 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending RNN-T-based speech recognition systems with emotion and language classification
Jul 28, 2022
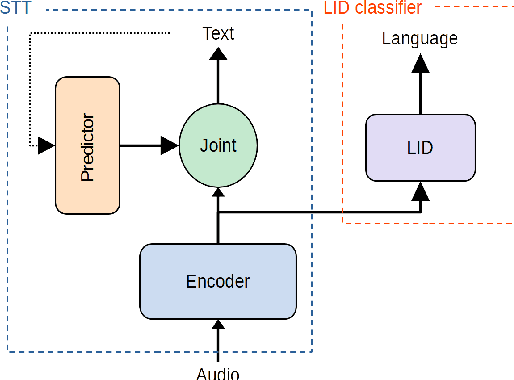
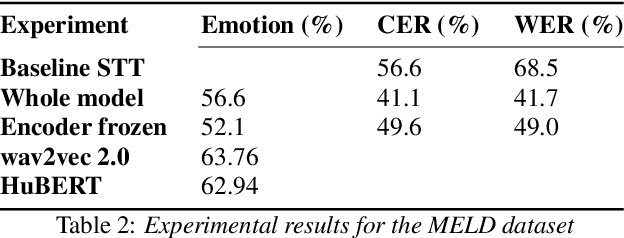
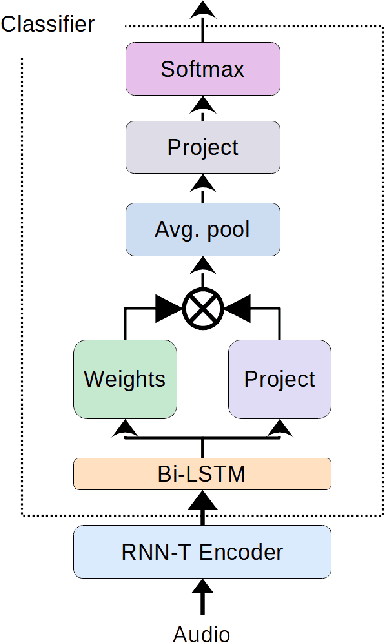
Speech transcription, emotion recognition, and language identification are usually considered to be three different tasks. Each one requires a different model with a different architecture and training process. We propose using a recurrent neural network transducer (RNN-T)-based speech-to-text (STT) system as a common component that can be used for emotion recognition and language identification as well as for speech recognition. Our work extends the STT system for emotion classification through minimal changes, and shows successful results on the IEMOCAP and MELD datasets. In addition, we demonstrate that by adding a lightweight component to the RNN-T module, it can also be used for language identification. In our evaluations, this new classifier demonstrates state-of-the-art accuracy for the NIST-LRE-07 dataset.
Speech Emotion Recognition using Self-Supervised Features
Feb 07, 2022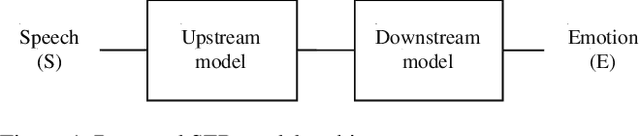
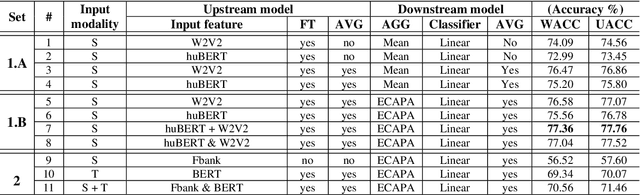
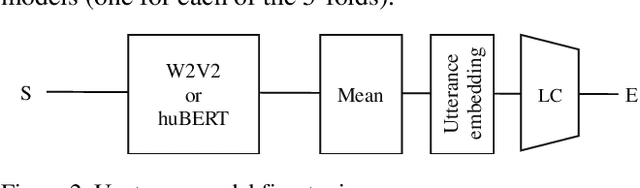
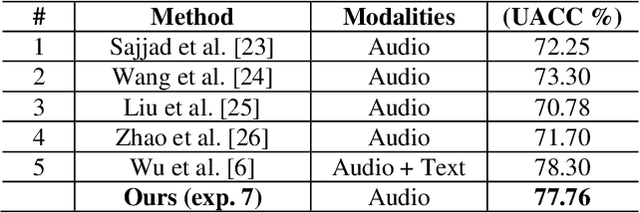
Self-supervised pre-trained features have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of speech emotion recognition (SER) still need further investigation. In this paper we introduce a modular End-to- End (E2E) SER system based on an Upstream + Downstream architecture paradigm, which allows easy use/integration of a large variety of self-supervised features. Several SER experiments for predicting categorical emotion classes from the IEMOCAP dataset are performed. These experiments investigate interactions among fine-tuning of self-supervised feature models, aggregation of frame-level features into utterance-level features and back-end classification networks. The proposed monomodal speechonly based system not only achieves SOTA results, but also brings light to the possibility of powerful and well finetuned self-supervised acoustic features that reach results similar to the results achieved by SOTA multimodal systems using both Speech and Text modalities.