 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Learning for Class-Imbalanced Discourse Classification
Jan 02, 2021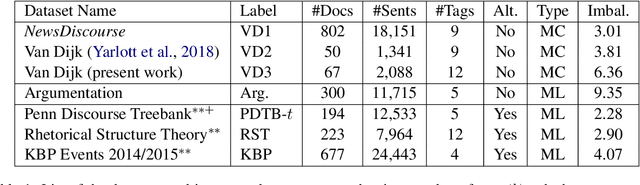

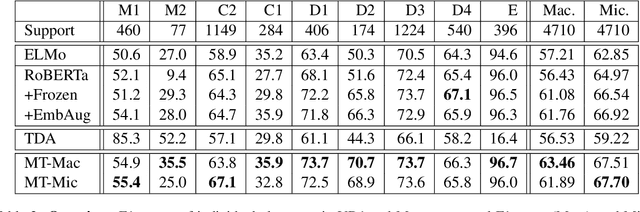
Small class-imbalanced datasets, common in many high-level semantic tasks like discourse analysis, present a particular challenge to current deep-learning architectures. In this work, we perform an extensive analysis on sentence-level classification approaches for the News Discourse dataset, one of the largest high-level semantic discourse datasets recently published. We show that a multitask approach can improve 7% Micro F1-score upon current state-of-the-art benchmarks, due in part to label corrections across tasks, which improve performance for underrepresented classes. We also offer a comparative review of additional techniques proposed to address resource-poor problems in NLP, and show that none of these approaches can improve classification accuracy in such a setting.
An Account of Opinion Implicatures
Apr 23, 2014While previous sentiment analysis research has concentrated on the interpretation of explicitly stated opinions and attitudes, this work initiates the computational study of a type of opinion implicature (i.e., opinion-oriented inference) in text. This paper described a rule-based framework for representing and analyzing opinion implicatures which we hope will contribute to deeper automatic interpretation of subjective language. In the course of understanding implicatures, the system recognizes implicit sentiments (and beliefs) toward various events and entities in the sentence, often attributed to different sources (holders) and of mixed polarities; thus, it produces a richer interpretation than is typical in opinion analysis.