 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting COVID-19 in the Dark: Methodology for Improved Inference Using Homomorphically Encrypted DNN
Nov 17, 2021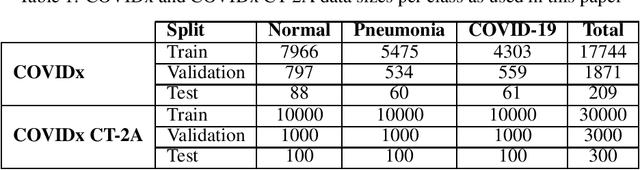

Privacy-preserving deep neural network (DNN) inference is a necessity in different regulated industries such as healthcare, finance, and retail. Recently, homomorphic encryption (HE) has been used as a method to enable analytics while addressing privacy concerns. HE enables secure predictions over encrypted data. However, there are several challenges related to the use of HE, including DNN size limitations and the lack of support for some operation types. Most notably, the commonly used ReLU activation is not supported under some HE schemes. We propose a structured methodology to replace ReLU with a quadratic polynomial activation. To address the accuracy degradation issue, we use a pre-trained model that trains another HE-friendly model, using techniques such as "trainable activation" functions and knowledge distillation. We demonstrate our methodology on the AlexNet architecture, using the chest X-Ray and CT datasets for COVID-19 detection. Our experiments show that by using our approach, the gap between the F1 score and accuracy of the models trained with ReLU and the HE-friendly model is narrowed down to within a mere 1.1 - 5.3 percent degradation.
Unsupervised Expressive Rules Provide Explainability and Assist Human Experts Grasping New Domains
Oct 19, 2020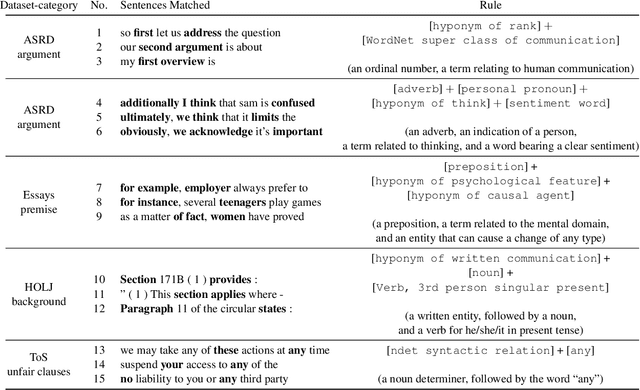
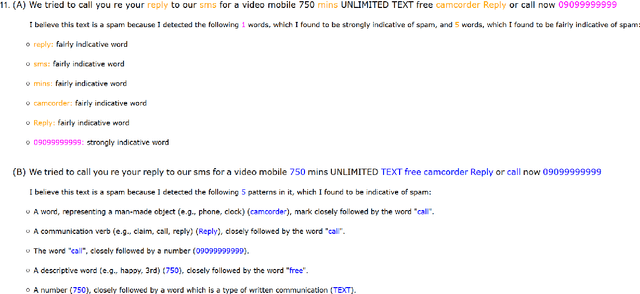
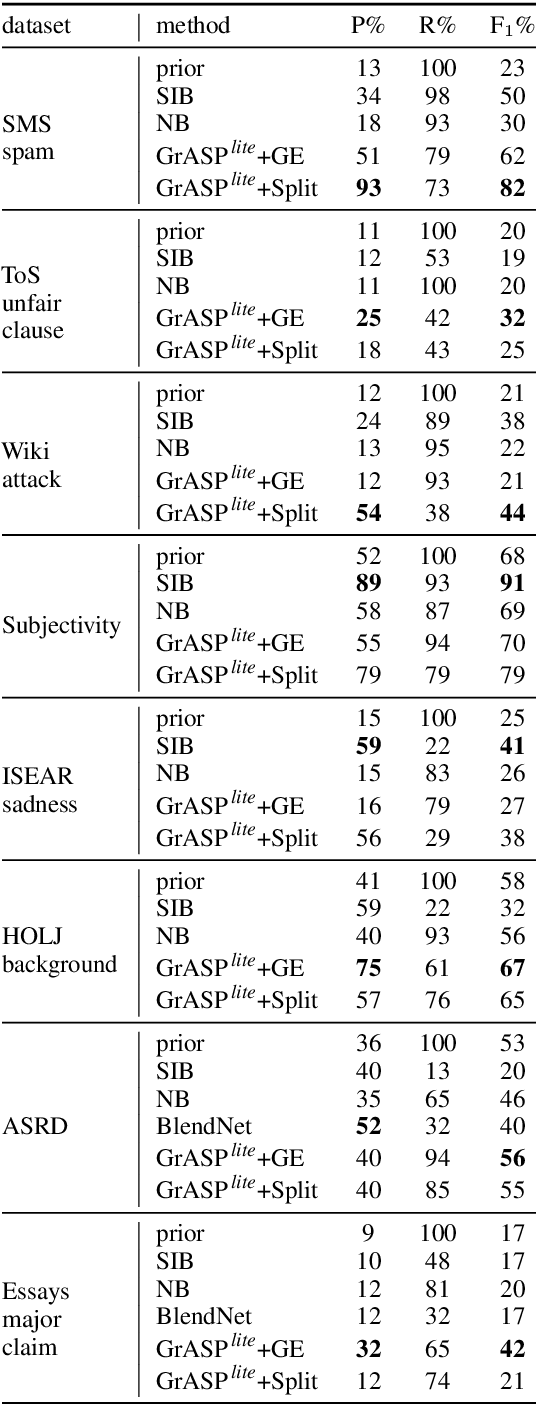
Approaching new data can be quite deterrent; you do not know how your categories of interest are realized in it, commonly, there is no labeled data at hand, and the performance of domain adaptation methods is unsatisfactory. Aiming to assist domain experts in their first steps into a new task over a new corpus, we present an unsupervised approach to reveal complex rules which cluster the unexplored corpus by its prominent categories (or facets). These rules are human-readable, thus providing an important ingredient which has become in short supply lately - explainability. Each rule provides an explanation for the commonality of all the texts it clusters together. We present an extensive evaluation of the usefulness of these rules in identifying target categories, as well as a user study which assesses their interpretability.
Argument Invention from First Principles
Aug 22, 2019


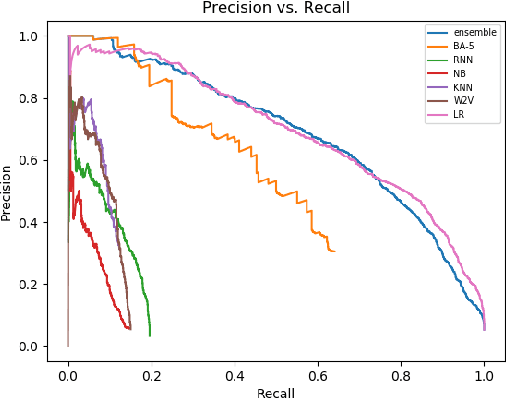
Competitive debaters often find themselves facing a challenging task -- how to debate a topic they know very little about, with only minutes to prepare, and without access to books or the Internet? What they often do is rely on "first principles", commonplace arguments which are relevant to many topics, and which they have refined in past debates. In this work we aim to explicitly define a taxonomy of such principled recurring arguments, and, given a controversial topic, to automatically identify which of these arguments are relevant to the topic. As far as we know, this is the first time that this approach to argument invention is formalized and made explicit in the context of NLP. The main goal of this work is to show that it is possible to define such a taxonomy. While the taxonomy suggested here should be thought of as a "first attempt" it is nonetheless coherent, covers well the relevant topics and coincides with what professional debaters actually argue in their speeches, and facilitates automatic argument invention for new topics.
Are You Convinced? Choosing the More Convincing Evidence with a Siamese Network
Jul 23, 2019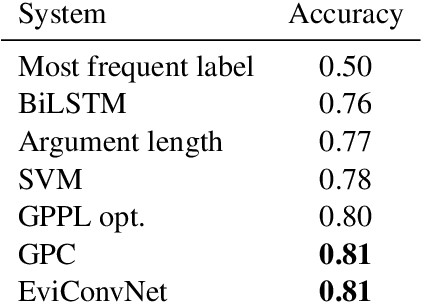

With the advancement in argument detection, we suggest to pay more attention to the challenging task of identifying the more convincing arguments. Machines capable of responding and interacting with humans in helpful ways have become ubiquitous. We now expect them to discuss with us the more delicate questions in our world, and they should do so armed with effective arguments. But what makes an argument more persuasive? What will convince you? In this paper, we present a new data set, IBM-EviConv, of pairs of evidence labeled for convincingness, designed to be more challenging than existing alternatives. We also propose a Siamese neural network architecture shown to outperform several baselines on both a prior convincingness data set and our own. Finally, we provide insights into our experimental results and the various kinds of argumentative value our method is capable of detecting.