 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Instruction-Following Evaluation for Large Language Models
Nov 14, 2023
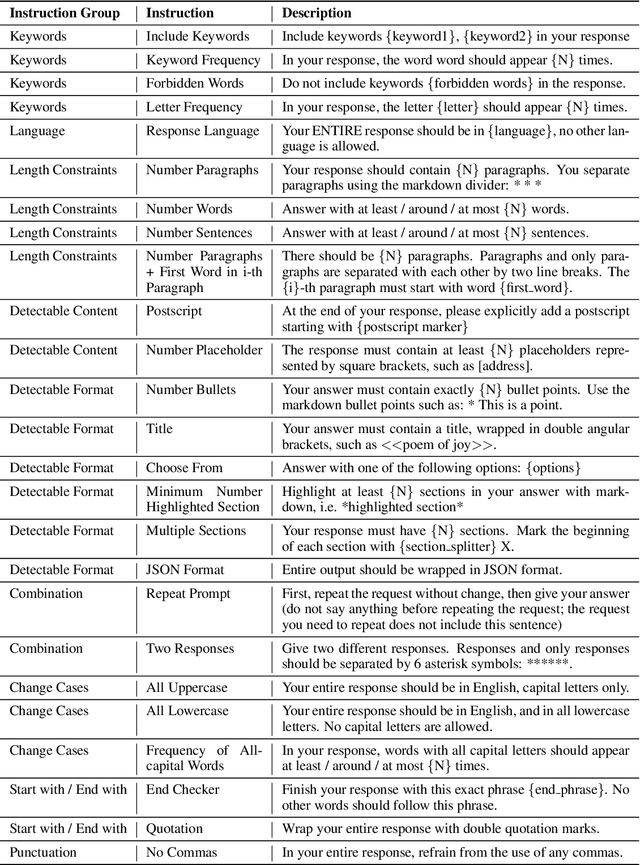
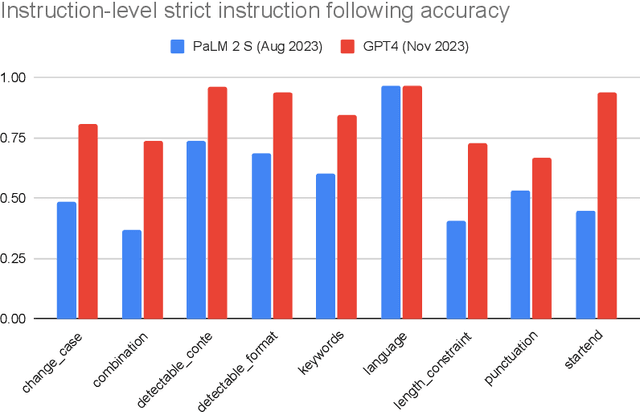

One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference
Apr 11, 2023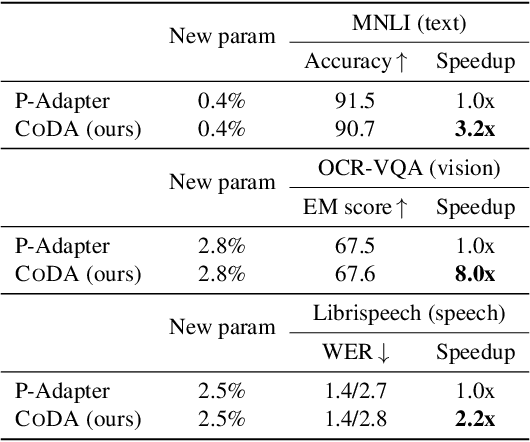

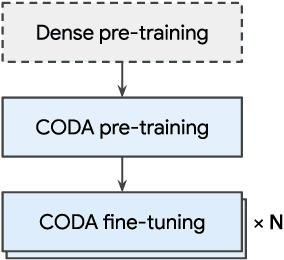
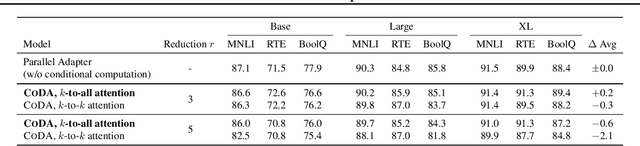
We propose Conditional Adapter (CoDA), a parameter-efficient transfer learning method that also improves inference efficiency. CoDA generalizes beyond standard adapter approaches to enable a new way of balancing speed and accuracy using conditional computation. Starting with an existing dense pretrained model, CoDA adds sparse activation together with a small number of new parameters and a light-weight training phase. Our experiments demonstrate that the CoDA approach provides an unexpectedly efficient way to transfer knowledge. Across a variety of language, vision, and speech tasks, CoDA achieves a 2x to 8x inference speed-up compared to the state-of-the-art Adapter approach with moderate to no accuracy loss and the same parameter efficiency.
CoLT5: Faster Long-Range Transformers with Conditional Computation
Mar 17, 2023Many natural language processing tasks benefit from long inputs, but processing long documents with Transformers is expensive -- not only due to quadratic attention complexity but also from applying feedforward and projection layers to every token. However, not all tokens are equally important, especially for longer documents. We propose CoLT5, a long-input Transformer model that builds on this intuition by employing conditional computation, devoting more resources to important tokens in both feedforward and attention layers. We show that CoLT5 achieves stronger performance than LongT5 with much faster training and inference, achieving SOTA on the long-input SCROLLS benchmark. Moreover, CoLT5 can effectively and tractably make use of extremely long inputs, showing strong gains up to 64k input length.
Multi-Vector Retrieval as Sparse Alignment
Nov 02, 2022



Multi-vector retrieval models improve over single-vector dual encoders on many information retrieval tasks. In this paper, we cast the multi-vector retrieval problem as sparse alignment between query and document tokens. We propose AligneR, a novel multi-vector retrieval model that learns sparsified pairwise alignments between query and document tokens (e.g. `dog' vs. `puppy') and per-token unary saliences reflecting their relative importance for retrieval. We show that controlling the sparsity of pairwise token alignments often brings significant performance gains. While most factoid questions focusing on a specific part of a document require a smaller number of alignments, others requiring a broader understanding of a document favor a larger number of alignments. Unary saliences, on the other hand, decide whether a token ever needs to be aligned with others for retrieval (e.g. `kind' from `kind of currency is used in new zealand}'). With sparsified unary saliences, we are able to prune a large number of query and document token vectors and improve the efficiency of multi-vector retrieval. We learn the sparse unary saliences with entropy-regularized linear programming, which outperforms other methods to achieve sparsity. In a zero-shot setting, AligneR scores 51.1 points nDCG@10, achieving a new retriever-only state-of-the-art on 13 tasks in the BEIR benchmark. In addition, adapting pairwise alignments with a few examples (<= 8) further improves the performance up to 15.7 points nDCG@10 for argument retrieval tasks. The unary saliences of AligneR helps us to keep only 20% of the document token representations with minimal performance loss. We further show that our model often produces interpretable alignments and significantly improves its performance when initialized from larger language models.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022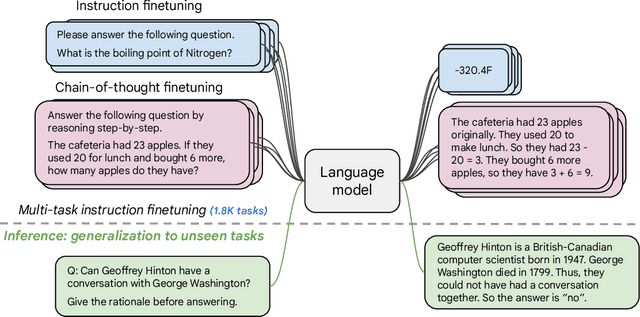

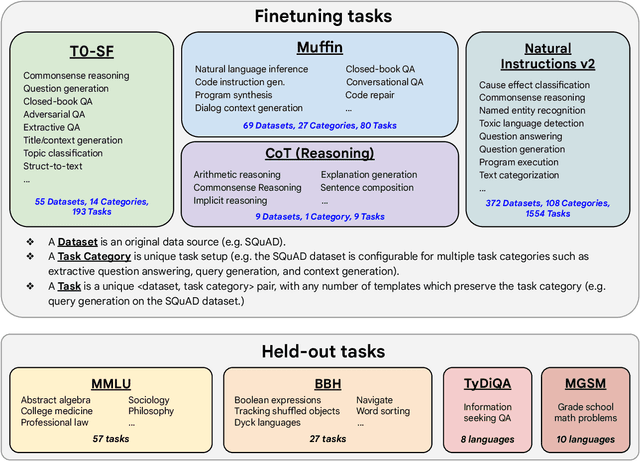

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Breaking BERT: Evaluating and Optimizing Sparsified Attention
Oct 07, 2022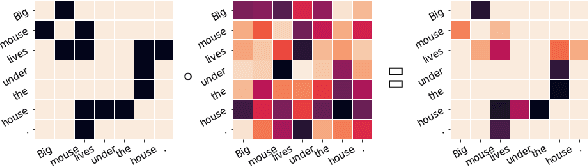


Transformers allow attention between all pairs of tokens, but there is reason to believe that most of these connections - and their quadratic time and memory - may not be necessary. But which ones? We evaluate the impact of sparsification patterns with a series of ablation experiments. First, we compare masks based on syntax, lexical similarity, and token position to random connections, and measure which patterns reduce performance the least. We find that on three common finetuning tasks even using attention that is at least 78% sparse can have little effect on performance if applied at later transformer layers, but that applying sparsity throughout the network reduces performance significantly. Second, we vary the degree of sparsity for three patterns supported by previous work, and find that connections to neighbouring tokens are the most significant. Finally, we treat sparsity as an optimizable parameter, and present an algorithm to learn degrees of neighboring connections that gives a fine-grained control over the accuracy-sparsity trade-off while approaching the performance of existing methods.
Improved Semantic Role Labeling using Parameterized Neighborhood Memory Adaptation
Nov 29, 2020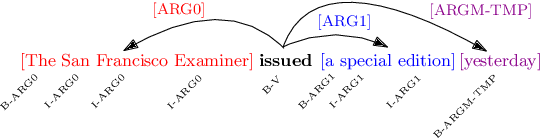
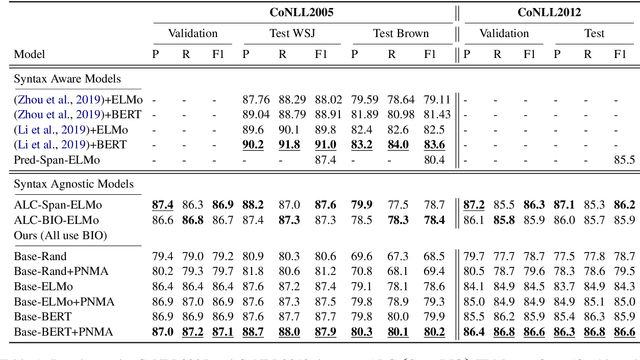
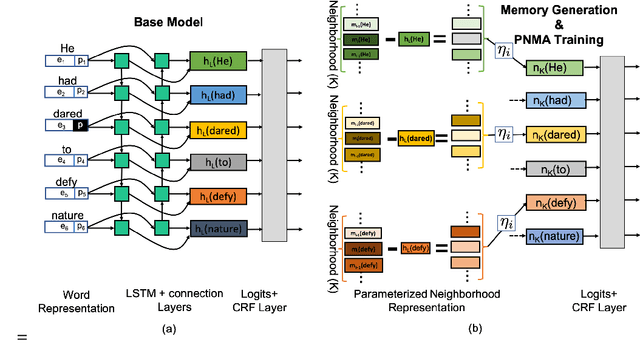
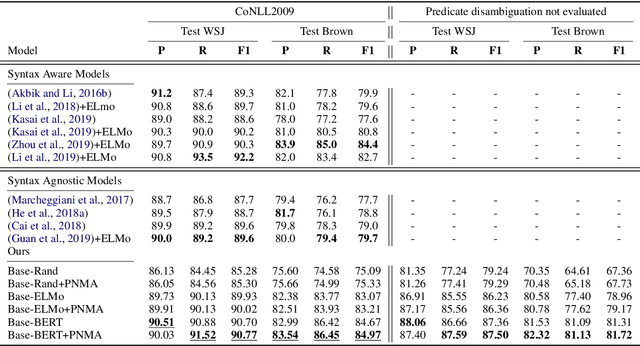
Deep neural models achieve some of the best results for semantic role labeling. Inspired by instance-based learning that utilizes nearest neighbors to handle low-frequency context-specific training samples, we investigate the use of memory adaptation techniques in deep neural models. We propose a parameterized neighborhood memory adaptive (PNMA) method that uses a parameterized representation of the nearest neighbors of tokens in a memory of activations and makes predictions based on the most similar samples in the training data. We empirically show that PNMA consistently improves the SRL performance of the base model irrespective of types of word embeddings. Coupled with contextualized word embeddings derived from BERT, PNMA improves over existing models for both span and dependency semantic parsing datasets, especially on out-of-domain text, reaching F1 scores of 80.2, and 84.97 on CoNLL2005, and CoNLL2009 datasets, respectively.