 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Language Model Rescoring on Long-form Data
Jun 13, 2023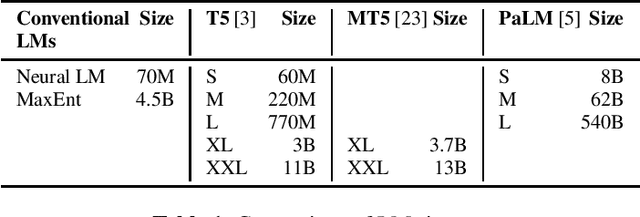
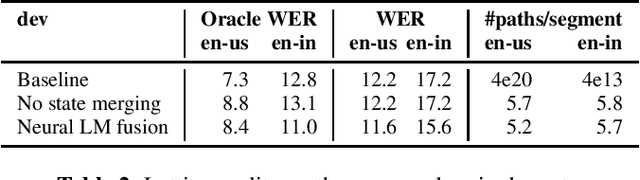


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Massively Multilingual Shallow Fusion with Large Language Models
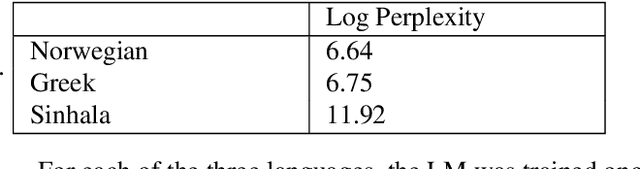
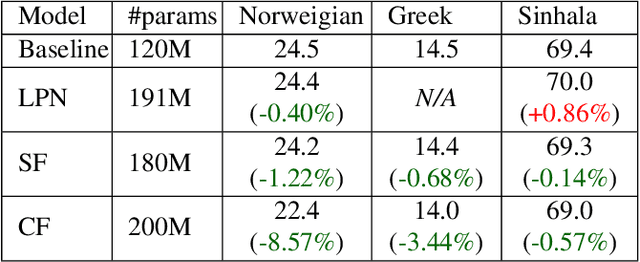
Feb 17, 2023While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.
Language model fusion for streaming end to end speech recognition
Apr 09, 2021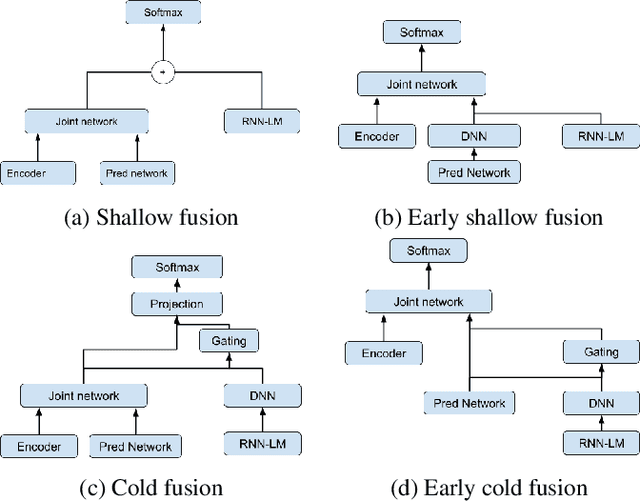
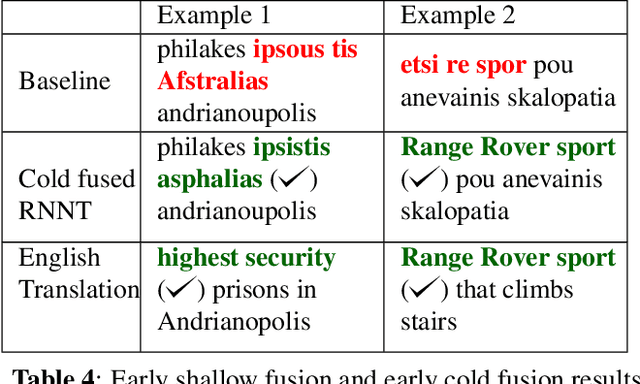
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.