 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-local sustainable assortment planning
Jul 27, 2020


Assortment planning, an important seasonal activity for any retailer, involves choosing the right subset of products to stock in each store.While existing approaches only maximize the expected revenue, we propose including the environmental impact too, through the Higg Material Sustainability Index. The trade-off between revenue and environmental impact is balanced through a multi-objective optimization approach, that yields a Pareto-front of optimal assortments for merchandisers to choose from. Using the proposed approach on a few product categories of a leading fashion retailer shows that choosing assortments with lower environmental impact with a minimal impact on revenue is possible.
Multi-modal dialog for browsing large visual catalogs using exploration-exploitation paradigm in a joint embedding space
Jan 29, 2019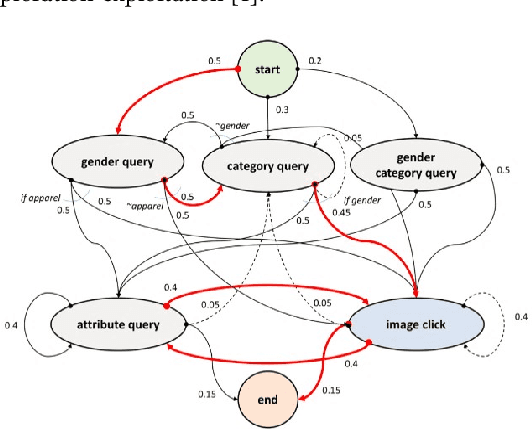
We present a multi-modal dialog system to assist online shoppers in visually browsing through large catalogs. Visual browsing is different from visual search in that it allows the user to explore the wide range of products in a catalog, beyond the exact search matches. We focus on a slightly asymmetric version of the complete multi-modal dialog where the system can understand both text and image queries but responds only in images. We formulate our problem of "showing $k$ best images to a user" based on the dialog context so far, as sampling from a Gaussian Mixture Model in a high dimensional joint multi-modal embedding space, that embed both the text and the image queries. Our system remembers the context of the dialog and uses an exploration-exploitation paradigm to assist in visual browsing. We train and evaluate the system on a multi-modal dialog dataset that we generate from large catalog data. Our experiments are promising and show that the agent is capable of learning and can display relevant results with an average cosine similarity of 0.85 to the ground truth. Our preliminary human evaluation also corroborates the fact that such a multi-modal dialog system for visual browsing is well-received and is capable of engaging human users.
Styling with Attention to Details
Jul 03, 2018



Fashion as characterized by its nature, is driven by style. In this paper, we propose a method that takes into account the style information to complete a given set of selected fashion items with a complementary fashion item. Complementary items are those items that can be worn along with the selected items according to the style. Addressing this problem facilitates in automatically generating stylish fashion ensembles leading to a richer shopping experience for users. Recently, there has been a surge of online social websites where fashion enthusiasts post the outfit of the day and other users can like and comment on them. These posts contain a gold-mine of information about style. In this paper, we exploit these posts to train a deep neural network which captures style in an automated manner. We pose the problem of predicting complementary fashion items as a sequence to sequence problem where the input is the selected set of fashion items and the output is a complementary fashion item based on the style information learned by the model. We use the encoder decoder architecture to solve this problem of completing the set of fashion items. We evaluate the goodness of the proposed model through a variety of experiments. We empirically observe that our proposed model outperforms competitive baseline like apriori algorithm by ~28 in terms of accuracy for top-1 recommendation to complete the fashion ensemble. We also perform retrieval based experiments to understand the ability of the model to learn style and rank the complementary fashion items and find that using attention in our encoder decoder model helps in improving the mean reciprocal rank by ~24. Qualitatively we find the complementary fashion items generated by our proposed model are richer than the apriori algorithm.
DeepSolarEye: Power Loss Prediction and Weakly Supervised Soiling Localization via Fully Convolutional Networks for Solar Panels
Mar 18, 2018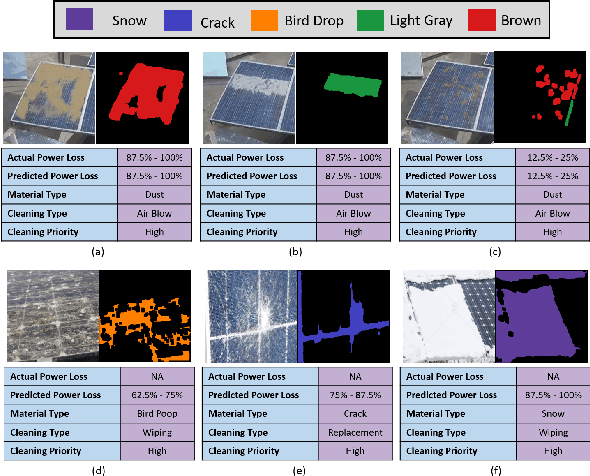
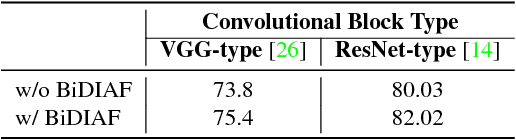
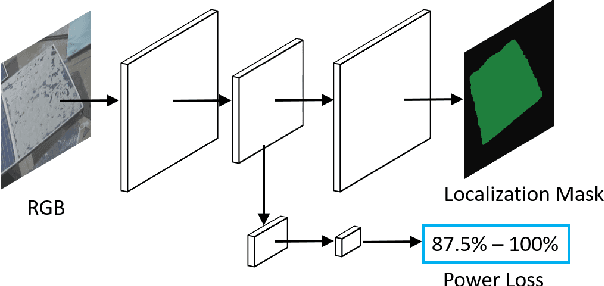
The impact of soiling on solar panels is an important and well-studied problem in renewable energy sector. In this paper, we present the first convolutional neural network (CNN) based approach for solar panel soiling and defect analysis. Our approach takes an RGB image of solar panel and environmental factors as inputs to predict power loss, soiling localization, and soiling type. In computer vision, localization is a complex task which typically requires manually labeled training data such as bounding boxes or segmentation masks. Our proposed approach consists of specialized four stages which completely avoids localization ground truth and only needs panel images with power loss labels for training. The region of impact area obtained from the predicted localization masks are classified into soiling types using the webly supervised learning. For improving localization capabilities of CNNs, we introduce a novel bi-directional input-aware fusion (BiDIAF) block that reinforces the input at different levels of CNN to learn input-specific feature maps. Our empirical study shows that BiDIAF improves the power loss prediction accuracy by about 3% and localization accuracy by about 4%. Our end-to-end model yields further improvement of about 24% on localization when learned in a weakly supervised manner. Our approach is generalizable and showed promising results on web crawled solar panel images. Our system has a frame rate of 22 fps (including all steps) on a NVIDIA TitanX GPU. Additionally, we collected first of it's kind dataset for solar panel image analysis consisting 45,000+ images.
Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks
Jul 18, 2017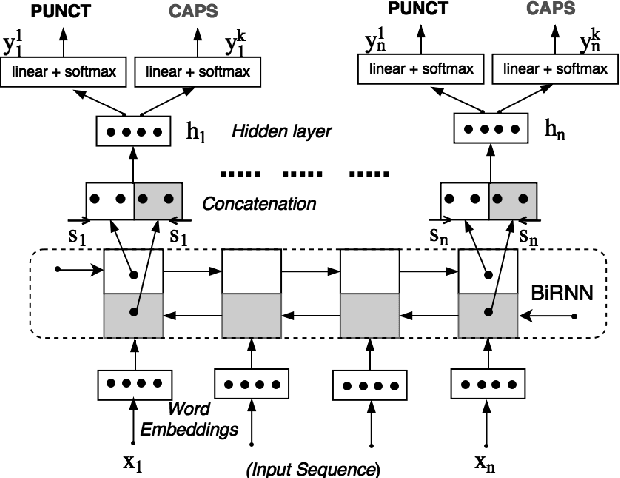
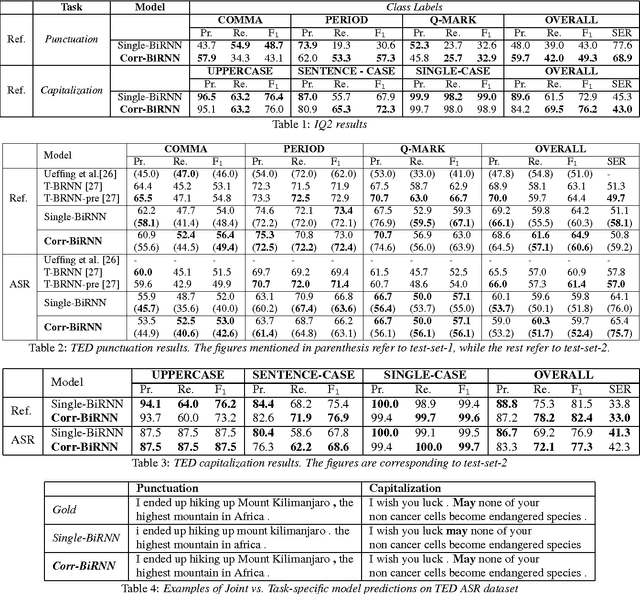
The stream of words produced by Automatic Speech Recognition (ASR) systems is typically devoid of punctuations and formatting. Most natural language processing applications expect segmented and well-formatted texts as input, which is not available in ASR output. This paper proposes a novel technique of jointly modeling multiple correlated tasks such as punctuation and capitalization using bidirectional recurrent neural networks, which leads to improved performance for each of these tasks. This method could be extended for joint modeling of any other correlated sequence labeling tasks.
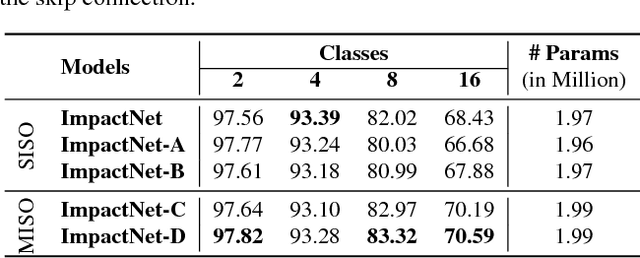
An Empirical Evaluation of various Deep Learning Architectures for Bi-Sequence Classification Tasks
Oct 02, 2016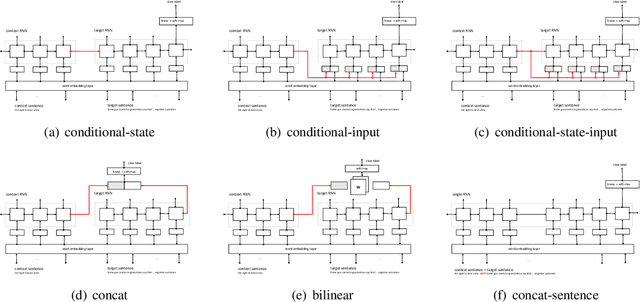
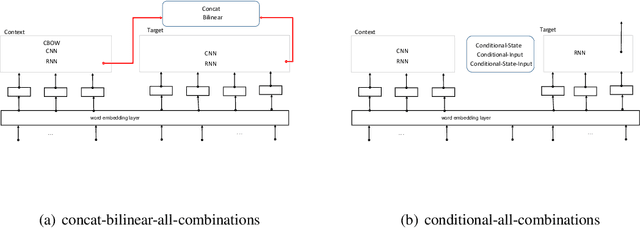

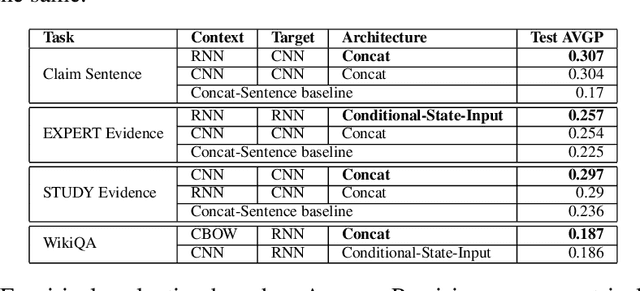
Several tasks in argumentation mining and debating, question-answering, and natural language inference involve classifying a sequence in the context of another sequence (referred as bi-sequence classification). For several single sequence classification tasks, the current state-of-the-art approaches are based on recurrent and convolutional neural networks. On the other hand, for bi-sequence classification problems, there is not much understanding as to the best deep learning architecture. In this paper, we attempt to get an understanding of this category of problems by extensive empirical evaluation of 19 different deep learning architectures (specifically on different ways of handling context) for various problems originating in natural language processing like debating, textual entailment and question-answering. Following the empirical evaluation, we offer our insights and conclusions regarding the architectures we have considered. We also establish the first deep learning baselines for three argumentation mining tasks.
An Autoencoder Approach to Learning Bilingual Word Representations
Feb 06, 2014
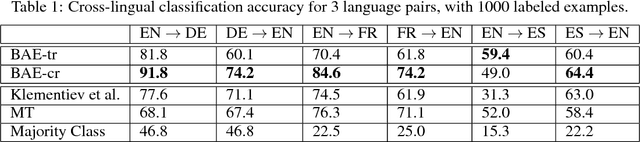


Cross-language learning allows us to use training data from one language to build models for a different language. Many approaches to bilingual learning require that we have word-level alignment of sentences from parallel corpora. In this work we explore the use of autoencoder-based methods for cross-language learning of vectorial word representations that are aligned between two languages, while not relying on word-level alignments. We show that by simply learning to reconstruct the bag-of-words representations of aligned sentences, within and between languages, we can in fact learn high-quality representations and do without word alignments. Since training autoencoders on word observations presents certain computational issues, we propose and compare different variations adapted to this setting. We also propose an explicit correlation maximizing regularizer that leads to significant improvement in the performance. We empirically investigate the success of our approach on the problem of cross-language test classification, where a classifier trained on a given language (e.g., English) must learn to generalize to a different language (e.g., German). These experiments demonstrate that our approaches are competitive with the state-of-the-art, achieving up to 10-14 percentage point improvements over the best reported results on this task.