 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Expressive Rules Provide Explainability and Assist Human Experts Grasping New Domains
Paper and Code
Oct 19, 2020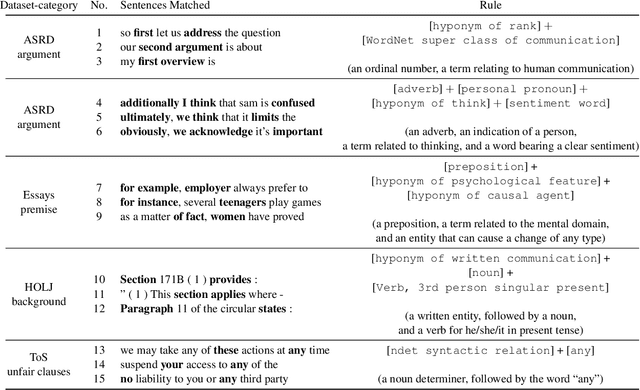
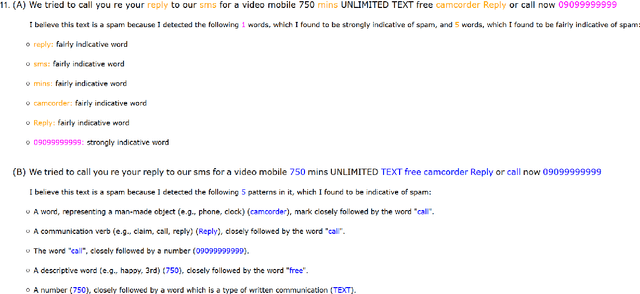
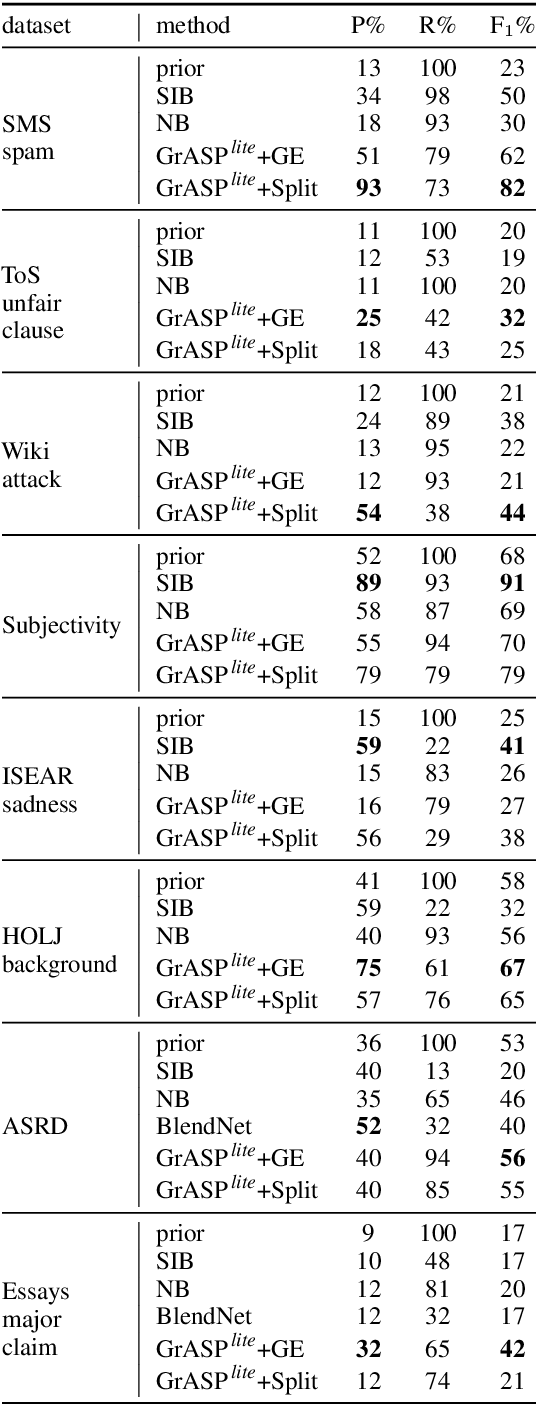
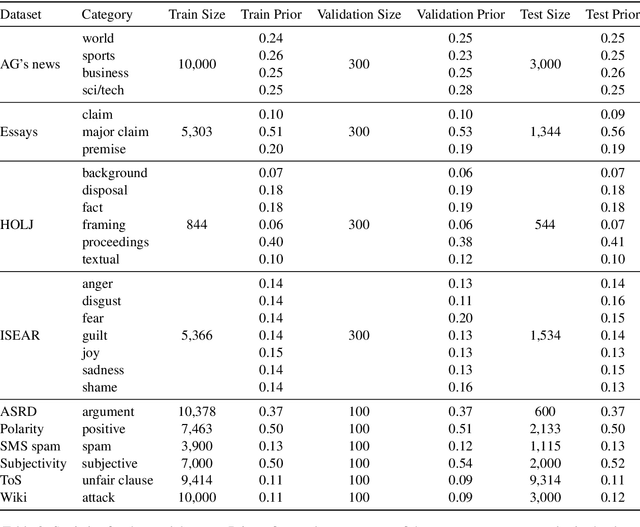
Approaching new data can be quite deterrent; you do not know how your categories of interest are realized in it, commonly, there is no labeled data at hand, and the performance of domain adaptation methods is unsatisfactory. Aiming to assist domain experts in their first steps into a new task over a new corpus, we present an unsupervised approach to reveal complex rules which cluster the unexplored corpus by its prominent categories (or facets). These rules are human-readable, thus providing an important ingredient which has become in short supply lately - explainability. Each rule provides an explanation for the commonality of all the texts it clusters together. We present an extensive evaluation of the usefulness of these rules in identifying target categories, as well as a user study which assesses their interpretability.