 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Content-Based Framework for Cybersecurity Refusal Decisions in Large Language Models
Feb 17, 2026Large language models and LLM-based agents are increasingly used for cybersecurity tasks that are inherently dual-use. Existing approaches to refusal, spanning academic policy frameworks and commercially deployed systems, often rely on broad topic-based bans or offensive-focused taxonomies. As a result, they can yield inconsistent decisions, over-restrict legitimate defenders, and behave brittlely under obfuscation or request segmentation. We argue that effective refusal requires explicitly modeling the trade-off between offensive risk and defensive benefit, rather than relying solely on intent or offensive classification. In this paper, we introduce a content-based framework for designing and auditing cyber refusal policies that makes offense-defense tradeoffs explicit. The framework characterizes requests along five dimensions: Offensive Action Contribution, Offensive Risk, Technical Complexity, Defensive Benefit, and Expected Frequency for Legitimate Users, grounded in the technical substance of the request rather than stated intent. We demonstrate that this content-grounded approach resolves inconsistencies in current frontier model behavior and allows organizations to construct tunable, risk-aware refusal policies.
Leveraging LLM Inconsistency to Boost Pass@k Performance
May 19, 2025Large language models (LLMs) achieve impressive abilities in numerous domains, but exhibit inconsistent performance in response to minor input changes. Rather than view this as a drawback, in this paper we introduce a novel method for leveraging models' inconsistency to boost Pass@k performance. Specifically, we present a "Variator" agent that generates k variants of a given task and submits one candidate solution for each one. Our variant generation approach is applicable to a wide range of domains as it is task agnostic and compatible with free-form inputs. We demonstrate the efficacy of our agent theoretically using a probabilistic model of the inconsistency effect, and show empirically that it outperforms the baseline on the APPS dataset. Furthermore, we establish that inconsistency persists even in frontier reasoning models across coding and cybersecurity domains, suggesting our method is likely to remain relevant for future model generations.
What Makes an Evaluation Useful? Common Pitfalls and Best Practices
Mar 30, 2025

Following the rapid increase in Artificial Intelligence (AI) capabilities in recent years, the AI community has voiced concerns regarding possible safety risks. To support decision-making on the safe use and development of AI systems, there is a growing need for high-quality evaluations of dangerous model capabilities. While several attempts to provide such evaluations have been made, a clear definition of what constitutes a "good evaluation" has yet to be agreed upon. In this practitioners' perspective paper, we present a set of best practices for safety evaluations, drawing on prior work in model evaluation and illustrated through cybersecurity examples. We first discuss the steps of the initial thought process, which connects threat modeling to evaluation design. Then, we provide the characteristics and parameters that make an evaluation useful. Finally, we address additional considerations as we move from building specific evaluations to building a full and comprehensive evaluation suite.
Fair Set Selection: Meritocracy and Social Welfare
Feb 23, 2021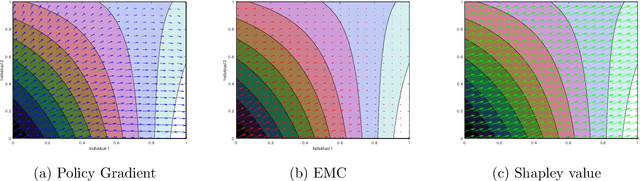
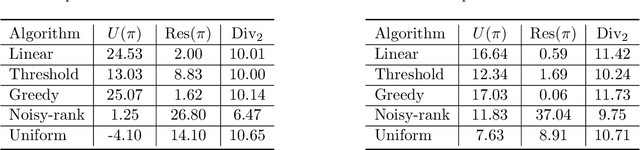
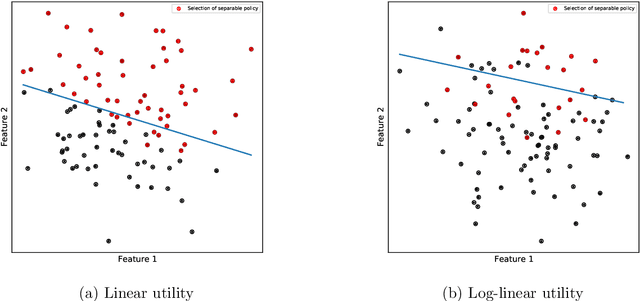
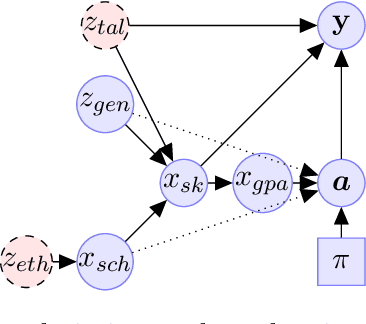
In this paper, we formulate the problem of selecting a set of individuals from a candidate population as a utility maximisation problem. From the decision maker's perspective, it is equivalent to finding a selection policy that maximises expected utility. Our framework leads to the notion of expected marginal contribution (EMC) of an individual with respect to a selection policy as a measure of deviation from meritocracy. In order to solve the maximisation problem, we propose to use a policy gradient algorithm. For certain policy structures, the policy gradients are proportional to EMCs of individuals. Consequently, the policy gradient algorithm leads to a locally optimal solution that has zero EMC, and satisfies meritocracy. For uniform policies, EMC reduces to the Shapley value. EMC also generalises the fair selection properties of Shapley value for general selection policies. We experimentally analyse the effect of different policy structures in a simulated college admission setting and compare with ranking and greedy algorithms. Our results verify that separable linear policies achieve high utility while minimising EMCs. We also show that we can design utility functions that successfully promote notions of group fairness, such as diversity.
Learning a faceted customer segmentation for discovering new business opportunities at Intel
Nov 27, 2019



For sales and marketing organizations within large enterprises, identifying and understanding new markets, customers and partners is a key challenge. Intel's Sales and Marketing Group (SMG) faces similar challenges while growing in new markets and domains and evolving its existing business. In today's complex technological and commercial landscape, there is need for intelligent automation supporting a fine-grained understanding of businesses in order to help SMG sift through millions of companies across many geographies and languages and identify relevant directions. We present a system developed in our company that mines millions of public business web pages, and extracts a faceted customer representation. We focus on two key customer aspects that are essential for finding relevant opportunities: industry segments (ranging from broad verticals such as healthcare, to more specific fields such as 'video analytics') and functional roles (e.g., 'manufacturer' or 'retail'). To address the challenge of labeled data collection, we enrich our data with external information gleaned from Wikipedia, and develop a semi-supervised multi-label, multi-lingual deep learning model that parses customer website texts and classifies them into their respective facets. Our system scans and indexes companies as part of a large-scale knowledge graph that currently holds tens of millions of connected entities with thousands being fetched, enriched and connected to the graph by the hour in real time, and also supports knowledge and insight discovery. In experiments conducted in our company, we are able to significantly boost the performance of sales personnel in the task of discovering new customers and commercial partnership opportunities.