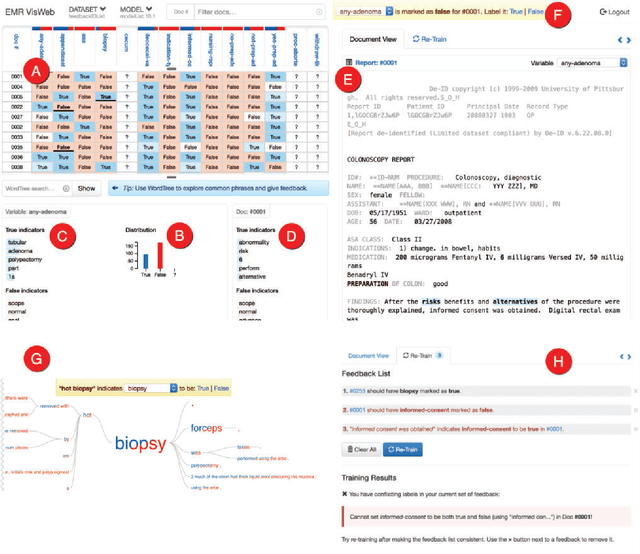
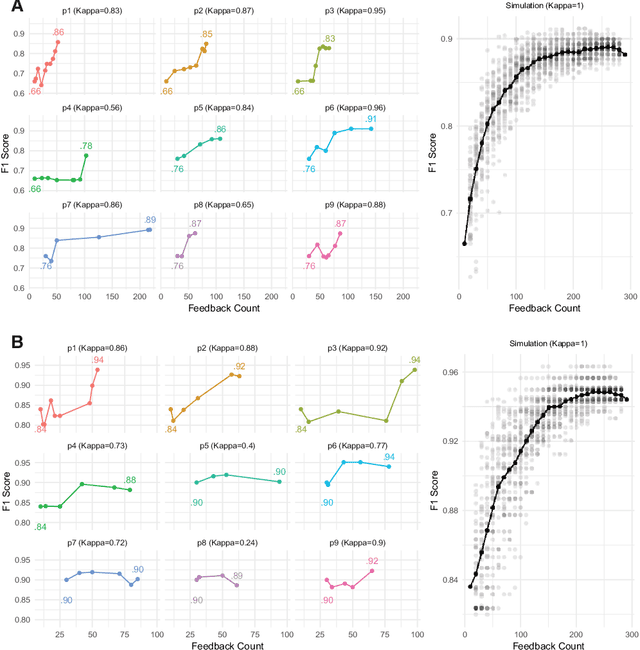
Natural Language Processing (NLP) systems often make use of machine learning techniques that are unfamiliar to end-users who are interested in analyzing clinical records. Although NLP has been widely used in extracting information from clinical text, current systems generally do not support model revision based on feedback from domain experts. We present a prototype tool that allows end users to visualize and review the outputs of an NLP system that extracts binary variables from clinical text. Our tool combines multiple visualizations to help the users understand these results and make any necessary corrections, thus forming a feedback loop and helping improve the accuracy of the NLP models. We have tested our prototype in a formative think-aloud user study with clinicians and researchers involved in colonoscopy research. Results from semi-structured interviews and a System Usability Scale (SUS) analysis show that the users are able to quickly start refining NLP models, despite having very little or no experience with machine learning. Observations from these sessions suggest revisions to the interface to better support review workflow and interpretation of results.
An Account of Opinion Implicatures
Apr 23, 2014While previous sentiment analysis research has concentrated on the interpretation of explicitly stated opinions and attitudes, this work initiates the computational study of a type of opinion implicature (i.e., opinion-oriented inference) in text. This paper described a rule-based framework for representing and analyzing opinion implicatures which we hope will contribute to deeper automatic interpretation of subjective language. In the course of understanding implicatures, the system recognizes implicit sentiments (and beliefs) toward various events and entities in the sentence, often attributed to different sources (holders) and of mixed polarities; thus, it produces a richer interpretation than is typical in opinion analysis.
An Empirical Approach to Temporal Reference Resolution (journal version)
Jan 13, 1999



Scheduling dialogs, during which people negotiate the times of appointments, are common in everyday life. This paper reports the results of an in-depth empirical investigation of resolving explicit temporal references in scheduling dialogs. There are four phases of this work: data annotation and evaluation, model development, system implementation and evaluation, and model evaluation and analysis. The system and model were developed primarily on one set of data, and then applied later to a much more complex data set, to assess the generalizability of the model for the task being performed. Many different types of empirical methods are applied to pinpoint the strengths and weaknesses of the approach. Detailed annotation instructions were developed and an intercoder reliability study was performed, showing that naive annotators can reliably perform the targeted annotations. A fully automatic system has been developed and evaluated on unseen test data, with good results on both data sets. We adopt a pure realization of a recency-based focus model to identify precisely when it is and is not adequate for the task being addressed. In addition to system results, an in-depth evaluation of the model itself is presented, based on detailed manual annotations. The results are that few errors occur specifically due to the model of focus being used, and the set of anaphoric relations defined in the model are low in ambiguity for both data sets.
* Tar archive with LaTeX source, postscript figures, and style files
Probabilistic Event Categorization
Oct 31, 1997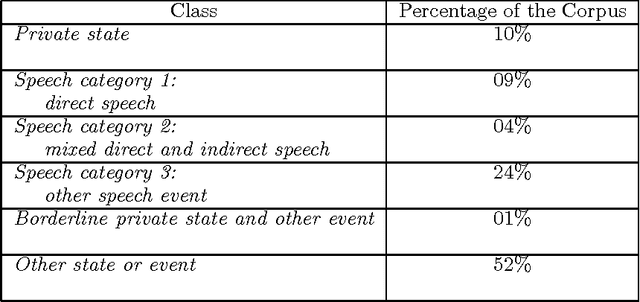
This paper describes the automation of a new text categorization task. The categories assigned in this task are more syntactically, semantically, and contextually complex than those typically assigned by fully automatic systems that process unseen test data. Our system for assigning these categories is a probabilistic classifier, developed with a recent method for formulating a probabilistic model from a predefined set of potential features. This paper focuses on feature selection. It presents a number of fully automatic features. It identifies and evaluates various approaches to organizing collocational properties into features, and presents the results of experiments covarying type of organization and type of property. We find that one organization is not best for all kinds of properties, so this is an experimental parameter worth investigating in NLP systems. In addition, the results suggest a way to take advantage of properties that are low frequency but strongly indicative of a class. The problems of recognizing and organizing the various kinds of contextual information required to perform a linguistically complex categorization task have rarely been systematically investigated in NLP.
An Empirical Approach to Temporal Reference Resolution
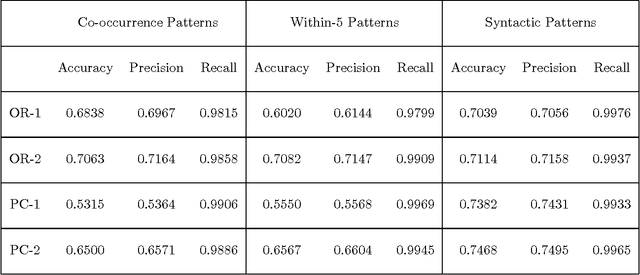
Jun 16, 1997
This paper presents the results of an empirical investigation of temporal reference resolution in scheduling dialogs. The algorithm adopted is primarily a linear-recency based approach that does not include a model of global focus. A fully automatic system has been developed and evaluated on unseen test data with good results. This paper presents the results of an intercoder reliability study, a model of temporal reference resolution that supports linear recency and has very good coverage, the results of the system evaluated on unseen test data, and a detailed analysis of the dialogs assessing the viability of the approach.
* 13 pages, latex using aclap.sty
Instructions for Temporal Annotation of Scheduling Dialogs
Feb 27, 1997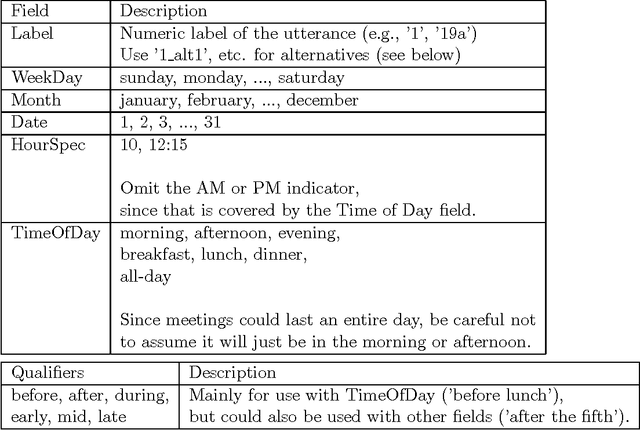
Human annotation of natural language facilitates standardized evaluation of natural language processing systems and supports automated feature extraction. This document consists of instructions for annotating the temporal information in scheduling dialogs, dialogs in which the participants schedule a meeting with one another. Task-oriented dialogs, such as these are, would arise in many useful applications, for instance, automated information providers and automated phone operators. Explicit instructions support good inter-rater reliability and serve as documentation for the classes being annotated.
Sequential Model Selection for Word Sense Disambiguation
Feb 12, 1997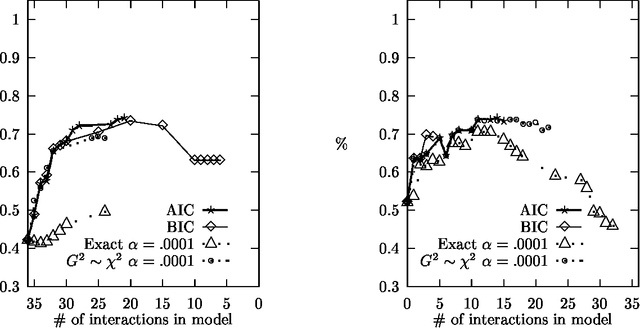

Statistical models of word-sense disambiguation are often based on a small number of contextual features or on a model that is assumed to characterize the interactions among a set of features. Model selection is presented as an alternative to these approaches, where a sequential search of possible models is conducted in order to find the model that best characterizes the interactions among features. This paper expands existing model selection methodology and presents the first comparative study of model selection search strategies and evaluation criteria when applied to the problem of building probabilistic classifiers for word-sense disambiguation.
* 8 pages, Latex, uses aclap.sty
The Measure of a Model
Apr 28, 1996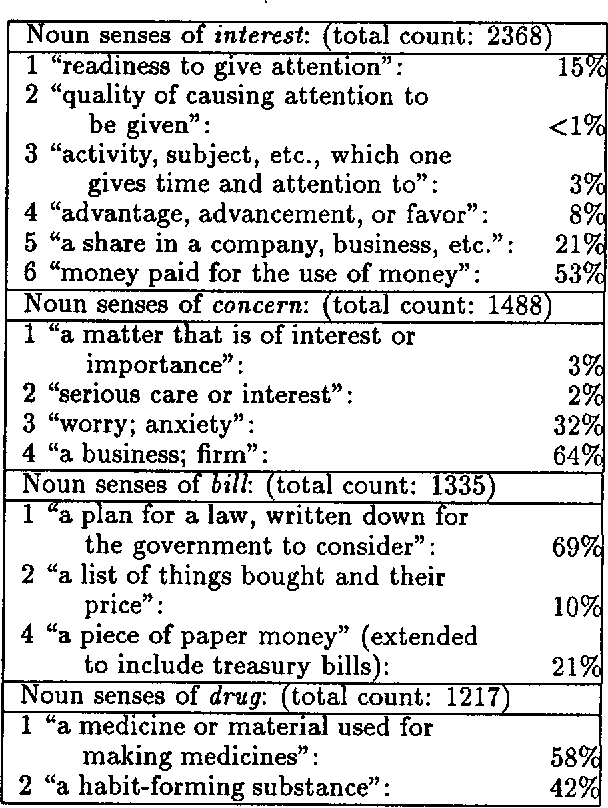
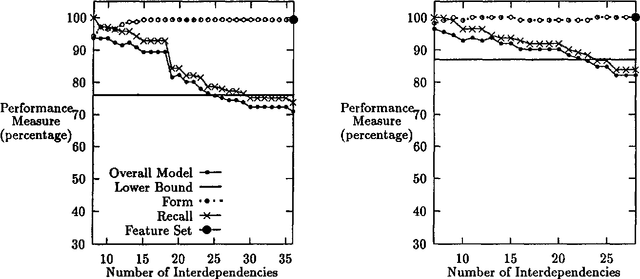

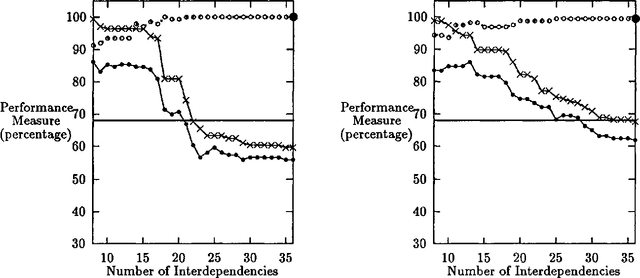
This paper describes measures for evaluating the three determinants of how well a probabilistic classifier performs on a given test set. These determinants are the appropriateness, for the test set, of the results of (1) feature selection, (2) formulation of the parametric form of the model, and (3) parameter estimation. These are part of any model formulation procedure, even if not broken out as separate steps, so the tradeoffs explored in this paper are relevant to a wide variety of methods. The measures are demonstrated in a large experiment, in which they are used to analyze the results of roughly 300 classifiers that perform word-sense disambiguation.
* 12 pages, uuencoded compressed postscript file
Word-Sense Disambiguation Using Decomposable Models
Jun 01, 1994
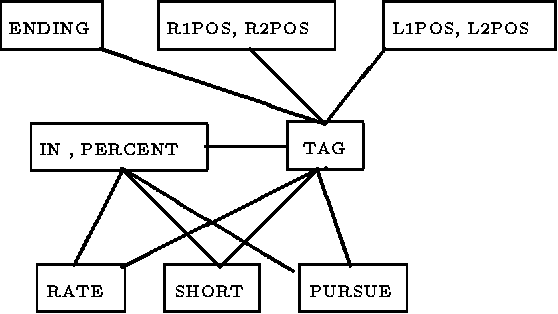

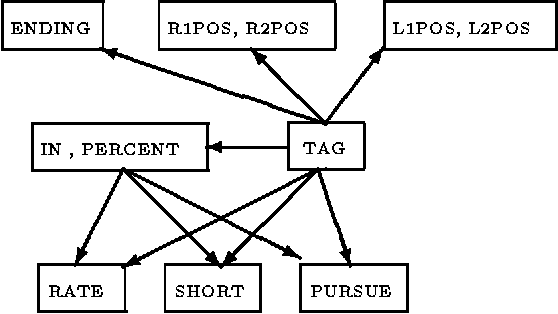
Most probabilistic classifiers used for word-sense disambiguation have either been based on only one contextual feature or have used a model that is simply assumed to characterize the interdependencies among multiple contextual features. In this paper, a different approach to formulating a probabilistic model is presented along with a case study of the performance of models produced in this manner for the disambiguation of the noun "interest". We describe a method for formulating probabilistic models that use multiple contextual features for word-sense disambiguation, without requiring untested assumptions regarding the form of the model. Using this approach, the joint distribution of all variables is described by only the most systematic variable interactions, thereby limiting the number of parameters to be estimated, supporting computational efficiency, and providing an understanding of the data.