 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking BERT: Evaluating and Optimizing Sparsified Attention
Paper and Code
Oct 07, 2022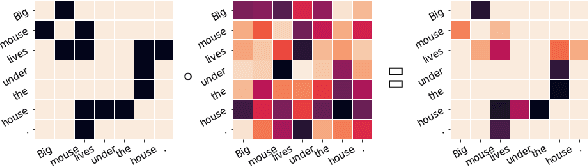
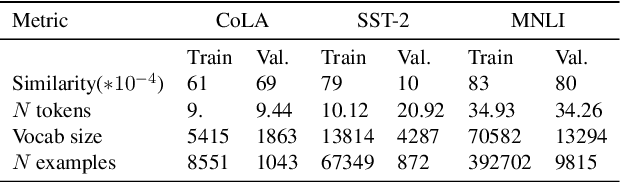


Transformers allow attention between all pairs of tokens, but there is reason to believe that most of these connections - and their quadratic time and memory - may not be necessary. But which ones? We evaluate the impact of sparsification patterns with a series of ablation experiments. First, we compare masks based on syntax, lexical similarity, and token position to random connections, and measure which patterns reduce performance the least. We find that on three common finetuning tasks even using attention that is at least 78% sparse can have little effect on performance if applied at later transformer layers, but that applying sparsity throughout the network reduces performance significantly. Second, we vary the degree of sparsity for three patterns supported by previous work, and find that connections to neighbouring tokens are the most significant. Finally, we treat sparsity as an optimizable parameter, and present an algorithm to learn degrees of neighboring connections that gives a fine-grained control over the accuracy-sparsity trade-off while approaching the performance of existing methods.