 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Model Selection for Text Generation
Paper and Code
Feb 12, 2024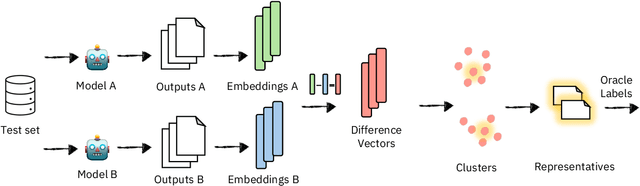

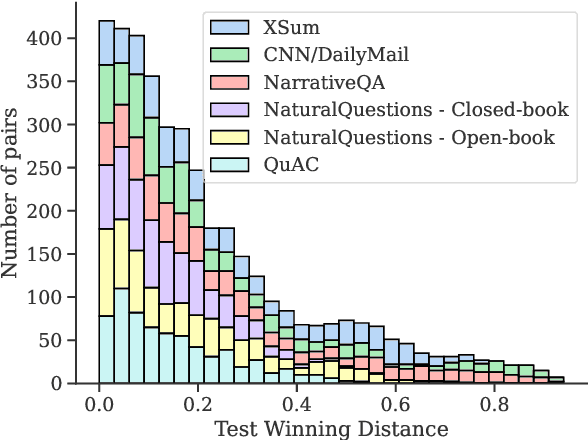
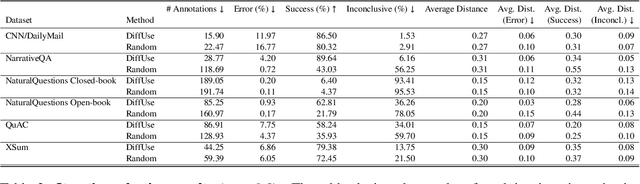
Model selection for a given target task can be costly, as it may entail extensive annotation of the quality of outputs of different models. We introduce DiffUse, an efficient method to make an informed decision between candidate text generation models. DiffUse reduces the required amount of preference annotations, thus saving valuable time and resources in performing evaluation. DiffUse intelligently selects instances by clustering embeddings that represent the semantic differences between model outputs. Thus, it is able to identify a subset of examples that are more informative for preference decisions. Our method is model-agnostic, and can be applied to any text generation model. Moreover, we propose a practical iterative approach for dynamically determining how many instances to annotate. In a series of experiments over hundreds of model pairs, we demonstrate that DiffUse can dramatically reduce the required number of annotations -- by up to 75% -- while maintaining high evaluation reliability.