 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagewise Learning for Sparse Clustering of Discretely-Valued Data
Paper and Code
May 28, 2016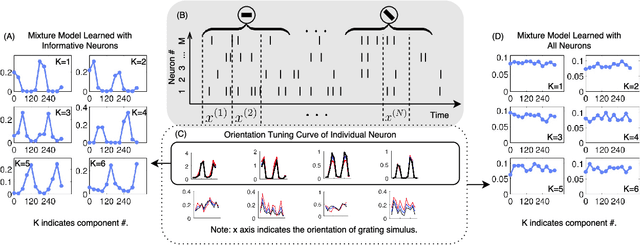
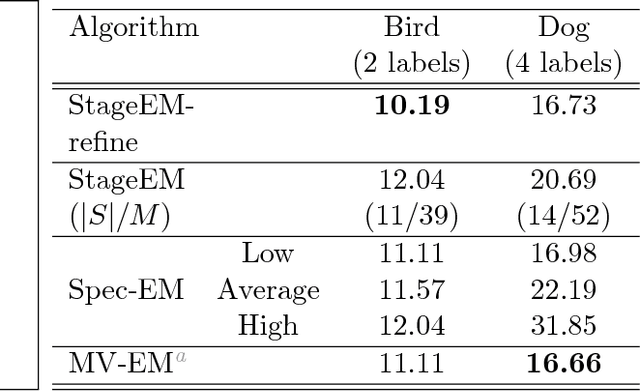
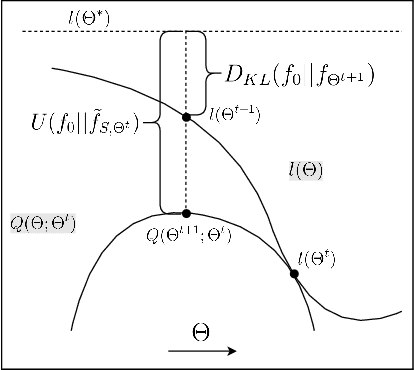
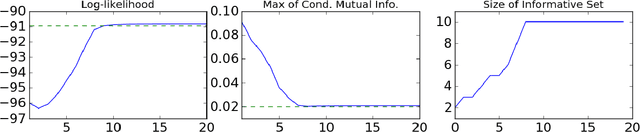
The performance of EM in learning mixtures of product distributions often depends on the initialization. This can be problematic in crowdsourcing and other applications, e.g. when a small number of 'experts' are diluted by a large number of noisy, unreliable participants. We develop a new EM algorithm that is driven by these experts. In a manner that differs from other approaches, we start from a single mixture class. The algorithm then develops the set of 'experts' in a stagewise fashion based on a mutual information criterion. At each stage EM operates on this subset of the players, effectively regularizing the E rather than the M step. Experiments show that stagewise EM outperforms other initialization techniques for crowdsourcing and neurosciences applications, and can guide a full EM to results comparable to those obtained knowing the exact distribution.