 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsenseQA 2.0: Exposing the Limits of AI through Gamification
Jan 14, 2022

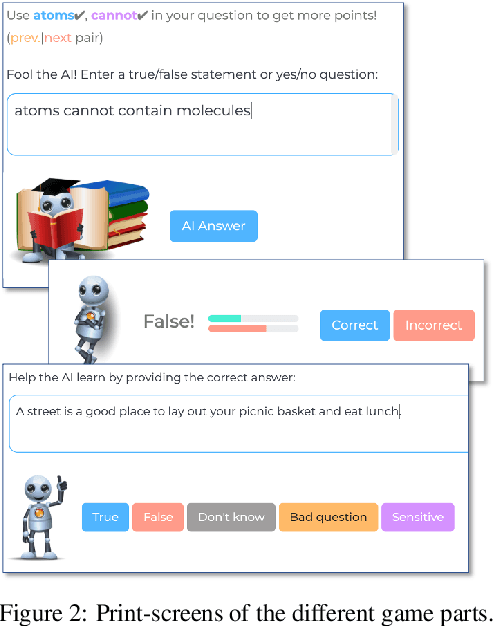
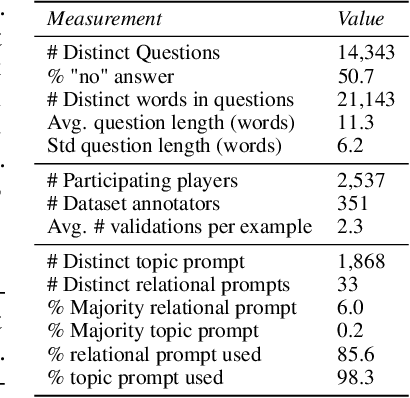
Constructing benchmarks that test the abilities of modern natural language understanding models is difficult - pre-trained language models exploit artifacts in benchmarks to achieve human parity, but still fail on adversarial examples and make errors that demonstrate a lack of common sense. In this work, we propose gamification as a framework for data construction. The goal of players in the game is to compose questions that mislead a rival AI while using specific phrases for extra points. The game environment leads to enhanced user engagement and simultaneously gives the game designer control over the collected data, allowing us to collect high-quality data at scale. Using our method we create CommonsenseQA 2.0, which includes 14,343 yes/no questions, and demonstrate its difficulty for models that are orders-of-magnitude larger than the AI used in the game itself. Our best baseline, the T5-based Unicorn with 11B parameters achieves an accuracy of 70.2%, substantially higher than GPT-3 (52.9%) in a few-shot inference setup. Both score well below human performance which is at 94.1%.
Turning Tables: Generating Examples from Semi-structured Tables for Endowing Language Models with Reasoning Skills
Jul 15, 2021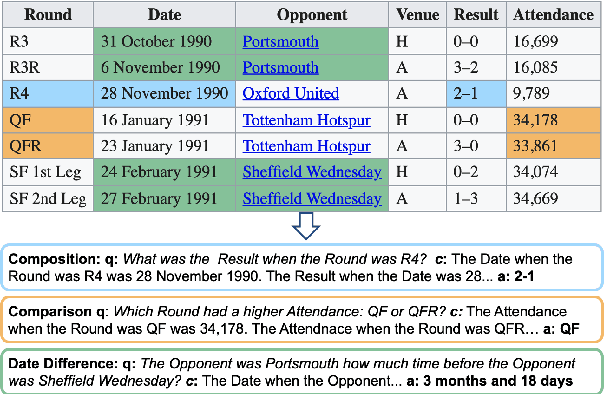
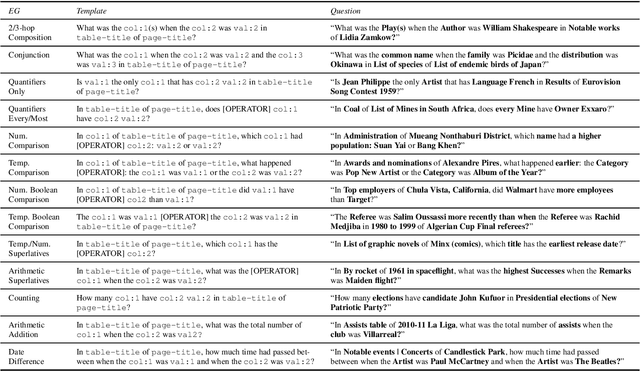
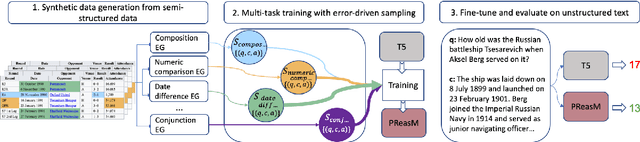
Models pre-trained with a language modeling objective possess ample world knowledge and language skills, but are known to struggle in tasks that require reasoning. In this work, we propose to leverage semi-structured tables, and automatically generate at scale question-paragraph pairs, where answering the question requires reasoning over multiple facts in the paragraph. We add a pre-training step over this synthetic data, which includes examples that require 16 different reasoning skills such as number comparison, conjunction, and fact composition. To improve data efficiency, we propose sampling strategies that focus training on reasoning skills the model is currently lacking. We evaluate our approach on three reading comprehension datasets that are focused on reasoning, and show that our model, PReasM, substantially outperforms T5, a popular pre-trained encoder-decoder model. Moreover, sampling examples based on current model errors leads to faster training and higher overall performance.
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021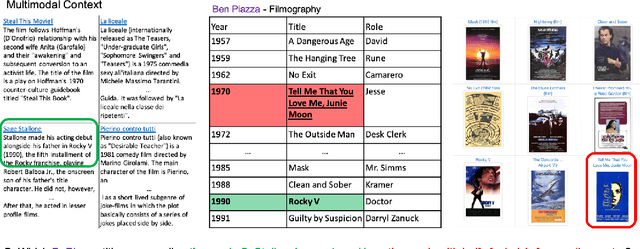
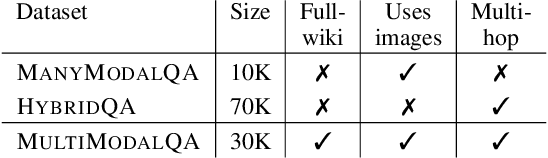

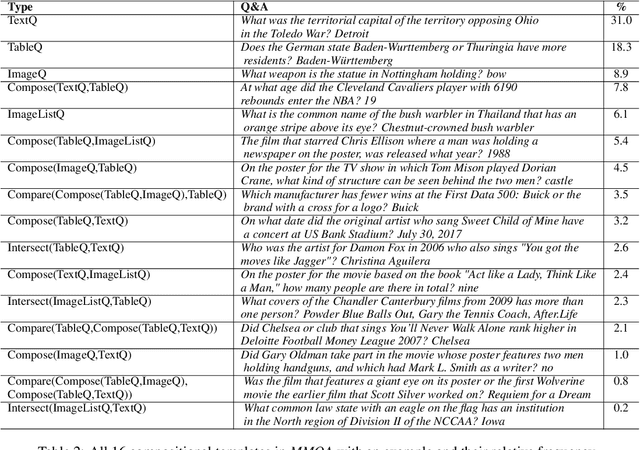
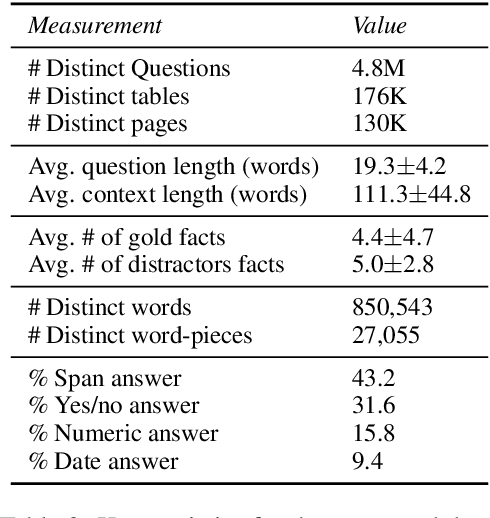
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1
Teaching Pre-Trained Models to Systematically Reason Over Implicit Knowledge
Jun 19, 2020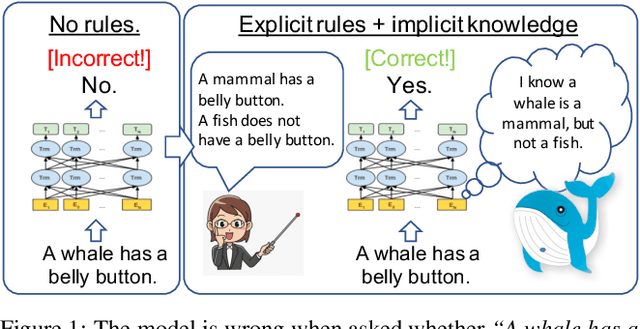
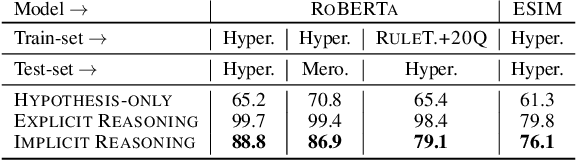
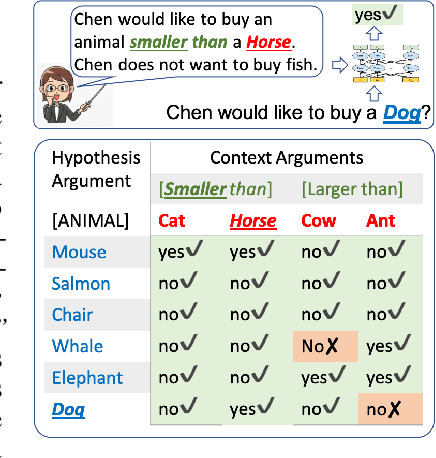
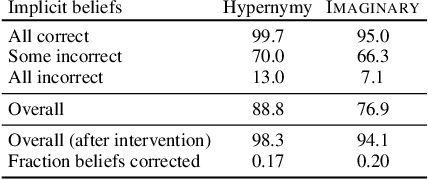
To what extent can a neural network systematically reason over symbolic facts? Evidence suggests that large pre-trained language models (LMs) acquire some reasoning capacity, but this ability is difficult to control. Recently, it has been shown that Transformer-based models succeed in consistent reasoning over explicit symbolic facts, under a "closed-world" assumption. However, in an open-domain setup, it is desirable to tap into the vast reservoir of implicit knowledge already encoded in the parameters of pre-trained LMs. In this work, we provide a first demonstration that LMs can be trained to reliably perform systematic reasoning combining both implicit, pre-trained knowledge and explicit natural language statements. To do this, we describe a procedure for automatically generating datasets that teach a model new reasoning skills, and demonstrate that models learn to effectively perform inference which involves implicit taxonomic and world knowledge, chaining and counting. Finally, we show that "teaching" models to reason generalizes beyond the training distribution: they successfully compose the usage of multiple reasoning skills in single examples. Our work paves a path towards open-domain systems that constantly improve by interacting with users who can instantly correct a model by adding simple natural language statements.
oLMpics -- On what Language Model Pre-training Captures
Dec 31, 2019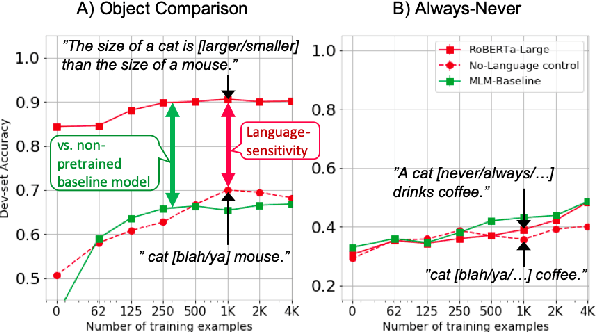

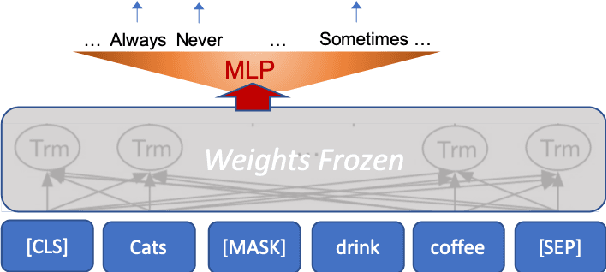
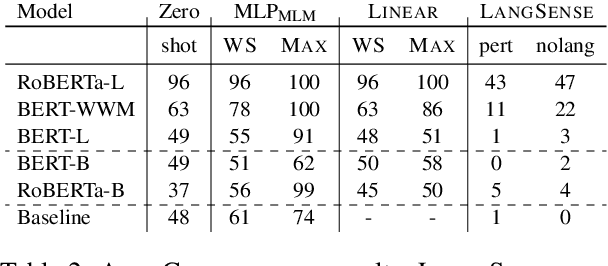
Recent success of pre-trained language models (LMs) has spurred widespread interest in the language capabilities that they possess. However, efforts to understand whether LM representations are useful for symbolic reasoning tasks have been limited and scattered. In this work, we propose eight reasoning tasks, which conceptually require operations such as comparison, conjunction, and composition. A fundamental challenge is to understand whether the performance of a LM on a task should be attributed to the pre-trained representations or to the process of fine-tuning on the task data. To address this, we propose an evaluation protocol that includes both zero-shot evaluation (no fine-tuning), as well as comparing the learning curve of a fine-tuned LM to the learning curve of multiple controls, which paints a rich picture of the LM capabilities. Our main findings are that: (a) different LMs exhibit qualitatively different reasoning abilities, e.g., RoBERTa succeeds in reasoning tasks where BERT fails completely; (b) LMs do not reason in an abstract manner and are context-dependent, e.g., while RoBERTa can compare ages, it can do so only when the ages are in the typical range of human ages; (c) On half of our reasoning tasks all models fail completely. Our findings and infrastructure can help future work on designing new datasets, models and objective functions for pre-training.
ORB: An Open Reading Benchmark for Comprehensive Evaluation of Machine Reading Comprehension
Dec 29, 2019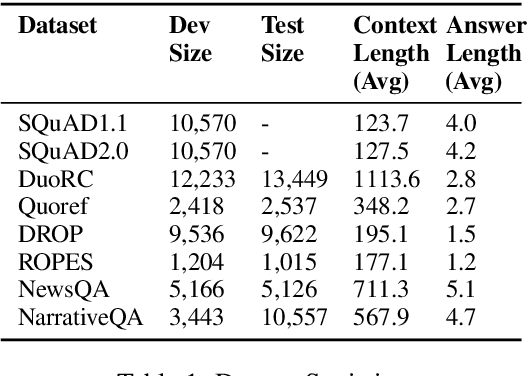
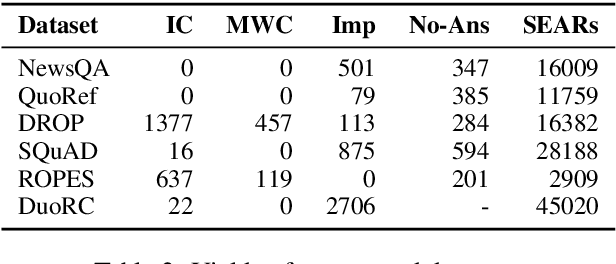
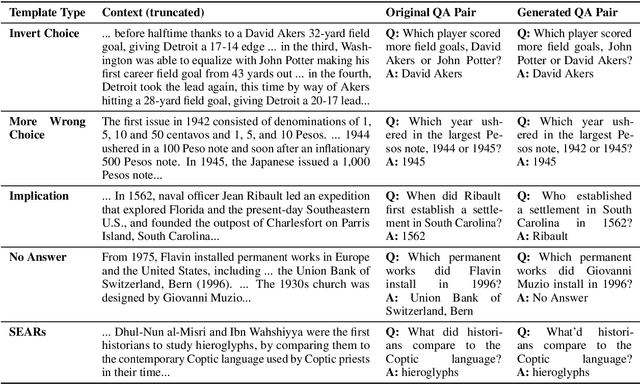
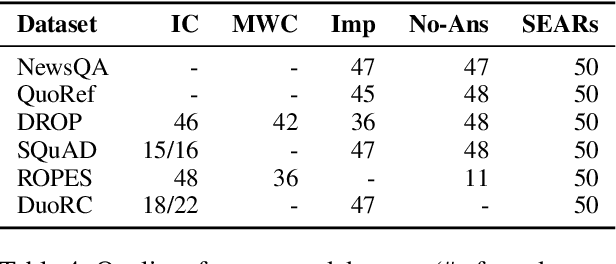
Reading comprehension is one of the crucial tasks for furthering research in natural language understanding. A lot of diverse reading comprehension datasets have recently been introduced to study various phenomena in natural language, ranging from simple paraphrase matching and entity typing to entity tracking and understanding the implications of the context. Given the availability of many such datasets, comprehensive and reliable evaluation is tedious and time-consuming for researchers working on this problem. We present an evaluation server, ORB, that reports performance on seven diverse reading comprehension datasets, encouraging and facilitating testing a single model's capability in understanding a wide variety of reading phenomena. The evaluation server places no restrictions on how models are trained, so it is a suitable test bed for exploring training paradigms and representation learning for general reading facility. As more suitable datasets are released, they will be added to the evaluation server. We also collect and include synthetic augmentations for these datasets, testing how well models can handle out-of-domain questions.
MRQA 2019 Shared Task: Evaluating Generalization in Reading Comprehension
Oct 22, 2019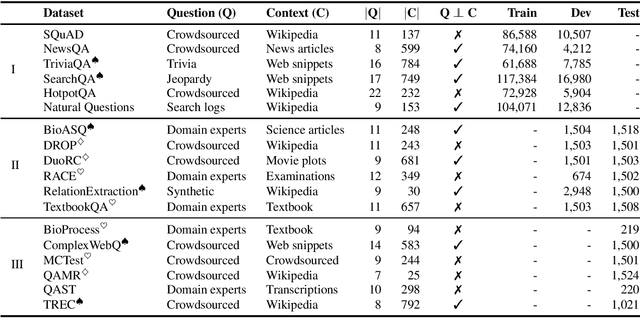
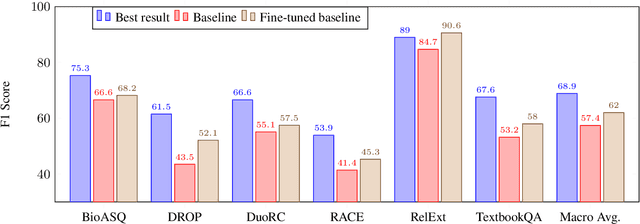
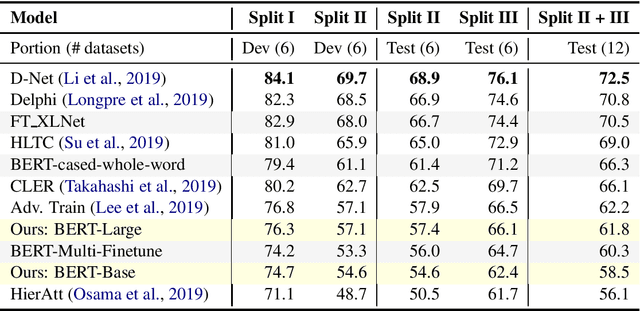
We present the results of the Machine Reading for Question Answering (MRQA) 2019 shared task on evaluating the generalization capabilities of reading comprehension systems. In this task, we adapted and unified 18 distinct question answering datasets into the same format. Among them, six datasets were made available for training, six datasets were made available for development, and the final six were hidden for final evaluation. Ten teams submitted systems, which explored various ideas including data sampling, multi-task learning, adversarial training and ensembling. The best system achieved an average F1 score of 72.5 on the 12 held-out datasets, 10.7 absolute points higher than our initial baseline based on BERT.
Question Answering is a Format; When is it Useful?
Sep 25, 2019Recent years have seen a dramatic expansion of tasks and datasets posed as question answering, from reading comprehension, semantic role labeling, and even machine translation, to image and video understanding. With this expansion, there are many differing views on the utility and definition of "question answering" itself. Some argue that its scope should be narrow, or broad, or that it is overused in datasets today. In this opinion piece, we argue that question answering should be considered a format which is sometimes useful for studying particular phenomena, not a phenomenon or task in itself. We discuss when a task is correctly described as question answering, and when a task is usefully posed as question answering, instead of using some other format.
MultiQA: An Empirical Investigation of Generalization and Transfer in Reading Comprehension
May 31, 2019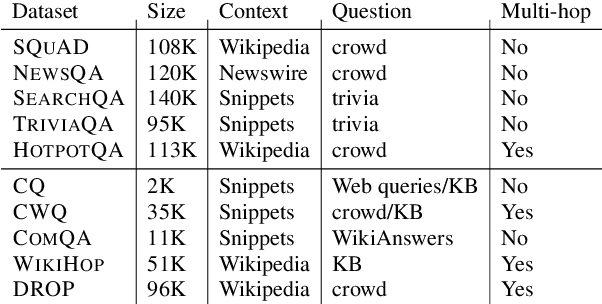
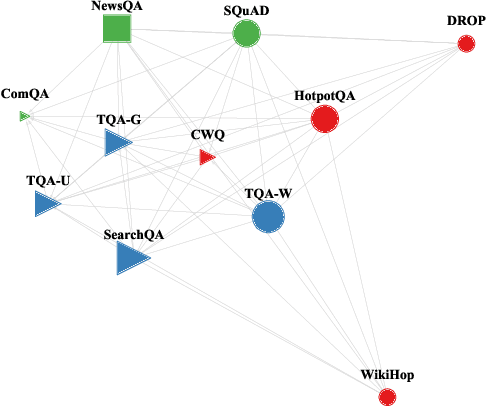
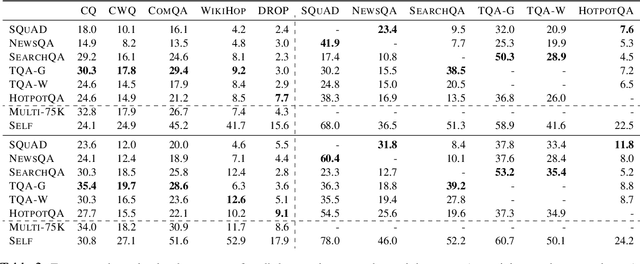
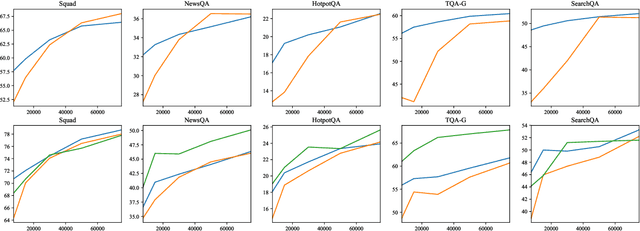
A large number of reading comprehension (RC) datasets has been created recently, but little analysis has been done on whether they generalize to one another, and the extent to which existing datasets can be leveraged for improving performance on new ones. In this paper, we conduct such an investigation over ten RC datasets, training on one or more source RC datasets, and evaluating generalization, as well as transfer to a target RC dataset. We analyze the factors that contribute to generalization, and show that training on a source RC dataset and transferring to a target dataset substantially improves performance, even in the presence of powerful contextual representations from BERT (Devlin et al., 2019). We also find that training on multiple source RC datasets leads to robust generalization and transfer, and can reduce the cost of example collection for a new RC dataset. Following our analysis, we propose MultiQA, a BERT-based model, trained on multiple RC datasets, which leads to state-of-the-art performance on five RC datasets. We share our infrastructure for the benefit of the research community.
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Nov 02, 2018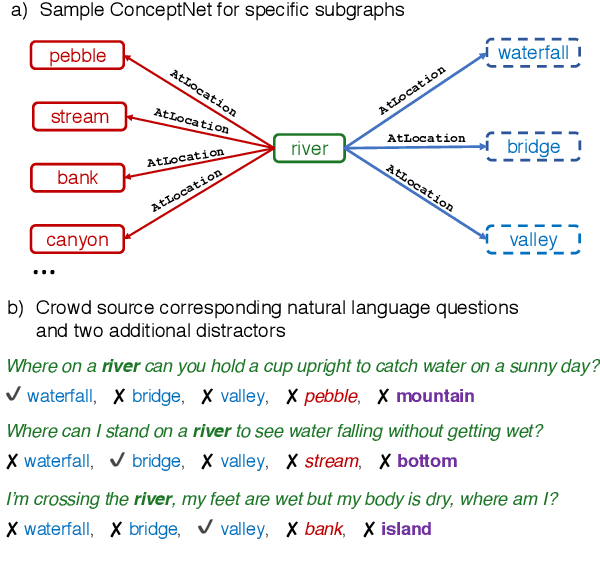

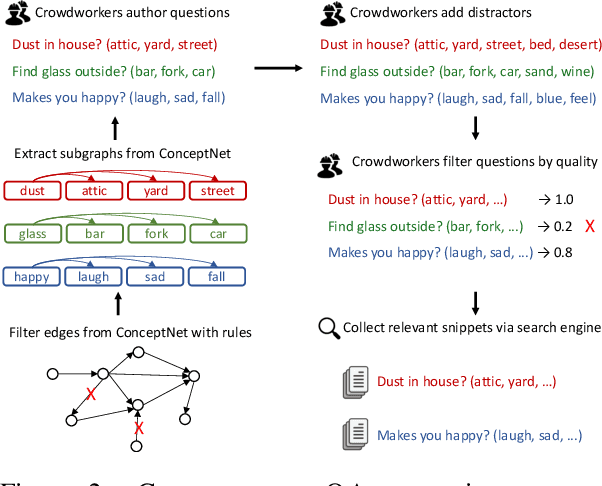

When answering a question, people often draw upon their rich world knowledge in addition to some task-specific context. Recent work has focused primarily on answering questions based on some relevant document or content, and required very little general background. To investigate question answering with prior knowledge, we present CommonsenseQA: a difficult new dataset for commonsense question answering. To capture common sense beyond associations, each question discriminates between three target concepts that all share the same relationship to a single source drawn from ConceptNet (Speer et al., 2017). This constraint encourages crowd workers to author multiple-choice questions with complex semantics, in which all candidates relate to the subject in a similar way. We create 9,500 questions through this procedure and demonstrate the dataset's difficulty with a large number of strong baselines. Our best baseline, the OpenAI GPT (Radford et al., 2018), obtains 54.8% accuracy, well below human performance, which is 95.3%.