Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTScore: Evaluating Text Generation with BERT
Paper and Code



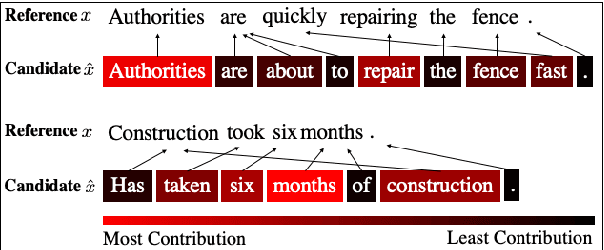
We propose BERTScore, an automatic evaluation metric for text generation. Analogous to common metrics, \method computes a similarity score for each token in the candidate sentence with each token in the reference. However, instead of looking for exact matches, we compute similarity using contextualized BERT embeddings. We evaluate on several machine translation and image captioning benchmarks, and show that BERTScore correlates better with human judgments than existing metrics, often significantly outperforming even task-specific supervised metrics.
* Code available at https://github.com/Tiiiger/bert_score
View paper on
 OpenReview
OpenReview