 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Event Categorization
Oct 31, 1997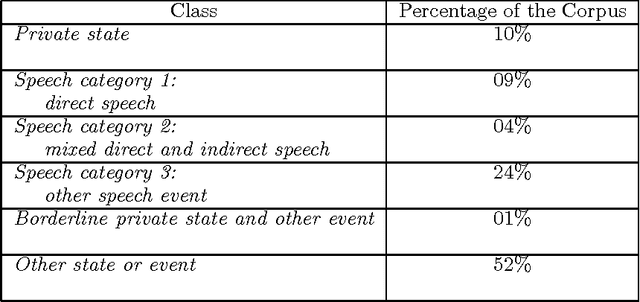
This paper describes the automation of a new text categorization task. The categories assigned in this task are more syntactically, semantically, and contextually complex than those typically assigned by fully automatic systems that process unseen test data. Our system for assigning these categories is a probabilistic classifier, developed with a recent method for formulating a probabilistic model from a predefined set of potential features. This paper focuses on feature selection. It presents a number of fully automatic features. It identifies and evaluates various approaches to organizing collocational properties into features, and presents the results of experiments covarying type of organization and type of property. We find that one organization is not best for all kinds of properties, so this is an experimental parameter worth investigating in NLP systems. In addition, the results suggest a way to take advantage of properties that are low frequency but strongly indicative of a class. The problems of recognizing and organizing the various kinds of contextual information required to perform a linguistically complex categorization task have rarely been systematically investigated in NLP.
Distinguishing Word Senses in Untagged Text
Jun 09, 1997
This paper describes an experimental comparison of three unsupervised learning algorithms that distinguish the sense of an ambiguous word in untagged text. The methods described in this paper, McQuitty's similarity analysis, Ward's minimum-variance method, and the EM algorithm, assign each instance of an ambiguous word to a known sense definition based solely on the values of automatically identifiable features in text. These methods and feature sets are found to be more successful in disambiguating nouns rather than adjectives or verbs. Overall, the most accurate of these procedures is McQuitty's similarity analysis in combination with a high dimensional feature set.
* 11 pages, latex, uses aclap.sty
Sequential Model Selection for Word Sense Disambiguation
Feb 12, 1997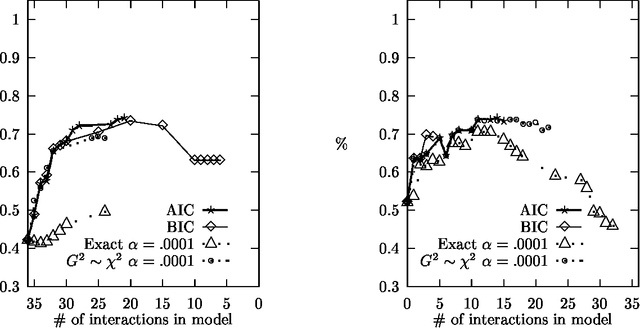

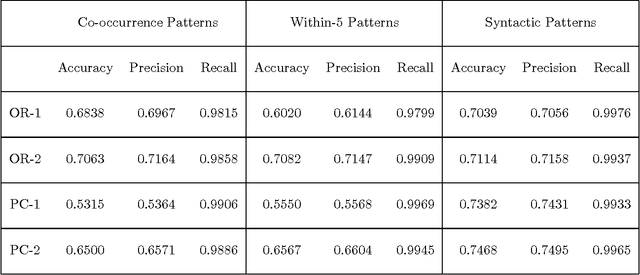
Statistical models of word-sense disambiguation are often based on a small number of contextual features or on a model that is assumed to characterize the interactions among a set of features. Model selection is presented as an alternative to these approaches, where a sequential search of possible models is conducted in order to find the model that best characterizes the interactions among features. This paper expands existing model selection methodology and presents the first comparative study of model selection search strategies and evaluation criteria when applied to the problem of building probabilistic classifiers for word-sense disambiguation.
* 8 pages, Latex, uses aclap.sty
The Measure of a Model
Apr 28, 1996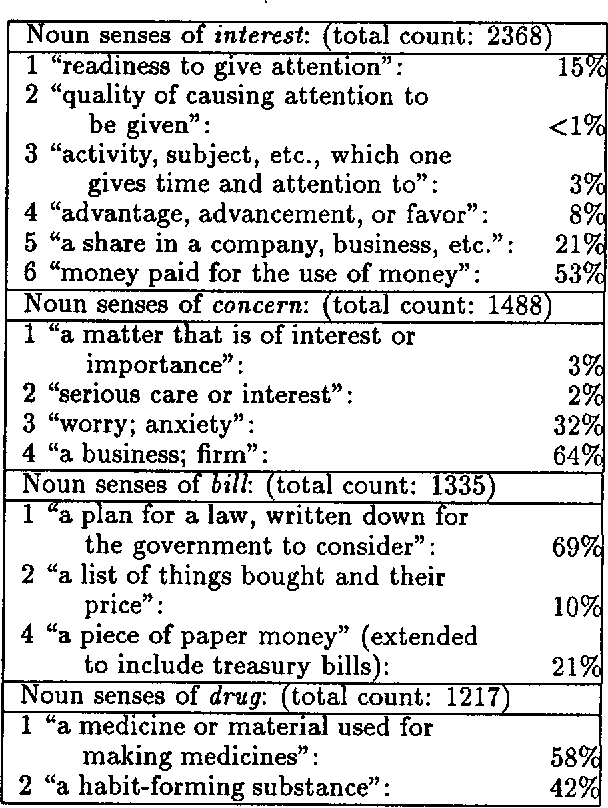
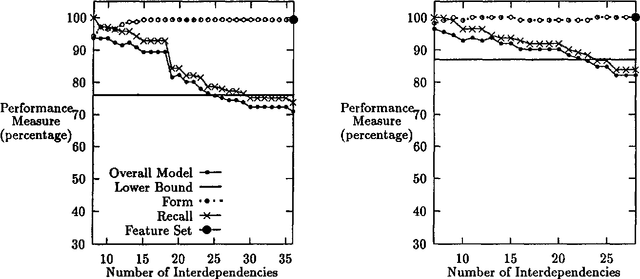

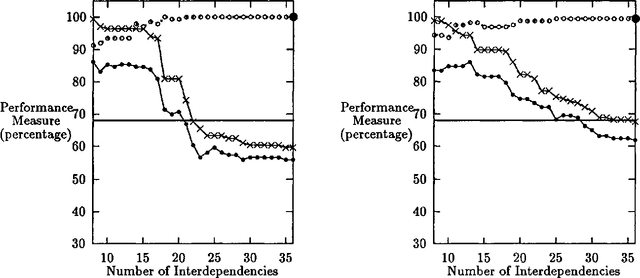
This paper describes measures for evaluating the three determinants of how well a probabilistic classifier performs on a given test set. These determinants are the appropriateness, for the test set, of the results of (1) feature selection, (2) formulation of the parametric form of the model, and (3) parameter estimation. These are part of any model formulation procedure, even if not broken out as separate steps, so the tradeoffs explored in this paper are relevant to a wide variety of methods. The measures are demonstrated in a large experiment, in which they are used to analyze the results of roughly 300 classifiers that perform word-sense disambiguation.
* 12 pages, uuencoded compressed postscript file
Word-Sense Disambiguation Using Decomposable Models
Jun 01, 1994
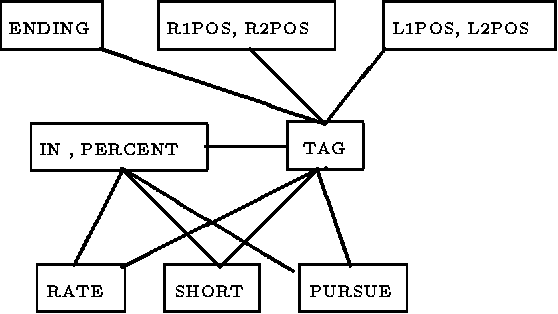

Most probabilistic classifiers used for word-sense disambiguation have either been based on only one contextual feature or have used a model that is simply assumed to characterize the interdependencies among multiple contextual features. In this paper, a different approach to formulating a probabilistic model is presented along with a case study of the performance of models produced in this manner for the disambiguation of the noun "interest". We describe a method for formulating probabilistic models that use multiple contextual features for word-sense disambiguation, without requiring untested assumptions regarding the form of the model. Using this approach, the joint distribution of all variables is described by only the most systematic variable interactions, thereby limiting the number of parameters to be estimated, supporting computational efficiency, and providing an understanding of the data.