 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024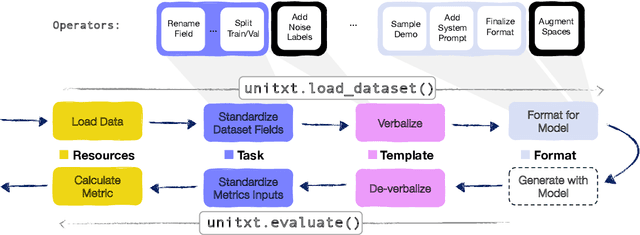

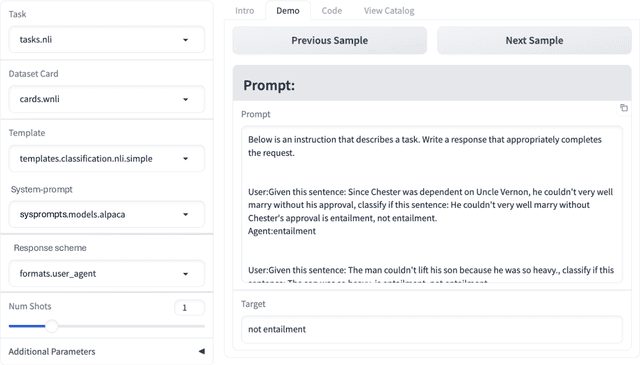

In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Active Learning for Natural Language Generation
May 24, 2023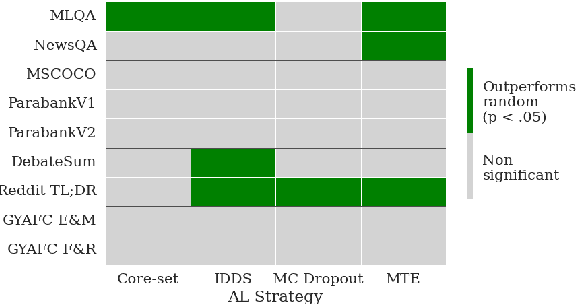

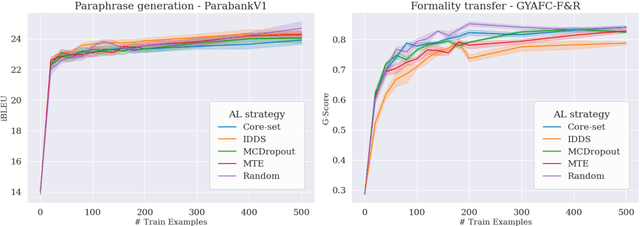

The field of text generation suffers from a severe shortage of labeled data due to the extremely expensive and time consuming process involved in manual annotation. A natural approach for coping with this problem is active learning (AL), a well-known machine learning technique for improving annotation efficiency by selectively choosing the most informative examples to label. However, while AL has been well-researched in the context of text classification, its application to text generation remained largely unexplored. In this paper, we present a first systematic study of active learning for text generation, considering a diverse set of tasks and multiple leading AL strategies. Our results indicate that existing AL strategies, despite their success in classification, are largely ineffective for the text generation scenario, and fail to consistently surpass the baseline of random example selection. We highlight some notable differences between the classification and generation scenarios, and analyze the selection behaviors of existing AL strategies. Our findings motivate exploring novel approaches for applying AL to NLG tasks.
nBIIG: A Neural BI Insights Generation System for Table Reporting
Nov 08, 2022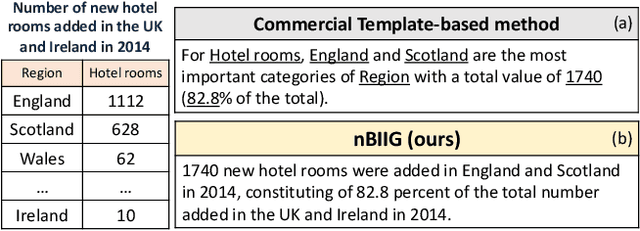
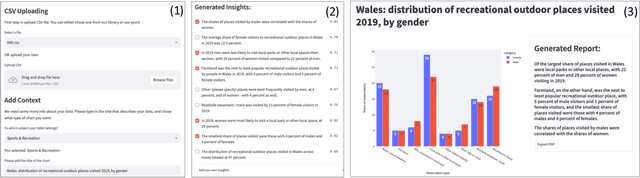
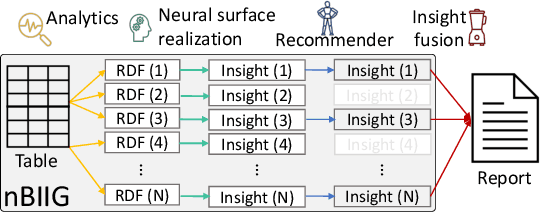
We present nBIIG, a neural Business Intelligence (BI) Insights Generation system. Given a table, our system applies various analyses to create corresponding RDF representations, and then uses a neural model to generate fluent textual insights out of these representations. The generated insights can be used by an analyst, via a human-in-the-loop paradigm, to enhance the task of creating compelling table reports. The underlying generative neural model is trained over large and carefully distilled data, curated from multiple BI domains. Thus, the system can generate faithful and fluent insights over open-domain tables, making it practical and useful.
Diversity Enhanced Table-to-Text Generation via Type Control
May 22, 2022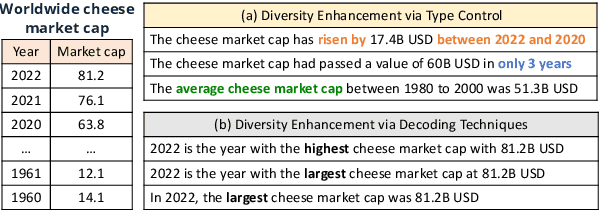

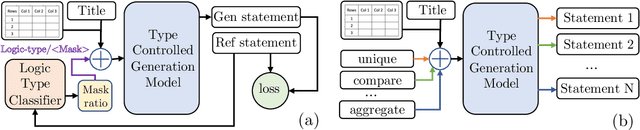

Generating natural language statements to convey information from tabular data (i.e., Table-to-text) is a process with one input and a variety of valid outputs. This characteristic underscores the abilities to control the generation and produce a diverse set of outputs as two key assets. Thus, we propose a diversity enhancing scheme that builds upon an inherent property of the statements, namely, their logic-types, by using a type-controlled Table-to-text generation model. Employing automatic and manual tests, we prove its twofold advantage: users can effectively tune the generated statement type, and, by sampling different types, can obtain a diverse set of statements for a given table.
Controversy in Context
Aug 20, 2019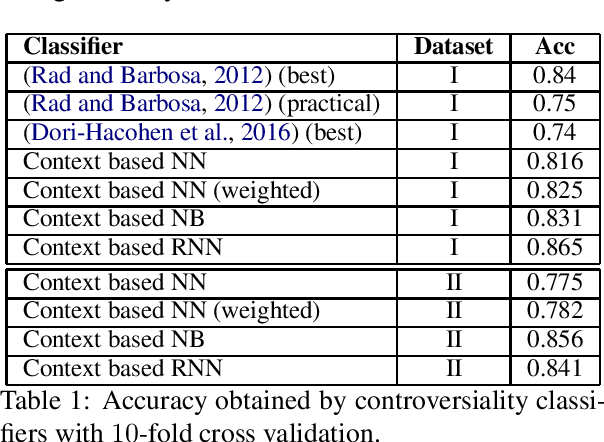
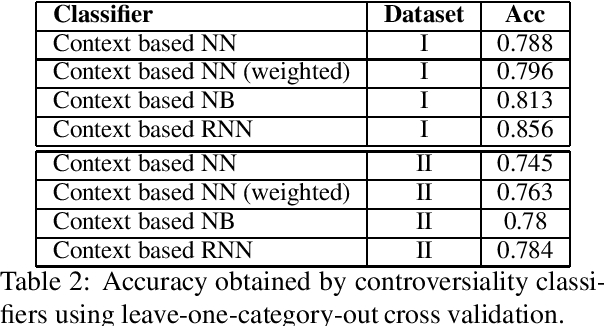
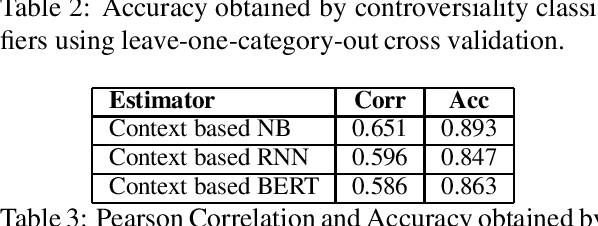
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.
Fast End-to-End Wikification
Aug 19, 2019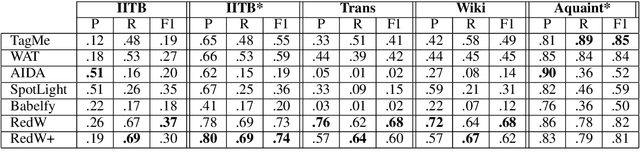
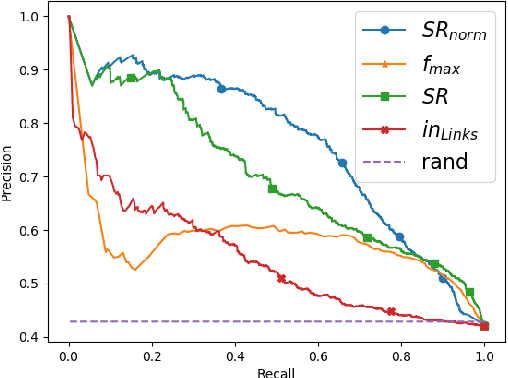
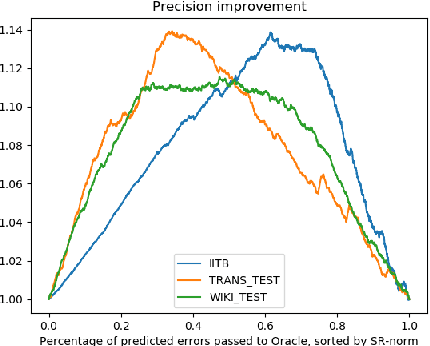

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.