 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Common Speech Analysis Engine
Mar 01, 2022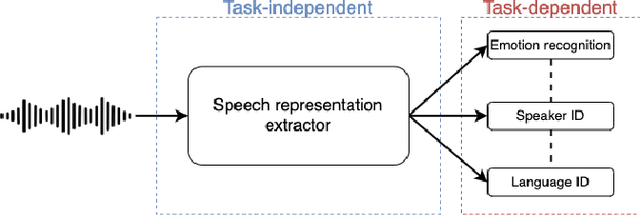
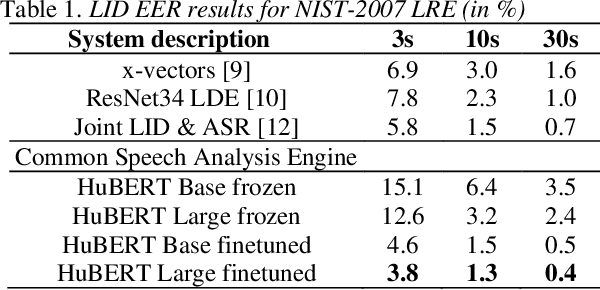


Recent innovations in self-supervised representation learning have led to remarkable advances in natural language processing. That said, in the speech processing domain, self-supervised representation learning-based systems are not yet considered state-of-the-art. We propose leveraging recent advances in self-supervised-based speech processing to create a common speech analysis engine. Such an engine should be able to handle multiple speech processing tasks, using a single architecture, to obtain state-of-the-art accuracy. The engine must also enable support for new tasks with small training datasets. Beyond that, a common engine should be capable of supporting distributed training with client in-house private data. We present the architecture for a common speech analysis engine based on the HuBERT self-supervised speech representation. Based on experiments, we report our results for language identification and emotion recognition on the standard evaluations NIST-LRE 07 and IEMOCAP. Our results surpass the state-of-the-art performance reported so far on these tasks. We also analyzed our engine on the emotion recognition task using reduced amounts of training data and show how to achieve improved results.
Speech Emotion Recognition using Self-Supervised Features
Feb 07, 2022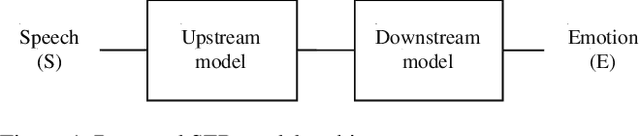
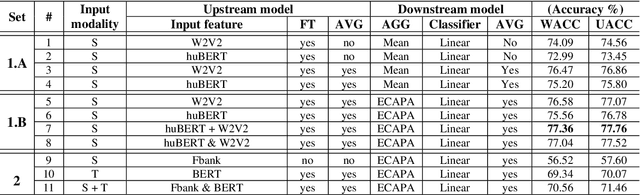
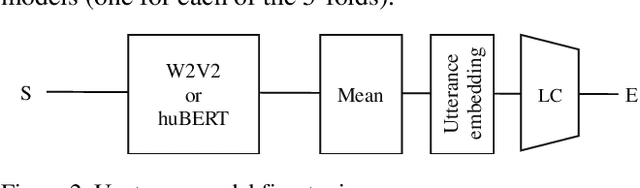
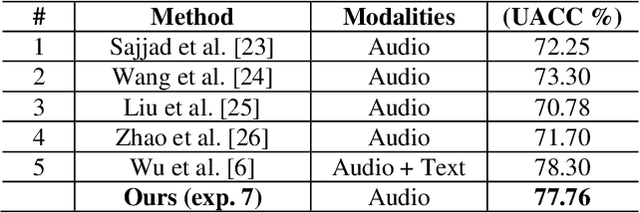
Self-supervised pre-trained features have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of speech emotion recognition (SER) still need further investigation. In this paper we introduce a modular End-to- End (E2E) SER system based on an Upstream + Downstream architecture paradigm, which allows easy use/integration of a large variety of self-supervised features. Several SER experiments for predicting categorical emotion classes from the IEMOCAP dataset are performed. These experiments investigate interactions among fine-tuning of self-supervised feature models, aggregation of frame-level features into utterance-level features and back-end classification networks. The proposed monomodal speechonly based system not only achieves SOTA results, but also brings light to the possibility of powerful and well finetuned self-supervised acoustic features that reach results similar to the results achieved by SOTA multimodal systems using both Speech and Text modalities.
Speaker Normalization for Self-supervised Speech Emotion Recognition
Feb 02, 2022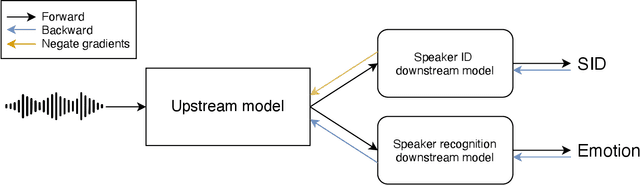
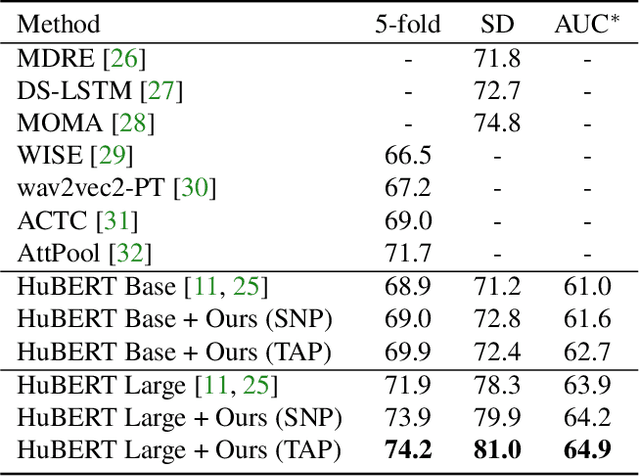
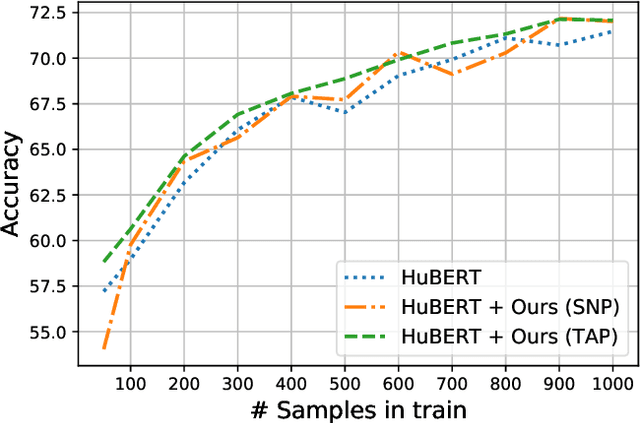
Large speech emotion recognition datasets are hard to obtain, and small datasets may contain biases. Deep-net-based classifiers, in turn, are prone to exploit those biases and find shortcuts such as speaker characteristics. These shortcuts usually harm a model's ability to generalize. To address this challenge, we propose a gradient-based adversary learning framework that learns a speech emotion recognition task while normalizing speaker characteristics from the feature representation. We demonstrate the efficacy of our method on both speaker-independent and speaker-dependent settings and obtain new state-of-the-art results on the challenging IEMOCAP dataset.