 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Agent Evaluation
Feb 26, 2026The promise of general-purpose agents - systems that perform tasks in unfamiliar environments without domain-specific engineering - remains largely unrealized. Existing agents are predominantly specialized, and while emerging implementations like OpenAI SDK Agent and Claude Code hint at broader capabilities, no systematic evaluation of their general performance has been pursued. Current agentic benchmarks assume domain-specific integration, encoding task information in ways that preclude fair evaluation of general agents. This paper frames general-agent evaluation as a first-class research objective. We propose conceptual principles for such evaluation, a Unified Protocol enabling agent-benchmark integration, and Exgentic - a practical framework for general agent evaluation. We benchmark five prominent agent implementations across six environments as the first Open General Agent Leaderboard. Our experiments show that general agents generalize across diverse environments, achieving performance comparable to domain-specific agents without any environment-specific tuning. We release our evaluation protocol, framework, and leaderboard to establish a foundation for systematic research on general-purpose agents.
Fine-Grained Detection of Context-Grounded Hallucinations Using LLMs
Sep 26, 2025Context-grounded hallucinations are cases where model outputs contain information not verifiable against the source text. We study the applicability of LLMs for localizing such hallucinations, as a more practical alternative to existing complex evaluation pipelines. In the absence of established benchmarks for meta-evaluation of hallucinations localization, we construct one tailored to LLMs, involving a challenging human annotation of over 1,000 examples. We complement the benchmark with an LLM-based evaluation protocol, verifying its quality in a human evaluation. Since existing representations of hallucinations limit the types of errors that can be expressed, we propose a new representation based on free-form textual descriptions, capturing the full range of possible errors. We conduct a comprehensive study, evaluating four large-scale LLMs, which highlights the benchmark's difficulty, as the best model achieves an F1 score of only 0.67. Through careful analysis, we offer insights into optimal prompting strategies for the task and identify the main factors that make it challenging for LLMs: (1) a tendency to incorrectly flag missing details as inconsistent, despite being instructed to check only facts in the output; and (2) difficulty with outputs containing factually correct information absent from the source - and thus not verifiable - due to alignment with the model's parametric knowledge.
Multi-Domain Explainability of Preferences
May 26, 2025
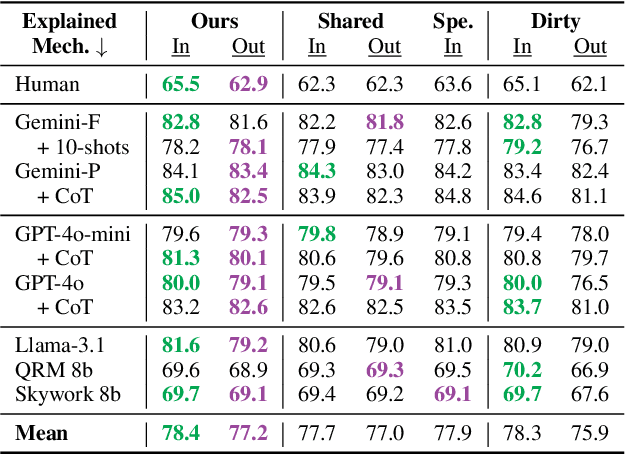
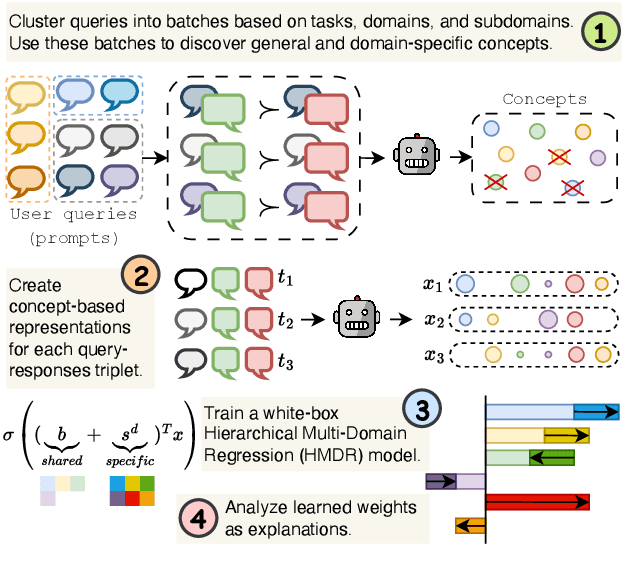
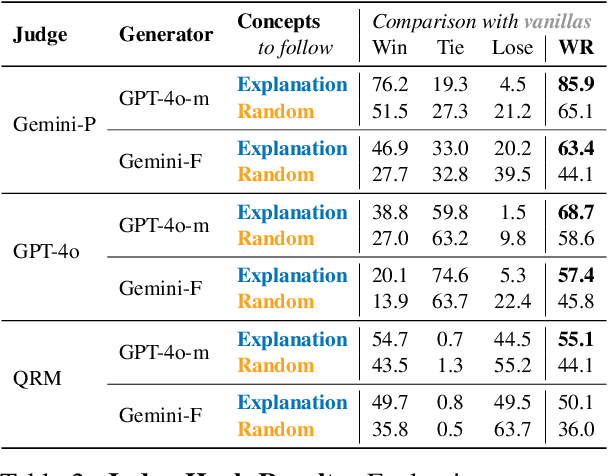
Preference mechanisms, such as human preference, LLM-as-a-Judge (LaaJ), and reward models, are central to aligning and evaluating large language models (LLMs). Yet, the underlying concepts that drive these preferences remain poorly understood. In this work, we propose a fully automated end-to-end method for generating local and global concept-based explanations of preferences across multiple domains. Our method employs an LLM to discover concepts that differentiate between chosen and rejected responses and represent them with concept-based vectors. To model the relationships between concepts and preferences, we propose a white-box Hierarchical Multi-Domain Regression model that captures both domain-general and domain-specific effects. To evaluate our method, we curate a dataset spanning eight challenging and diverse domains and explain twelve mechanisms. Our method achieves strong preference prediction performance, outperforming baselines while also being explainable. Additionally, we assess explanations in two novel application-driven settings. First, guiding LLM outputs with concepts from LaaJ explanations yields responses that those judges consistently prefer. Second, prompting LaaJs with concepts explaining humans improves their preference predictions. Together, our work provides a new paradigm for explainability in the era of LLMs.
WildIFEval: Instruction Following in the Wild
Mar 09, 2025



Recent LLMs have shown remarkable success in following user instructions, yet handling instructions with multiple constraints remains a significant challenge. In this work, we introduce WildIFEval - a large-scale dataset of 12K real user instructions with diverse, multi-constraint conditions. Unlike prior datasets, our collection spans a broad lexical and topical spectrum of constraints, in natural user prompts. We categorize these constraints into eight high-level classes to capture their distribution and dynamics in real-world scenarios. Leveraging WildIFEval, we conduct extensive experiments to benchmark the instruction-following capabilities of leading LLMs. Our findings reveal that all evaluated models experience performance degradation with an increasing number of constraints. Thus, we show that all models have a large room for improvement on such tasks. Moreover, we observe that the specific type of constraint plays a critical role in model performance. We release our dataset to promote further research on instruction-following under complex, realistic conditions.
Conversational Prompt Engineering
Aug 08, 2024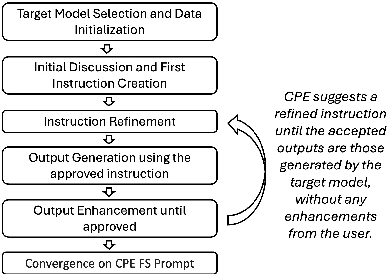

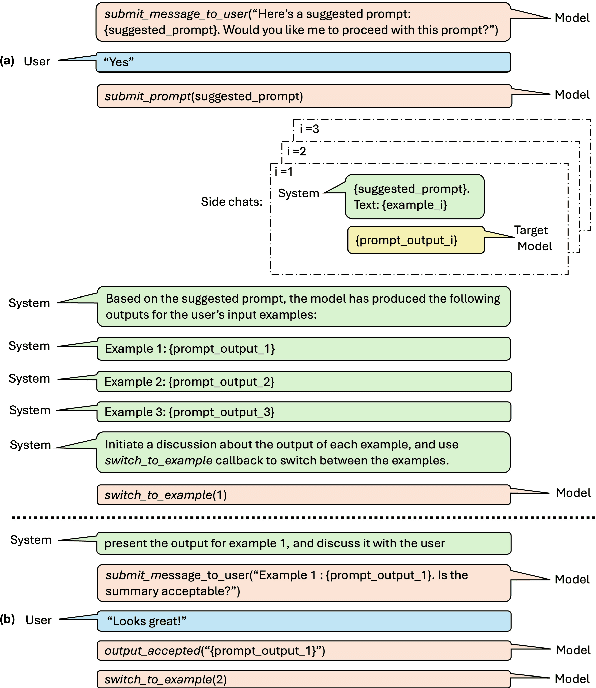
Prompts are how humans communicate with LLMs. Informative prompts are essential for guiding LLMs to produce the desired output. However, prompt engineering is often tedious and time-consuming, requiring significant expertise, limiting its widespread use. We propose Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them articulate their output preferences and integrating these into the prompt. The process includes two main stages: first, the model uses user-provided unlabeled data to generate data-driven questions and utilize user responses to shape the initial instruction. Then, the model shares the outputs generated by the instruction and uses user feedback to further refine the instruction and the outputs. The final result is a few-shot prompt, where the outputs approved by the user serve as few-shot examples. A user study on summarization tasks demonstrates the value of CPE in creating personalized, high-performing prompts. The results suggest that the zero-shot prompt obtained is comparable to its - much longer - few-shot counterpart, indicating significant savings in scenarios involving repetitive tasks with large text volumes.
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
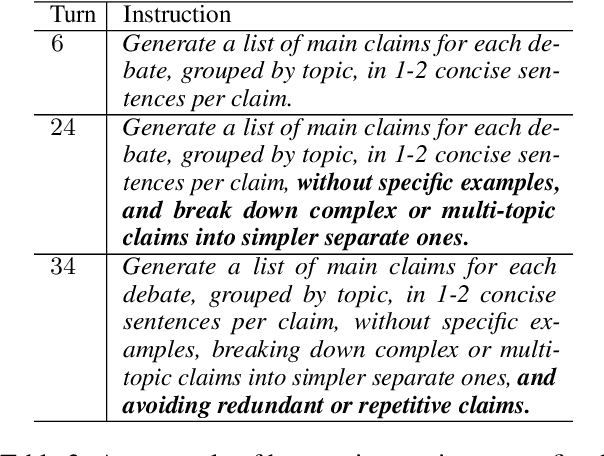
Jul 25, 2024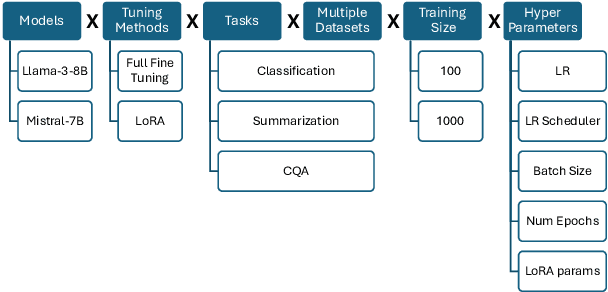


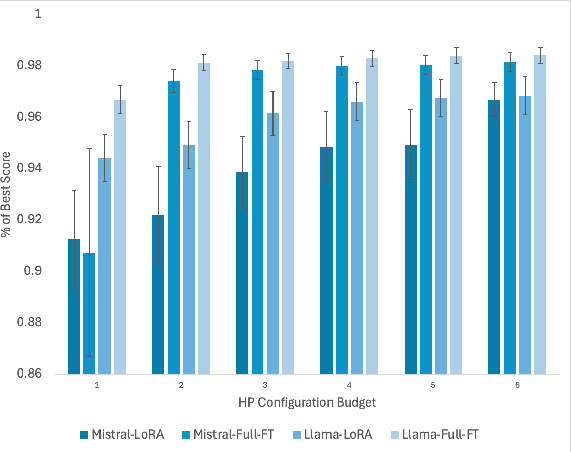
Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Label-Efficient Model Selection for Text Generation
Feb 12, 2024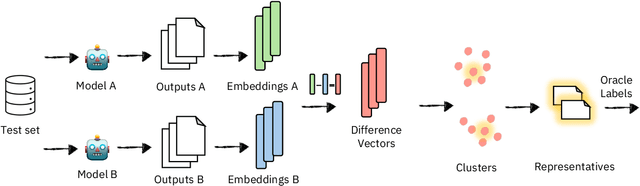

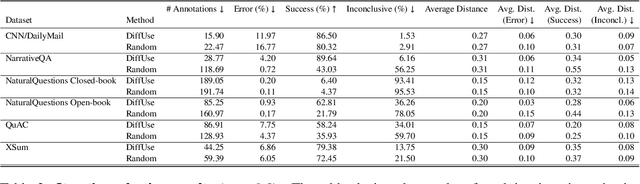
Model selection for a given target task can be costly, as it may entail extensive annotation of the quality of outputs of different models. We introduce DiffUse, an efficient method to make an informed decision between candidate text generation models. DiffUse reduces the required amount of preference annotations, thus saving valuable time and resources in performing evaluation. DiffUse intelligently selects instances by clustering embeddings that represent the semantic differences between model outputs. Thus, it is able to identify a subset of examples that are more informative for preference decisions. Our method is model-agnostic, and can be applied to any text generation model. Moreover, we propose a practical iterative approach for dynamically determining how many instances to annotate. In a series of experiments over hundreds of model pairs, we demonstrate that DiffUse can dramatically reduce the required number of annotations -- by up to 75% -- while maintaining high evaluation reliability.
Efficient Benchmarking (of Language Models)
Aug 31, 2023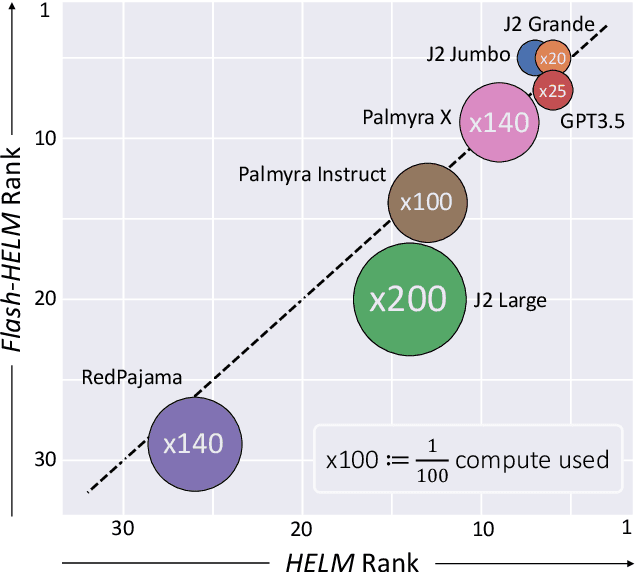
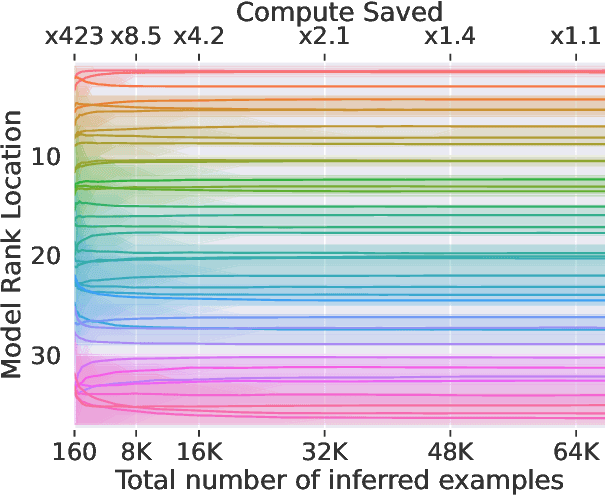
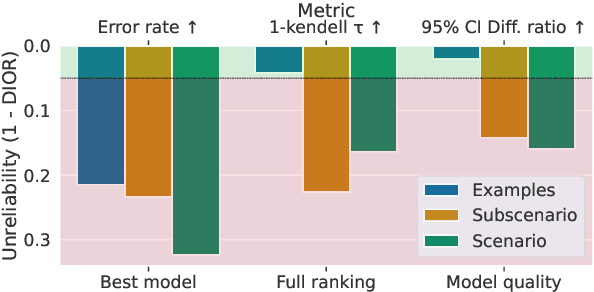
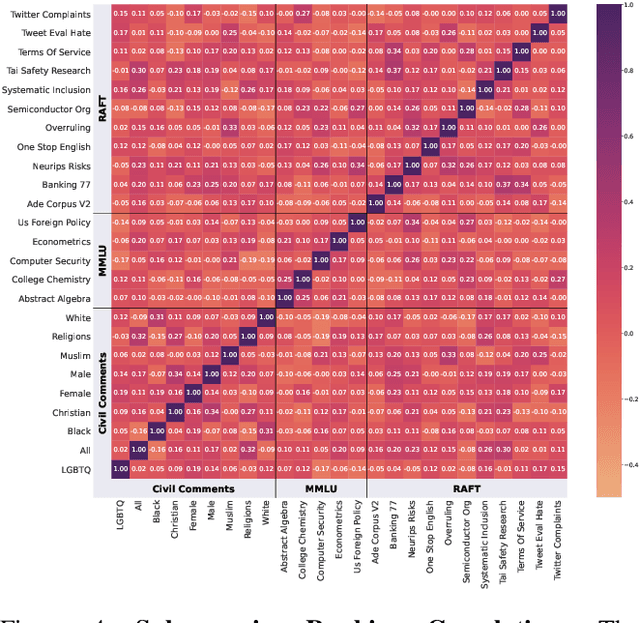
The increasing versatility of language models LMs has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs reaching thousands of GPU hours per model. However the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work we present the problem of Efficient Benchmarking namely intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case we investigate how different benchmark design choices affect the computation-reliability tradeoff. We propose to evaluate the reliability of such decisions by using a new measure Decision Impact on Reliability DIoR for short. We find for example that the current leader on HELM may change by merely removing a low-ranked model from the benchmark and observe that a handful of examples suffice to obtain the correct benchmark ranking. Conversely a slightly different choice of HELM scenarios varies ranking widely. Based on our findings we outline a set of concrete recommendations for more efficient benchmark design and utilization practices leading to dramatic cost savings with minimal loss of benchmark reliability often reducing computation by x100 or more.
Active Learning for Natural Language Generation
May 24, 2023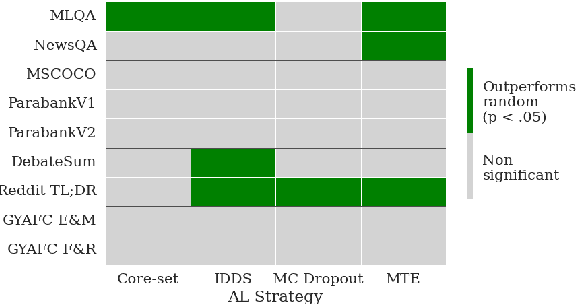

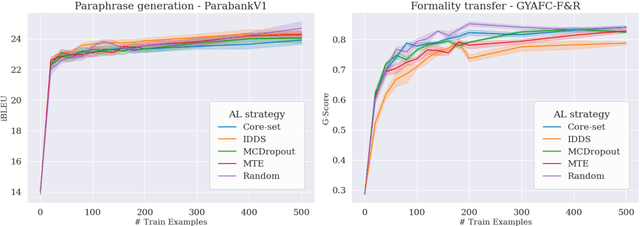

The field of text generation suffers from a severe shortage of labeled data due to the extremely expensive and time consuming process involved in manual annotation. A natural approach for coping with this problem is active learning (AL), a well-known machine learning technique for improving annotation efficiency by selectively choosing the most informative examples to label. However, while AL has been well-researched in the context of text classification, its application to text generation remained largely unexplored. In this paper, we present a first systematic study of active learning for text generation, considering a diverse set of tasks and multiple leading AL strategies. Our results indicate that existing AL strategies, despite their success in classification, are largely ineffective for the text generation scenario, and fail to consistently surpass the baseline of random example selection. We highlight some notable differences between the classification and generation scenarios, and analyze the selection behaviors of existing AL strategies. Our findings motivate exploring novel approaches for applying AL to NLG tasks.
SimpleStyle: An Adaptable Style Transfer Approach
Dec 22, 2022Attribute-controlled text rewriting, also known as text style-transfer, has a crucial role in regulating attributes and biases of textual training data and a machine generated text. In this work we present SimpleStyle, a minimalist yet effective approach for style-transfer composed of two simple ingredients: controlled denoising and output filtering. Despite the simplicity of our approach, which can be succinctly described with a few lines of code, it is competitive with previous state-of-the-art methods both in automatic and in human evaluation. To demonstrate the adaptability and practical value of our system beyond academic data, we apply SimpleStyle to transfer a wide range of text attributes appearing in real-world textual data from social networks. Additionally, we introduce a novel "soft noising" technique that further improves the performance of our system. We also show that teaching a student model to generate the output of SimpleStyle can result in a system that performs style transfer of equivalent quality with only a single greedy-decoded sample. Finally, we suggest our method as a remedy for the fundamental incompatible baseline issue that holds progress in the field. We offer our protocol as a simple yet strong baseline for works that wish to make incremental advancements in the field of attribute controlled text rewriting.