 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Event Categorization
Paper and Code
Oct 31, 1997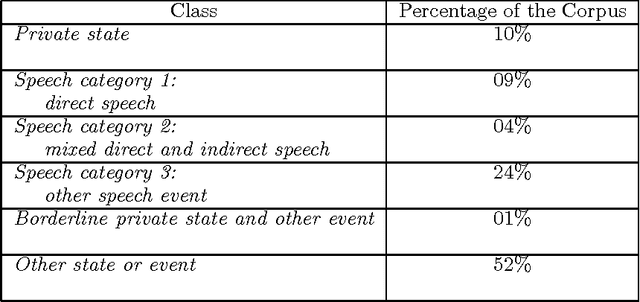
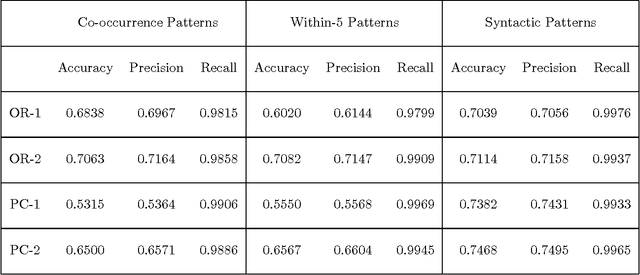
This paper describes the automation of a new text categorization task. The categories assigned in this task are more syntactically, semantically, and contextually complex than those typically assigned by fully automatic systems that process unseen test data. Our system for assigning these categories is a probabilistic classifier, developed with a recent method for formulating a probabilistic model from a predefined set of potential features. This paper focuses on feature selection. It presents a number of fully automatic features. It identifies and evaluates various approaches to organizing collocational properties into features, and presents the results of experiments covarying type of organization and type of property. We find that one organization is not best for all kinds of properties, so this is an experimental parameter worth investigating in NLP systems. In addition, the results suggest a way to take advantage of properties that are low frequency but strongly indicative of a class. The problems of recognizing and organizing the various kinds of contextual information required to perform a linguistically complex categorization task have rarely been systematically investigated in NLP.