 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Score to Sound: An End-to-End MIDI-to-Motion Pipeline for Robotic Cello Performance
Jan 07, 2026Robot musicians require precise control to obtain proper note accuracy, sound quality, and musical expression. Performance of string instruments, such as violin and cello, presents a significant challenge due to the precise control required over bow angle and pressure to produce the desired sound. While prior robotic cellists focus on accurate bowing trajectories, these works often rely on expensive motion capture techniques, and fail to sightread music in a human-like way. We propose a novel end-to-end MIDI score to robotic motion pipeline which converts musical input directly into collision-aware bowing motions for a UR5e robot cellist. Through use of Universal Robot Freedrive feature, our robotic musician can achieve human-like sound without the need for motion capture. Additionally, this work records live joint data via Real-Time Data Exchange (RTDE) as the robot plays, providing labeled robotic playing data from a collection of five standard pieces to the research community. To demonstrate the effectiveness of our method in comparison to human performers, we introduce the Musical Turing Test, in which a collection of 132 human participants evaluate our robot's performance against a human baseline. Human reference recordings are also released, enabling direct comparison for future studies. This evaluation technique establishes the first benchmark for robotic cello performance. Finally, we outline a residual reinforcement learning methodology to improve upon baseline robotic controls, highlighting future opportunities for improved string-crossing efficiency and sound quality.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022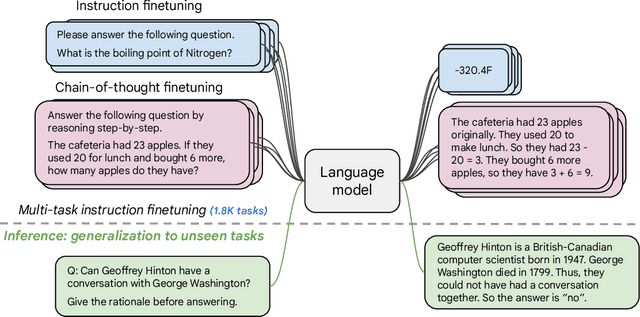

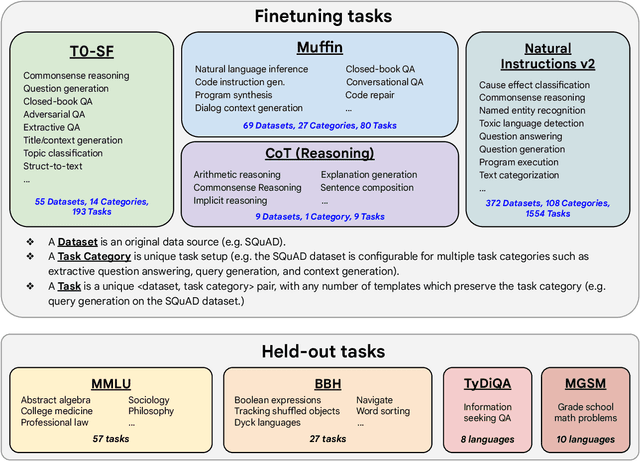

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Dialog Inpainting: Turning Documents into Dialogs
May 31, 2022
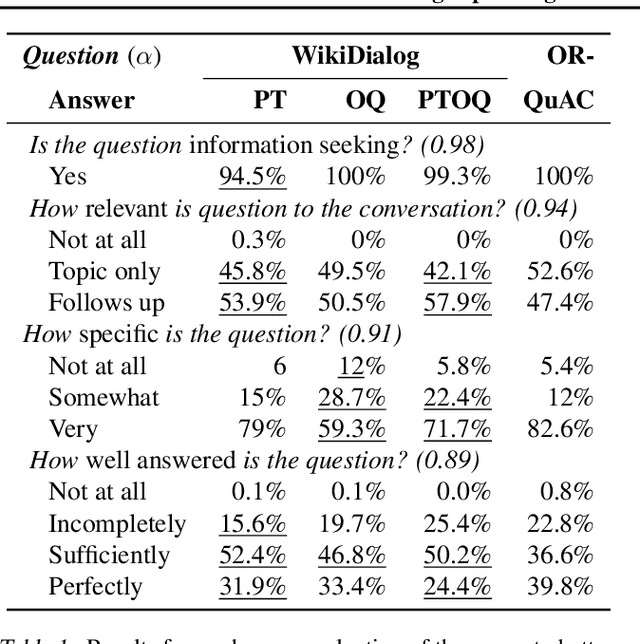
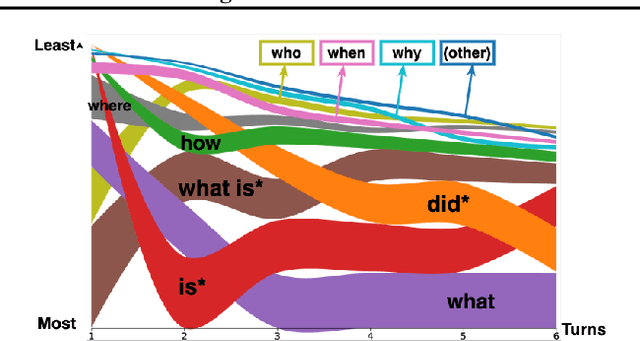
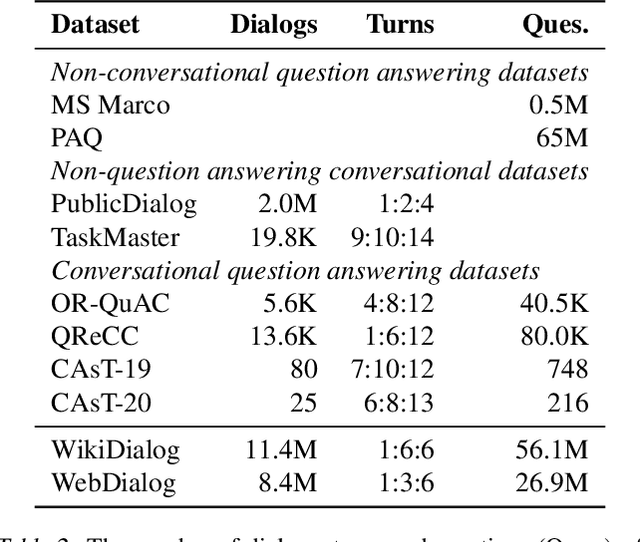
Many important questions (e.g. "How to eat healthier?") require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer's utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs -- 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
Mixture-of-Experts with Expert Choice Routing
Feb 18, 2022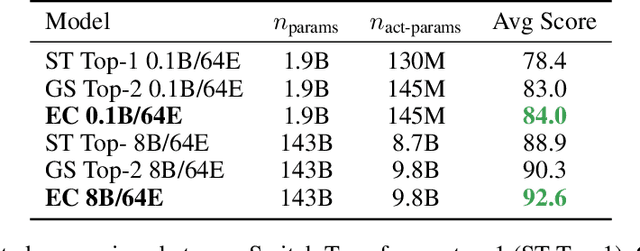
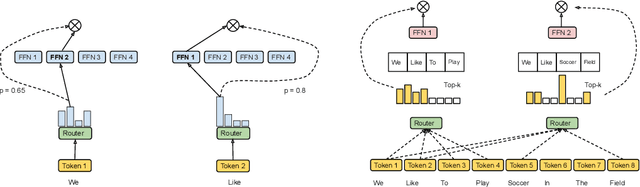


Sparsely-activated Mixture-of-experts (MoE) models allow the number of parameters to greatly increase while keeping the amount of computation for a given token or a given sample unchanged. However, a poor expert routing strategy (e.g. one resulting in load imbalance) can cause certain experts to be under-trained, leading to an expert being under or over-specialized. Prior work allocates a fixed number of experts to each token using a top-k function regardless of the relative importance of different tokens. To address this, we propose a heterogeneous mixture-of-experts employing an expert choice method. Instead of letting tokens select the top-k experts, we have experts selecting the top-k tokens. As a result, each token can be routed to a variable number of experts and each expert can have a fixed bucket size. We systematically study pre-training speedups using the same computational resources of the Switch Transformer top-1 and GShard top-2 gating of prior work and find that our method improves training convergence time by more than 2x. For the same computational cost, our method demonstrates higher performance in fine-tuning 11 selected tasks in the GLUE and SuperGLUE benchmarks. For a smaller activation cost, our method outperforms the T5 dense model in 7 out of the 11 tasks.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022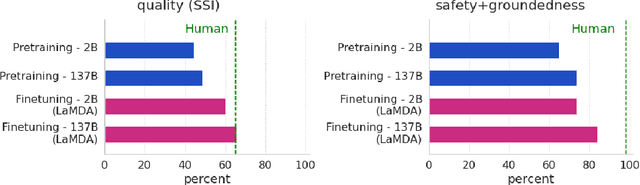
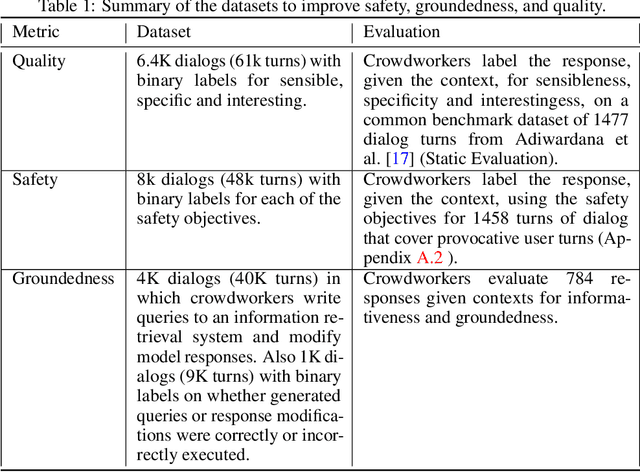

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Feature Selection Facilitates Learning Mixtures of Discrete Product Distributions
Nov 25, 2017



Feature selection can facilitate the learning of mixtures of discrete random variables as they arise, e.g. in crowdsourcing tasks. Intuitively, not all workers are equally reliable but, if the less reliable ones could be eliminated, then learning should be more robust. By analogy with Gaussian mixture models, we seek a low-order statistical approach, and here introduce an algorithm based on the (pairwise) mutual information. This induces an order over workers that is well structured for the `one coin' model. More generally, it is justified by a goodness-of-fit measure and is validated empirically. Improvement in real data sets can be substantial.
Stagewise Learning for Sparse Clustering of Discretely-Valued Data
May 28, 2016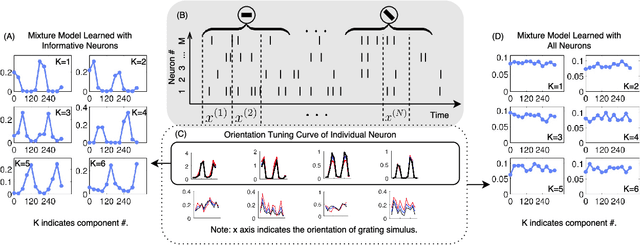
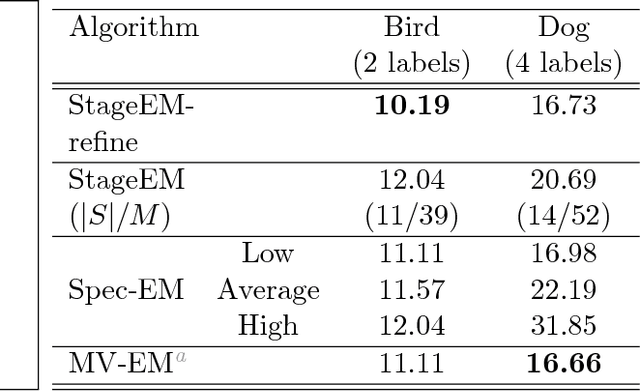
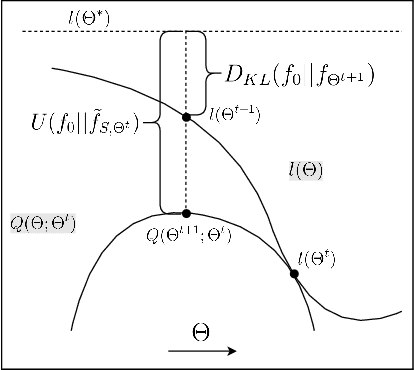
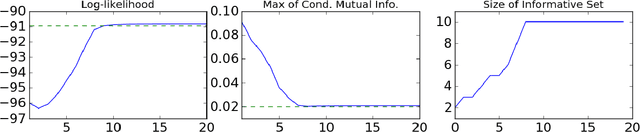
The performance of EM in learning mixtures of product distributions often depends on the initialization. This can be problematic in crowdsourcing and other applications, e.g. when a small number of 'experts' are diluted by a large number of noisy, unreliable participants. We develop a new EM algorithm that is driven by these experts. In a manner that differs from other approaches, we start from a single mixture class. The algorithm then develops the set of 'experts' in a stagewise fashion based on a mutual information criterion. At each stage EM operates on this subset of the players, effectively regularizing the E rather than the M step. Experiments show that stagewise EM outperforms other initialization techniques for crowdsourcing and neurosciences applications, and can guide a full EM to results comparable to those obtained knowing the exact distribution.