 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Paper and Code
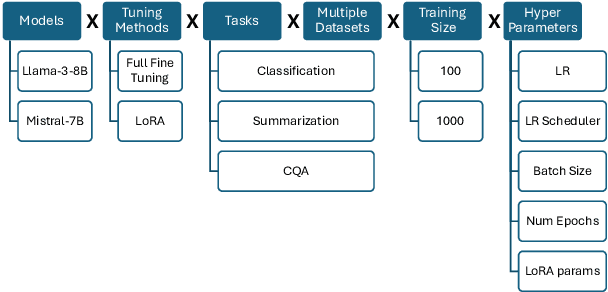


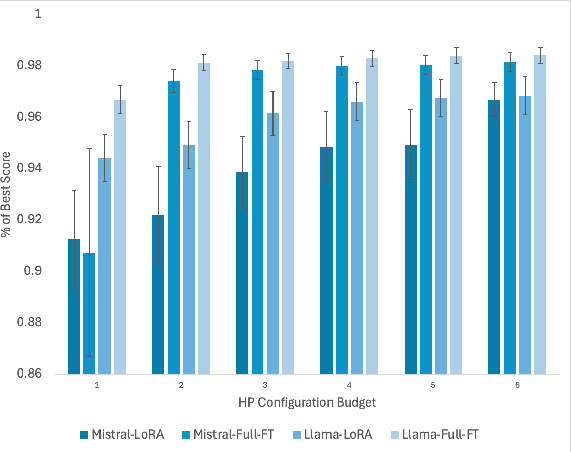
Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.