 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage model fusion for streaming end to end speech recognition
Apr 09, 2021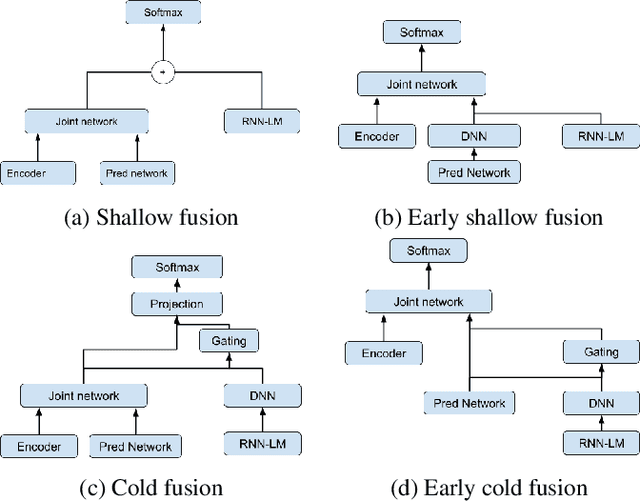
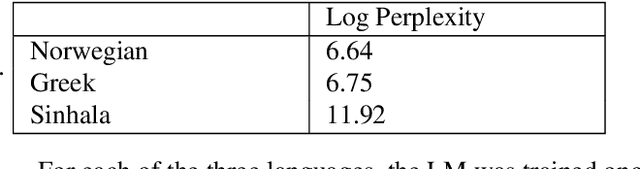
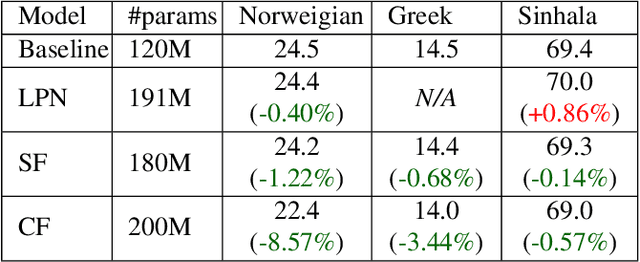
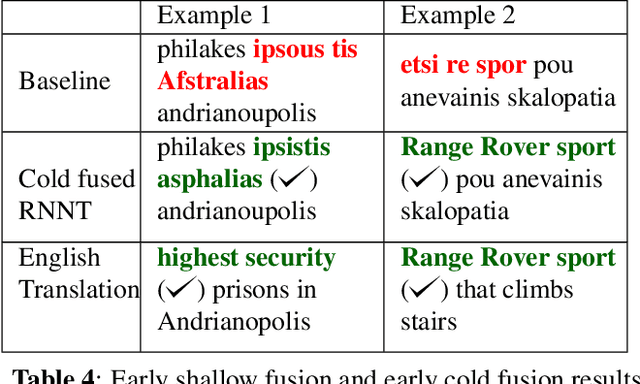
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.