 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


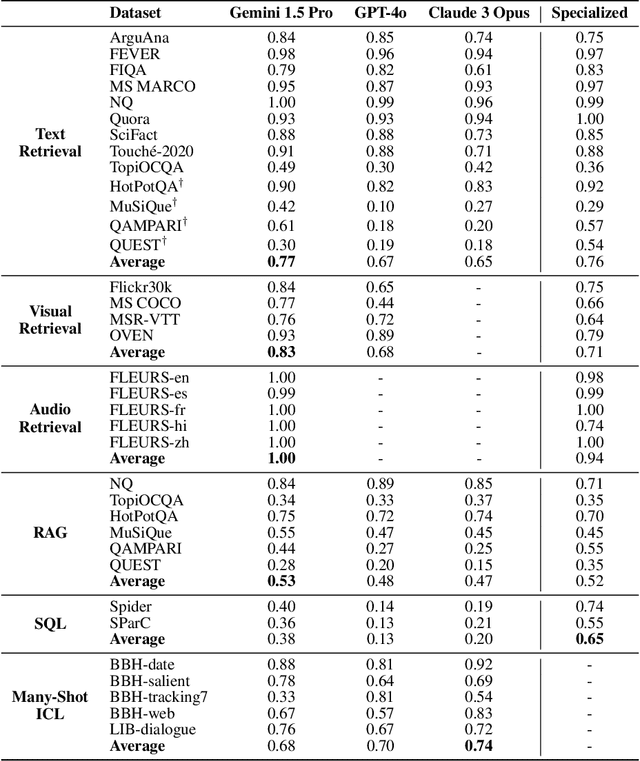
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Dialog Inpainting: Turning Documents into Dialogs
May 31, 2022
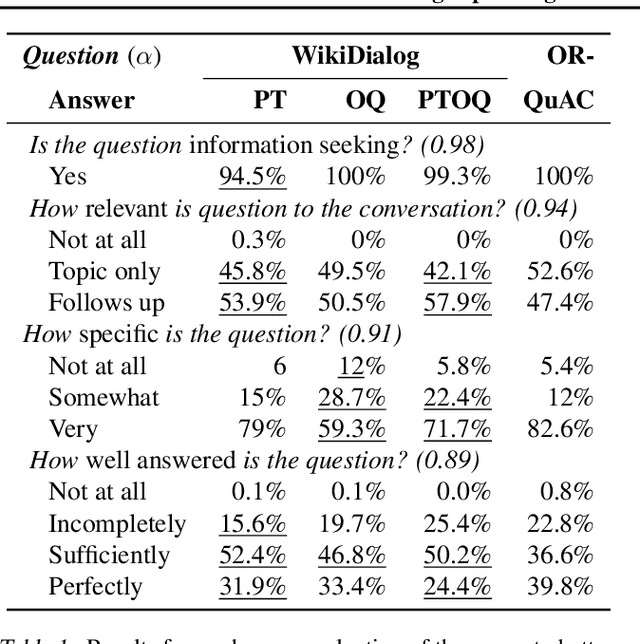
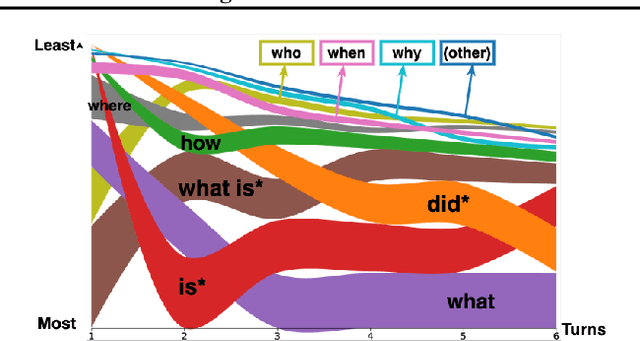
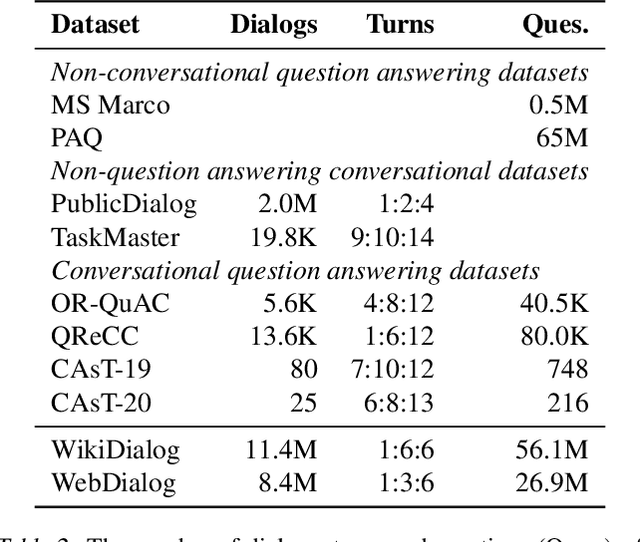
Many important questions (e.g. "How to eat healthier?") require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer's utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs -- 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020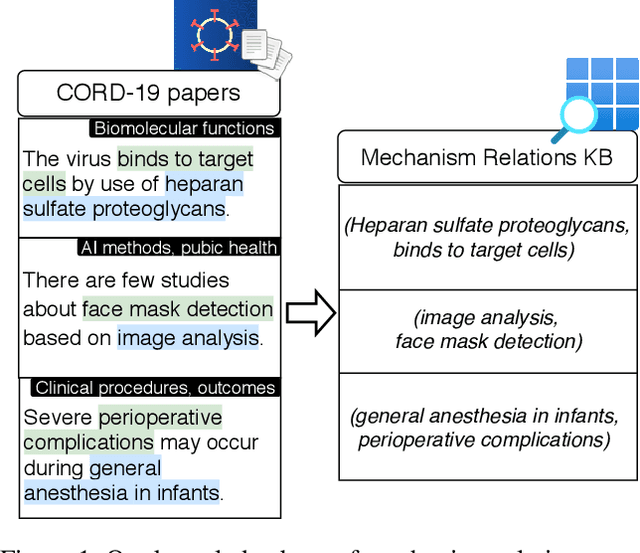
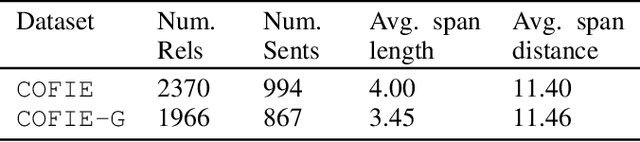

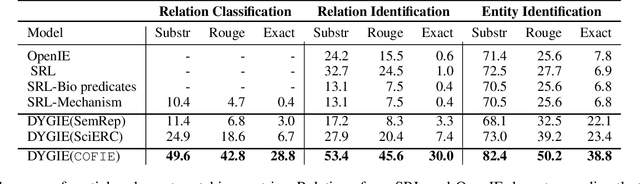
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.
Procedural Reading Comprehension with Attribute-Aware Context Flow
Mar 31, 2020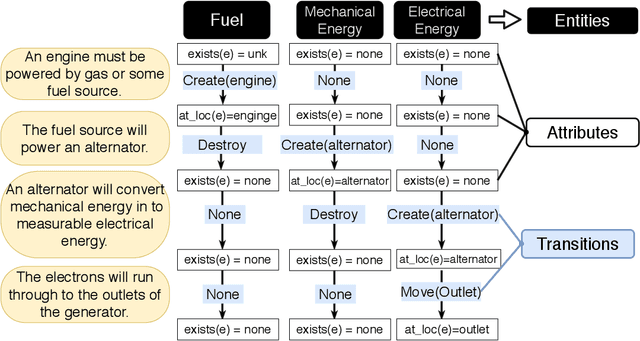


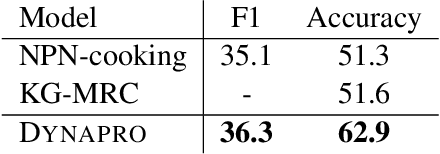
Procedural texts often describe processes (e.g., photosynthesis and cooking) that happen over entities (e.g., light, food). In this paper, we introduce an algorithm for procedural reading comprehension by translating the text into a general formalism that represents processes as a sequence of transitions over entity attributes (e.g., location, temperature). Leveraging pre-trained language models, our model obtains entity-aware and attribute-aware representations of the text by joint prediction of entity attributes and their transitions. Our model dynamically obtains contextual encodings of the procedural text exploiting information that is encoded about previous and current states to predict the transition of a certain attribute which can be identified as a span of text or from a pre-defined set of classes. Moreover, our model achieves state of the art results on two procedural reading comprehension datasets, namely ProPara and npn-cooking
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
May 30, 2019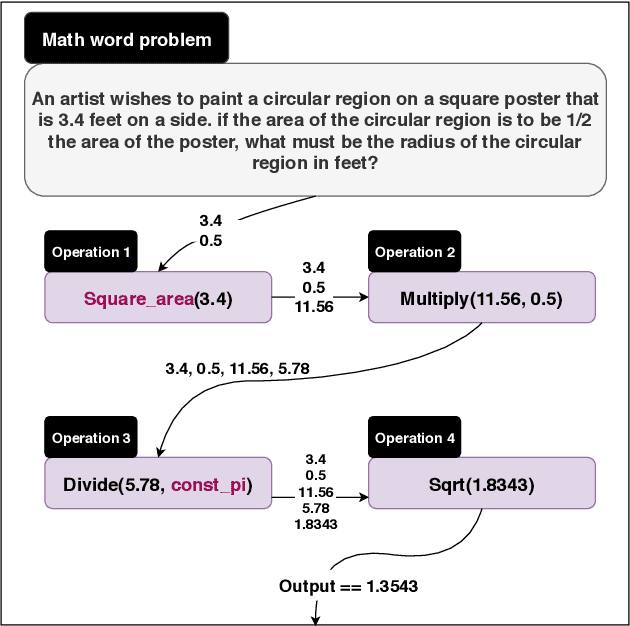
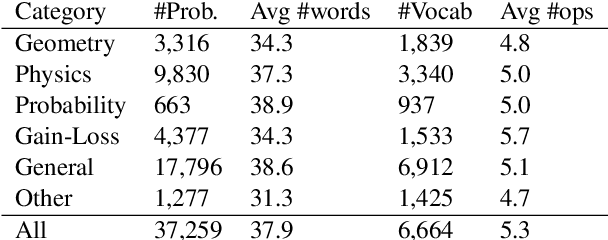

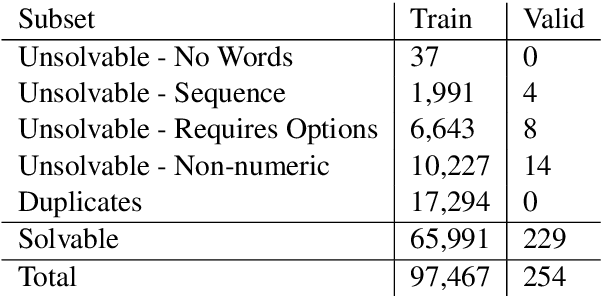
We introduce a large-scale dataset of math word problems and an interpretable neural math problem solver that learns to map problems to operation programs. Due to annotation challenges, current datasets in this domain have been either relatively small in scale or did not offer precise operational annotations over diverse problem types. We introduce a new representation language to model precise operation programs corresponding to each math problem that aim to improve both the performance and the interpretability of the learned models. Using this representation language, our new dataset, MathQA, significantly enhances the AQuA dataset with fully-specified operational programs. We additionally introduce a neural sequence-to-program model enhanced with automatic problem categorization. Our experiments show improvements over competitive baselines in our MathQA as well as the AQuA dataset. The results are still significantly lower than human performance indicating that the dataset poses new challenges for future research. Our dataset is available at: https://math-qa.github.io/math-QA/