 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiModalQA: Complex Question Answering over Text, Tables and Images
Paper and Code
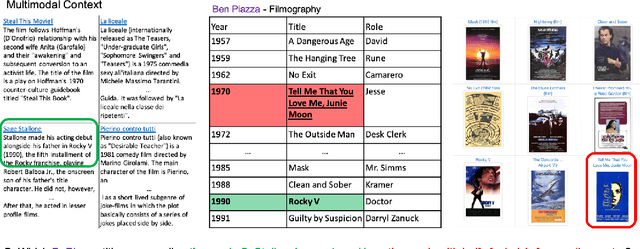
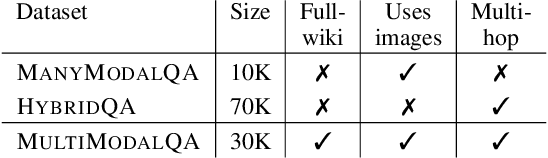

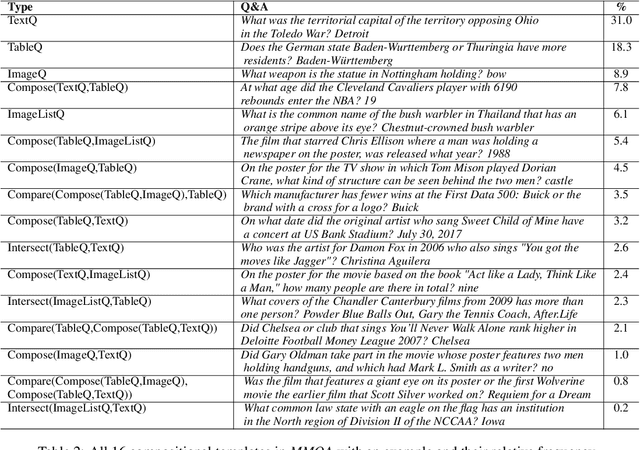
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1