 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Bring Your Own KG: Self-Supervised Program Synthesis for Zero-Shot KGQA
Nov 14, 2023



We present BYOKG, a universal question-answering (QA) system that can operate on any knowledge graph (KG), requires no human-annotated training data, and can be ready to use within a day -- attributes that are out-of-scope for current KGQA systems. BYOKG draws inspiration from the remarkable ability of humans to comprehend information present in an unseen KG through exploration -- starting at random nodes, inspecting the labels of adjacent nodes and edges, and combining them with their prior world knowledge. In BYOKG, exploration leverages an LLM-backed symbolic agent that generates a diverse set of query-program exemplars, which are then used to ground a retrieval-augmented reasoning procedure to predict programs for arbitrary questions. BYOKG is effective over both small- and large-scale graphs, showing dramatic gains in QA accuracy over a zero-shot baseline of 27.89 and 58.02 F1 on GrailQA and MetaQA, respectively. On GrailQA, we further show that our unsupervised BYOKG outperforms a supervised in-context learning method, demonstrating the effectiveness of exploration. Lastly, we find that performance of BYOKG reliably improves with continued exploration as well as improvements in the base LLM, notably outperforming a state-of-the-art fine-tuned model by 7.08 F1 on a sub-sampled zero-shot split of GrailQA.
Evaluating the Impact of a Hierarchical Discourse Representation on Entity Coreference Resolution Performance
Apr 20, 2021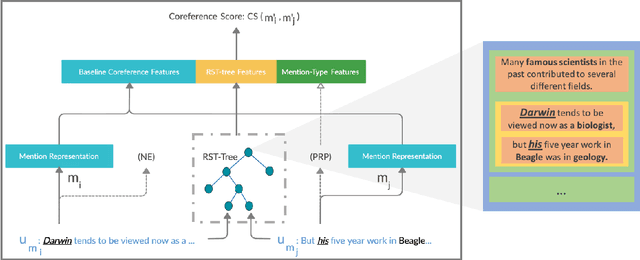
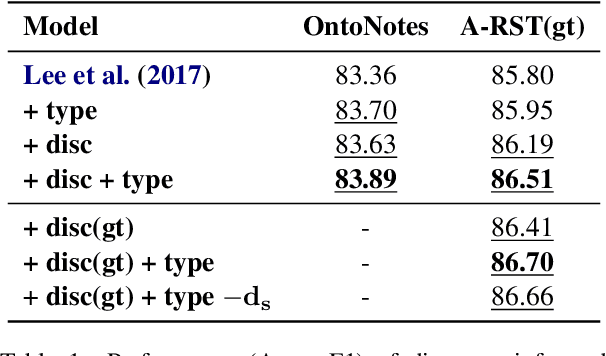
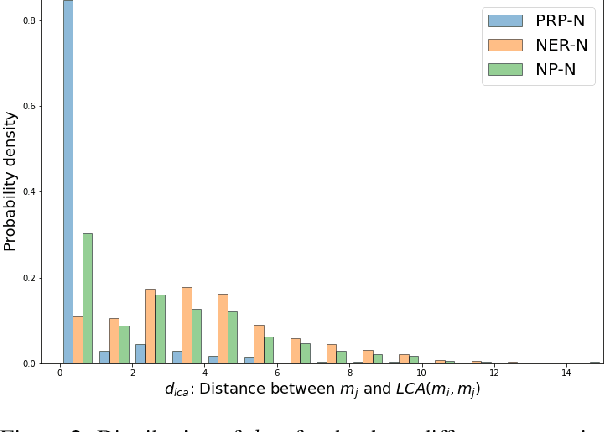
Recent work on entity coreference resolution (CR) follows current trends in Deep Learning applied to embeddings and relatively simple task-related features. SOTA models do not make use of hierarchical representations of discourse structure. In this work, we leverage automatically constructed discourse parse trees within a neural approach and demonstrate a significant improvement on two benchmark entity coreference-resolution datasets. We explore how the impact varies depending upon the type of mention.
Using Type Information to Improve Entity Coreference Resolution
Oct 12, 2020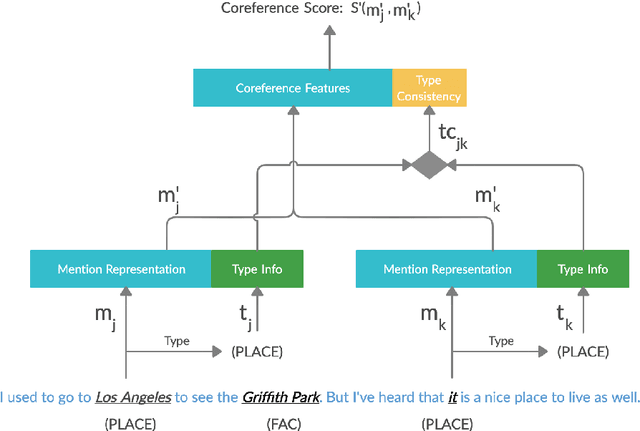
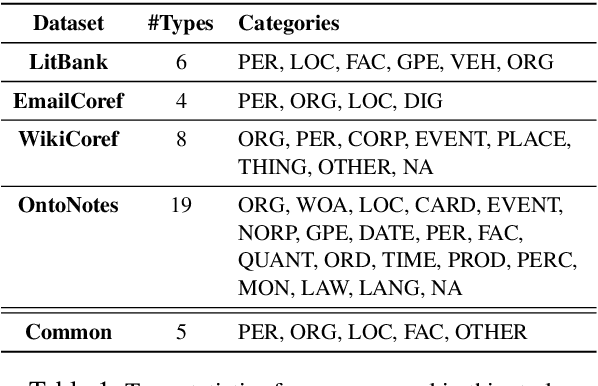
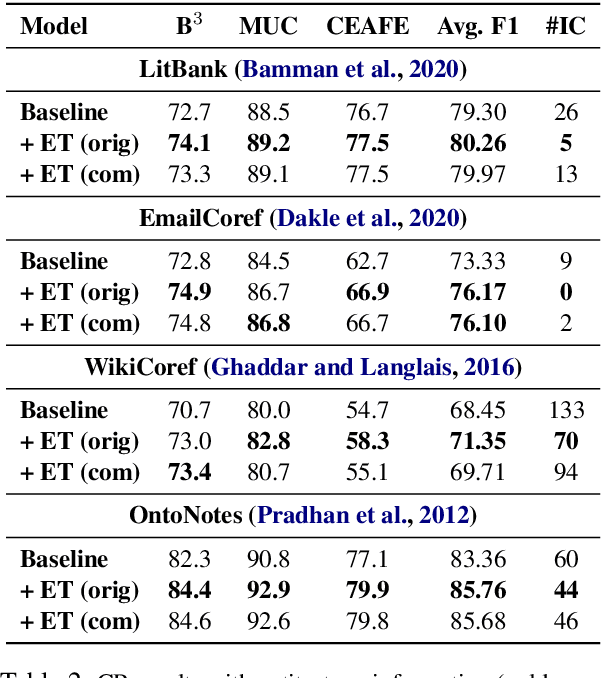
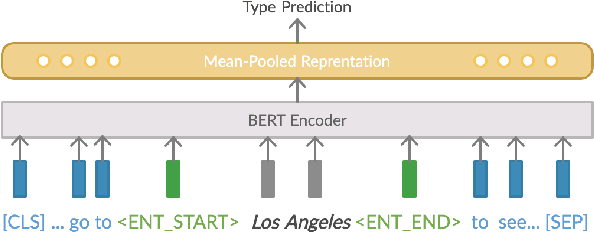
Coreference resolution (CR) is an essential part of discourse analysis. Most recently, neural approaches have been proposed to improve over SOTA models from earlier paradigms. So far none of the published neural models leverage external semantic knowledge such as type information. This paper offers the first such model and evaluation, demonstrating modest gains in accuracy by introducing either gold standard or predicted types. In the proposed approach, type information serves both to (1) improve mention representation and (2) create a soft type consistency check between coreference candidate mentions. Our evaluation covers two different grain sizes of types over four different benchmark corpora.
MedFilter: Improving Extraction of Task-relevant Utterances through Integration of Discourse Structure and Ontological Knowledge
Oct 07, 2020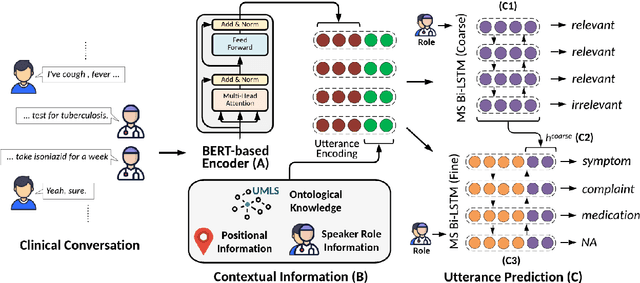
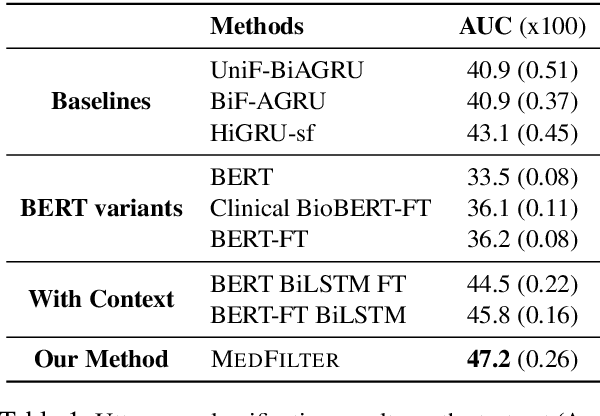
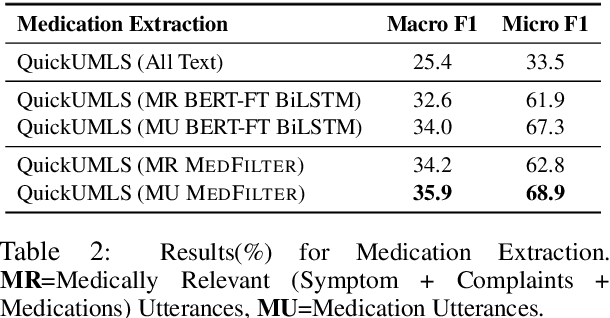
Information extraction from conversational data is particularly challenging because the task-centric nature of conversation allows for effective communication of implicit information by humans, but is challenging for machines. The challenges may differ between utterances depending on the role of the speaker within the conversation, especially when relevant expertise is distributed asymmetrically across roles. Further, the challenges may also increase over the conversation as more shared context is built up through information communicated implicitly earlier in the dialogue. In this paper, we propose the novel modeling approach MedFilter, which addresses these insights in order to increase performance at identifying and categorizing task-relevant utterances, and in so doing, positively impacts performance at a downstream information extraction task. We evaluate this approach on a corpus of nearly 7,000 doctor-patient conversations where MedFilter is used to identify medically relevant contributions to the discussion (achieving a 10% improvement over SOTA baselines in terms of area under the PR curve). Identifying task-relevant utterances benefits downstream medical processing, achieving improvements of 15%, 105%, and 23% respectively for the extraction of symptoms, medications, and complaints.
LTIatCMU at SemEval-2020 Task 11: Incorporating Multi-Level Features for Multi-Granular Propaganda Span Identification
Aug 20, 2020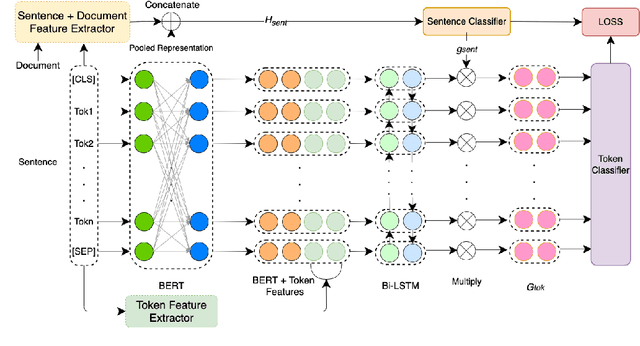

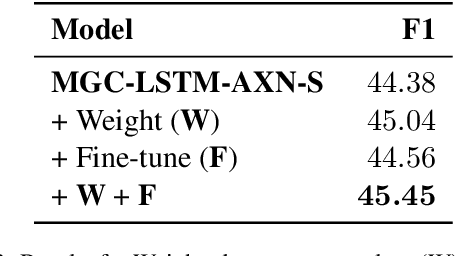
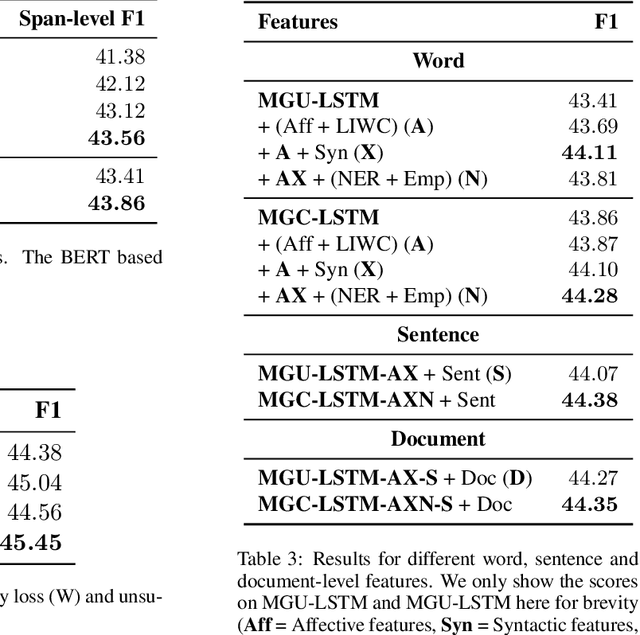
In this paper we describe our submission for the task of Propaganda Span Identification in news articles. We introduce a BERT-BiLSTM based span-level propaganda classification model that identifies which token spans within the sentence are indicative of propaganda. The "multi-granular" model incorporates linguistic knowledge at various levels of text granularity, including word, sentence and document level syntactic, semantic and pragmatic affect features, which significantly improve model performance, compared to its language-agnostic variant. To facilitate better representation learning, we also collect a corpus of 10k news articles, and use it for fine-tuning the model. The final model is a majority-voting ensemble which learns different propaganda class boundaries by leveraging different subsets of incorporated knowledge and attains $4^{th}$ position on the test leaderboard. Our final model and code is released at https://github.com/sopu/PropagandaSemEval2020.
Surveys without Questions: A Reinforcement Learning Approach
Jun 11, 2020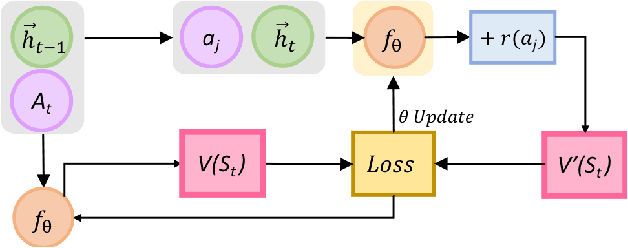
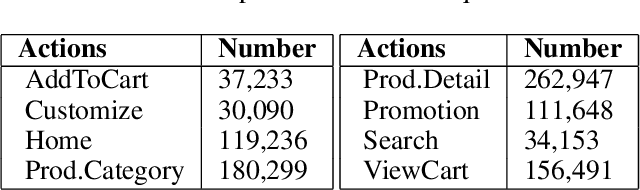

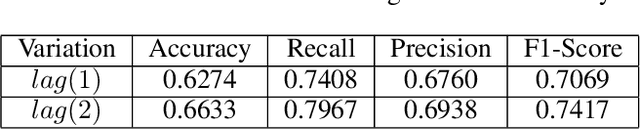
The 'old world' instrument, survey, remains a tool of choice for firms to obtain ratings of satisfaction and experience that customers realize while interacting online with firms. While avenues for survey have evolved from emails and links to pop-ups while browsing, the deficiencies persist. These include - reliance on ratings of very few respondents to infer about all customers' online interactions; failing to capture a customer's interactions over time since the rating is a one-time snapshot; and inability to tie back customers' ratings to specific interactions because ratings provided relate to all interactions. To overcome these deficiencies we extract proxy ratings from clickstream data, typically collected for every customer's online interactions, by developing an approach based on Reinforcement Learning (RL). We introduce a new way to interpret values generated by the value function of RL, as proxy ratings. Our approach does not need any survey data for training. Yet, on validation against actual survey data, proxy ratings yield reasonable performance results. Additionally, we offer a new way to draw insights from values of the value function, which allow associating specific interactions to their proxy ratings. We introduce two new metrics to represent ratings - one, customer-level and the other, aggregate-level for click actions across customers. Both are defined around proportion of all pairwise, successive actions that show increase in proxy ratings. This intuitive customer-level metric enables gauging the dynamics of ratings over time and is a better predictor of purchase than customer ratings from survey. The aggregate-level metric allows pinpointing actions that help or hurt experience. In sum, proxy ratings computed unobtrusively from clickstream, for every action, for each customer, and for every session can offer interpretable and more insightful alternative to surveys.
* The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)
Generating SOAP Notes from Doctor-Patient Conversations
May 04, 2020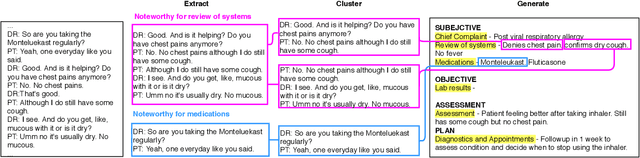
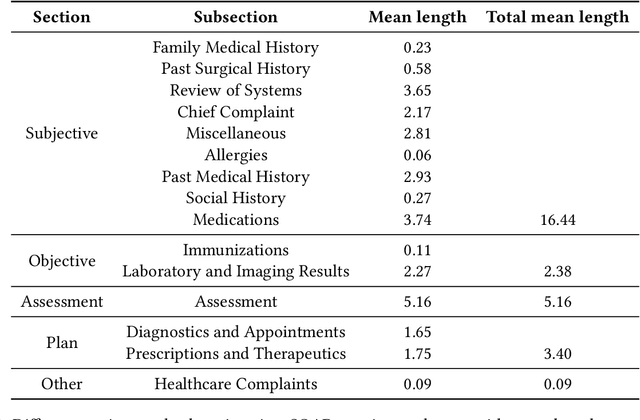
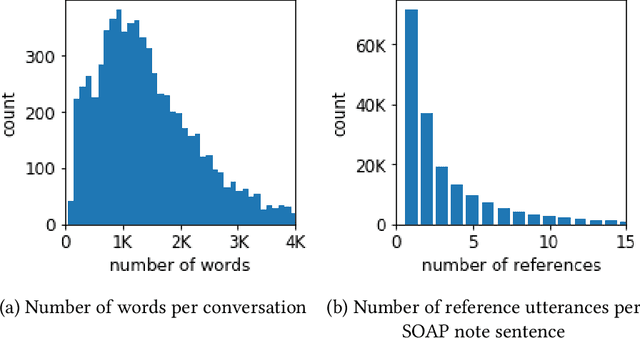
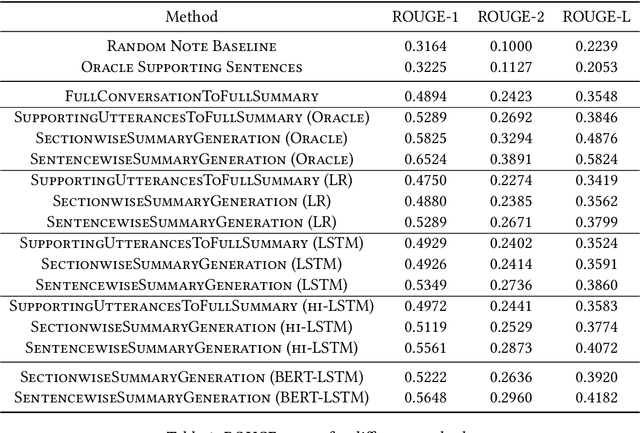
Following each patient visit, physicians must draft detailed clinical summaries called SOAP notes. Moreover, with electronic health records, these notes must be digitized. For all the benefits of this documentation the process remains onerous, contributing to increasing physician burnout. In a parallel development, patients increasingly record audio from their visits (with consent), often through dedicated apps. In this paper, we present the first study to evaluate complete pipelines for leveraging these transcripts to train machine learning model to generate these notes. We first describe a unique dataset of patient visit records, consisting of transcripts, paired SOAP notes, and annotations marking noteworthy utterances that support each summary sentence. We decompose the problem into extractive and abstractive subtasks, exploring a spectrum of approaches according to how much they demand from each component. Our best performing method first (i) extracts noteworthy utterances via multi-label classification assigns them to summary section(s); (ii) clusters noteworthy utterances on a per-section basis; and (iii) generates the summary sentences by conditioning on the corresponding cluster and the subsection of the SOAP sentence to be generated. Compared to an end-to-end approach that generates the full SOAP note from the full conversation, our approach improves by 7 ROUGE-1 points. Oracle experiments indicate that fixing our generative capabilities, improvements in extraction alone could provide (up to) a further 9 ROUGE point gain.
Aff2Vec: Affect--Enriched Distributional Word Representations
May 21, 2018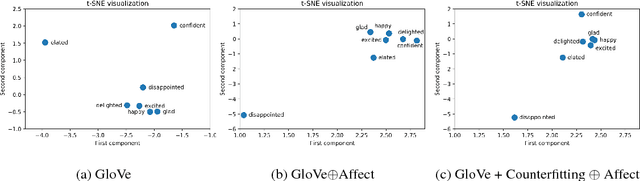
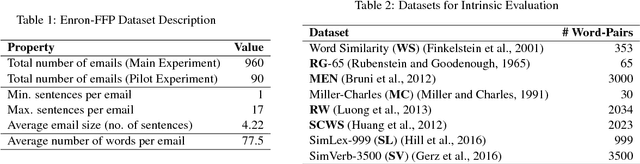
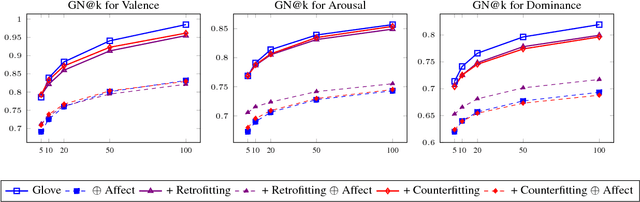

Human communication includes information, opinions, and reactions. Reactions are often captured by the affective-messages in written as well as verbal communications. While there has been work in affect modeling and to some extent affective content generation, the area of affective word distributions in not well studied. Synsets and lexica capture semantic relationships across words. These models however lack in encoding affective or emotional word interpretations. Our proposed model, Aff2Vec provides a method for enriched word embeddings that are representative of affective interpretations of words. Aff2Vec outperforms the state--of--the--art in intrinsic word-similarity tasks. Further, the use of Aff2Vec representations outperforms baseline embeddings in downstream natural language understanding tasks including sentiment analysis, personality detection, and frustration prediction.