 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs
Apr 07, 2021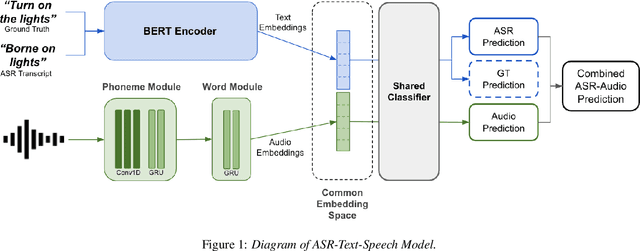
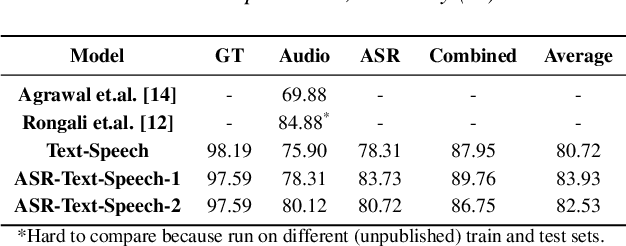
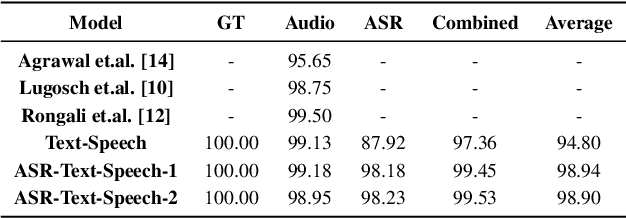
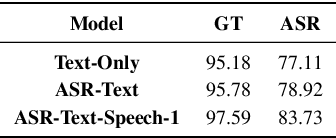
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.