 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Cost-Aware Sequential Hypothesis Testing with Random Costs and Action Cancellation
Dec 22, 2025We study a variant of cost-aware sequential hypothesis testing in which a single active Decision Maker (DM) selects actions with positive, random costs to identify the true hypothesis under an average error constraint, while minimizing the expected total cost. The DM may abort an in-progress action, yielding no sample, by truncating its realized cost at a smaller, tunable deterministic limit, which we term a per-action deadline. We analyze how this cancellation option can be exploited under two cost-revelation models: ex-post, where the cost is revealed only after the sample is obtained, and ex-ante, where the cost accrues before sample acquisition. In the ex-post model, per-action deadlines do not affect the expected total cost, and the cost-error tradeoffs coincide with the baseline obtained by replacing deterministic costs with cost means. In the ex-ante model, we show how per-action deadlines inflate the expected number of times actions are applied, and that the resulting expected total cost can be reduced to the constant-cost setting by introducing an effective per-action cost. We characterize when deadlines are beneficial and study several families in detail.
Convergence of the Deep Galerkin Method for Mean Field Control Problems
May 22, 2024



We establish the convergence of the deep Galerkin method (DGM), a deep learning-based scheme for solving high-dimensional nonlinear PDEs, for Hamilton-Jacobi-Bellman (HJB) equations that arise from the study of mean field control problems (MFCPs). Based on a recent characterization of the value function of the MFCP as the unique viscosity solution of an HJB equation on the simplex, we establish both an existence and convergence result for the DGM. First, we show that the loss functional of the DGM can be made arbitrarily small given that the value function of the MFCP possesses sufficient regularity. Then, we show that if the loss functional of the DGM converges to zero, the corresponding neural network approximators must converge uniformly to the true value function on the simplex. We also provide numerical experiments demonstrating the DGM's ability to generalize to high-dimensional HJB equations.
Deep Backward and Galerkin Methods for the Finite State Master Equation
Mar 08, 2024



This paper proposes and analyzes two neural network methods to solve the master equation for finite-state mean field games (MFGs). Solving MFGs provides approximate Nash equilibria for stochastic, differential games with finite but large populations of agents. The master equation is a partial differential equation (PDE) whose solution characterizes MFG equilibria for any possible initial distribution. The first method we propose relies on backward induction in a time component while the second method directly tackles the PDE without discretizing time. For both approaches, we prove two types of results: there exist neural networks that make the algorithms' loss functions arbitrarily small, and conversely, if the losses are small, then the neural networks are good approximations of the master equation's solution. We conclude the paper with numerical experiments on benchmark problems from the literature up to dimension 15, and a comparison with solutions computed by a classical method for fixed initial distributions.
Learning-based Optimal Admission Control in a Single Server Queuing System
Dec 21, 2022We consider a long-term average profit maximizing admission control problem in an M/M/1 queuing system with a known arrival rate but an unknown service rate. With a fixed reward collected upon service completion and a cost per unit of time enforced on customers waiting in the queue, a dispatcher decides upon arrivals whether to admit the arriving customer or not based on the full history of observations of the queue-length of the system. \cite[Econometrica]{Naor} showed that if all the parameters of the model are known, then it is optimal to use a static threshold policy - admit if the queue-length is less than a predetermined threshold and otherwise not. We propose a learning-based dispatching algorithm and characterize its regret with respect to optimal dispatch policies for the full information model of \cite{Naor}. We show that the algorithm achieves an $O(1)$ regret when all optimal thresholds with full information are non-zero, and achieves an $O(\ln^{3+\epsilon}(N))$ regret in the case that an optimal threshold with full information is $0$ (i.e., an optimal policy is to reject all arrivals), where $N$ is the number of arrivals and $\epsilon>0$.
Covertly Controlling a Linear System
Dec 02, 2022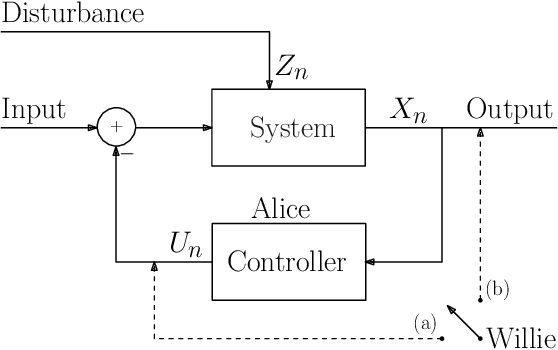
Consider the problem of covertly controlling a linear system. In this problem, Alice desires to control (stabilize or change the behavior of) a linear system, while keeping an observer, Willie, unable to decide if the system is indeed being controlled or not. We formally define the problem, under a model where Willie can only observe the system's output. Focusing on AR(1) systems, we show that when Willie observes the system's output through a clean channel, an inherently unstable linear system can not be covertly stabilized. However, an inherently stable linear system can be covertly controlled, in the sense of covertly changing its parameter or resetting its memory. Moreover, we give positive and negative results for two important controllers: a minimal-information controller, where Alice is allowed to use only $1$ bit per sample, and a maximal-information controller, where Alice is allowed to view the real-valued output. Unlike covert communication, where the trade-off is between rate and covertness, the results reveal an interesting \emph{three--fold} trade--off in covert control: the amount of information used by the controller, control performance and covertness.
Learning a faceted customer segmentation for discovering new business opportunities at Intel
Nov 27, 2019



For sales and marketing organizations within large enterprises, identifying and understanding new markets, customers and partners is a key challenge. Intel's Sales and Marketing Group (SMG) faces similar challenges while growing in new markets and domains and evolving its existing business. In today's complex technological and commercial landscape, there is need for intelligent automation supporting a fine-grained understanding of businesses in order to help SMG sift through millions of companies across many geographies and languages and identify relevant directions. We present a system developed in our company that mines millions of public business web pages, and extracts a faceted customer representation. We focus on two key customer aspects that are essential for finding relevant opportunities: industry segments (ranging from broad verticals such as healthcare, to more specific fields such as 'video analytics') and functional roles (e.g., 'manufacturer' or 'retail'). To address the challenge of labeled data collection, we enrich our data with external information gleaned from Wikipedia, and develop a semi-supervised multi-label, multi-lingual deep learning model that parses customer website texts and classifies them into their respective facets. Our system scans and indexes companies as part of a large-scale knowledge graph that currently holds tens of millions of connected entities with thousands being fetched, enriched and connected to the graph by the hour in real time, and also supports knowledge and insight discovery. In experiments conducted in our company, we are able to significantly boost the performance of sales personnel in the task of discovering new customers and commercial partnership opportunities.
Scanning and Sequential Decision Making for Multi-Dimensional Data - Part II: the Noisy Case
May 20, 2007

We consider the problem of sequential decision making on random fields corrupted by noise. In this scenario, the decision maker observes a noisy version of the data, yet judged with respect to the clean data. In particular, we first consider the problem of sequentially scanning and filtering noisy random fields. In this case, the sequential filter is given the freedom to choose the path over which it traverses the random field (e.g., noisy image or video sequence), thus it is natural to ask what is the best achievable performance and how sensitive this performance is to the choice of the scan. We formally define the problem of scanning and filtering, derive a bound on the best achievable performance and quantify the excess loss occurring when non-optimal scanners are used, compared to optimal scanning and filtering. We then discuss the problem of sequential scanning and prediction of noisy random fields. This setting is a natural model for applications such as restoration and coding of noisy images. We formally define the problem of scanning and prediction of a noisy multidimensional array and relate the optimal performance to the clean scandictability defined by Merhav and Weissman. Moreover, bounds on the excess loss due to sub-optimal scans are derived, and a universal prediction algorithm is suggested. This paper is the second part of a two-part paper. The first paper dealt with sequential decision making on noiseless data arrays, namely, when the decision maker is judged with respect to the same data array it observes.
Scanning and Sequential Decision Making for Multi-Dimensional Data - Part I: the Noiseless Case
May 08, 2007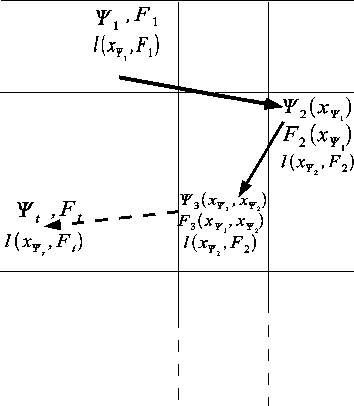
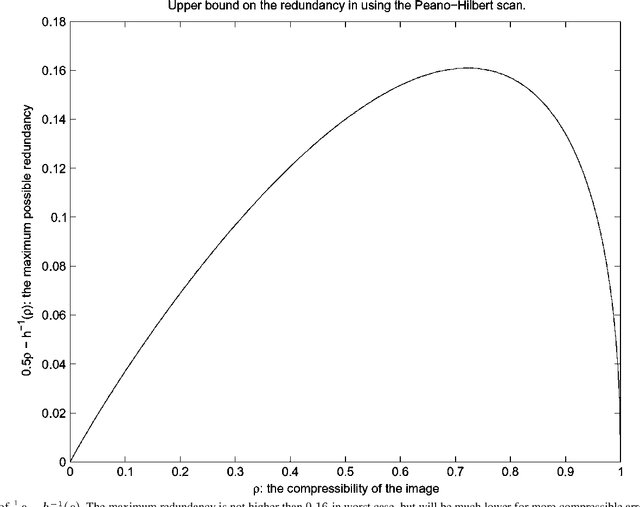
We investigate the problem of scanning and prediction ("scandiction", for short) of multidimensional data arrays. This problem arises in several aspects of image and video processing, such as predictive coding, for example, where an image is compressed by coding the error sequence resulting from scandicting it. Thus, it is natural to ask what is the optimal method to scan and predict a given image, what is the resulting minimum prediction loss, and whether there exist specific scandiction schemes which are universal in some sense. Specifically, we investigate the following problems: First, modeling the data array as a random field, we wish to examine whether there exists a scandiction scheme which is independent of the field's distribution, yet asymptotically achieves the same performance as if this distribution was known. This question is answered in the affirmative for the set of all spatially stationary random fields and under mild conditions on the loss function. We then discuss the scenario where a non-optimal scanning order is used, yet accompanied by an optimal predictor, and derive bounds on the excess loss compared to optimal scanning and prediction. This paper is the first part of a two-part paper on sequential decision making for multi-dimensional data. It deals with clean, noiseless data arrays. The second part deals with noisy data arrays, namely, with the case where the decision maker observes only a noisy version of the data, yet it is judged with respect to the original, clean data.