 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting a Knowledge Base of Mechanisms from COVID-19 Papers
Paper and Code
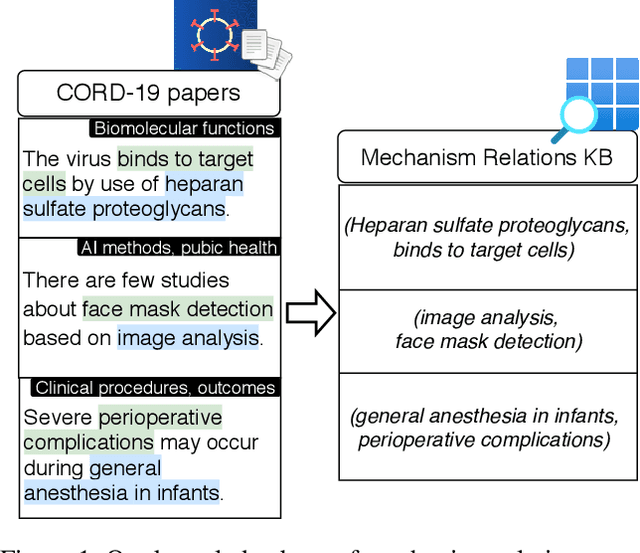
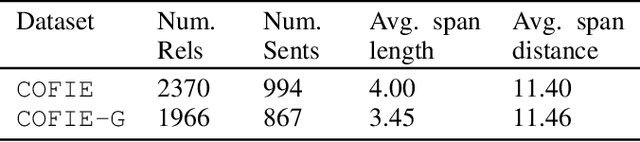

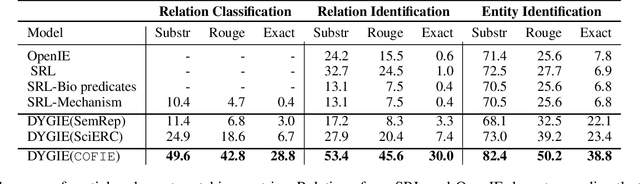
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.